深度优先搜索(DFS) 学习、Java代码实现
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了深度优先搜索(DFS) 学习、Java代码实现,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5113字,纯文字阅读大概需要8分钟。
内容图文
 学习、Java代码实现")
深度优先搜索(DFS) 的基本思想:从图中的某个顶点v出发,然后依次从未被访问的 v 的邻接点开始深度优先搜索,直至图中所有和 v 路径相同的顶点都被访问,然后选择另外一个没有被访问的顶点开始深度优先搜索。
1. 概述
深度优先搜索(DFS) 的基本思想:从图中的某个顶点v出发,然后依次从未被访问的 v 的邻接点开始深度优先搜索,直至图中所有和 v 路径相同的顶点都被访问,然后选择另外一个没有被访问的顶点开始深度优先搜索。
时间复杂度:
(1)使用数组存储图,时间复杂度 O(n^2), n 为定点数。
(2)使用邻接表存储图,时间复杂度 O (n + e), e 为 边数。
举一个例子:下面这样的一个图。
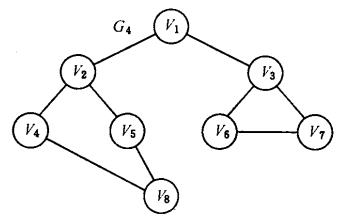
对这个图使用深度优先搜索去遍历。
我们使用 v1 作为第一个定点。
# 深度优先搜索 v1 ,v1 未被访问的邻接点为 v2 、v3。
### 深度优先搜索 v2 ,v2 未被访问的邻接点为 v4、 v5。
##### 深度优先搜索 v4 ,v4 未被访问的邻接点为 v8。
####### 深度优先搜索 v8 , v8没有未被访问的邻接点。
##### 深度优先搜索 v5,v5 没有未被访问的邻接点。
### 深度优先搜索 v3,v3 未被访问的邻接点为 v6、v7。
##### 深度优先搜索 v6,v6没有未被访问的邻接点。
##### 深度优先搜索 v7,v7 没有未被访问的邻接点。
深搜遍历顺序 v1 --> v2 --> v4 --> v8 --> v5 --> v3 --> v6 --> v7。
2. 代码实现
代码实现用的 邻接表,时间复杂度 O (n + e), n 为定点数 , e 为 边数。
package dfs;
import org.omg.PortableInterceptor.INACTIVE;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* @Author syrdbt
* @Date 2019/7/12 21:02
*/
public class MyDFSStudy {
public List<Integer>[] map; // 存储图
public boolean vis[]; // vis
public MyDFSStudy(List<Integer>[] map, int n) {
this.map = map;
vis = new boolean[n];
}
public void dfs(int i) {
System.out.print(" " + i + "-->");
vis[i] = true;
// 遍历邻接点
for (int j=0; j<map[i].size(); j++) {
//System.out.println(map[i].get(j));
if (vis[map[i].get(j)] == false) {
this.dfs(map[i].get(j));
}
}
}
public static void main(String[] args) {
ArrayList<Integer> []input = new ArrayList[9];
for (int i=0; i<9; i++) {
input[i] = new ArrayList<>();
}
input[1].add(2);
input[2].add(1);
input[1].add(3);
input[3].add(1);
input[2].add(4);
input[4].add(2);
input[2].add(5);
input[5].add(2);
input[3].add(6);
input[6].add(3);
input[3].add(7);
input[7].add(3);
input[4].add(8);
input[8].add(4);
input[5].add(8);
input[8].add(5);
input[6].add(7);
input[7].add(6);
MyDFSStudy myDFSStudy = new MyDFSStudy(input, 9);
myDFSStudy.dfs(1);
}
}
运行截图:

3. OJ 题: 1241 Oil Deposits
|
Problem Description The GeoSurvComp geologic survey company is responsible for detecting underground oil deposits. GeoSurvComp works with one large rectangular region of land at a time, and creates a grid that divides the land into numerous square plots. It then analyzes each plot separately, using sensing equipment to determine whether or not the plot contains oil. A plot containing oil is called a pocket. If two pockets are adjacent, then they are part of the same oil deposit. Oil deposits can be quite large and may contain numerous pockets. Your job is to determine how many different oil deposits are contained in a grid. Input The input file contains one or more grids. Each grid begins with a line containing m and n, the number of rows and columns in the grid, separated by a single space. If m = 0 it signals the end of the input; otherwise 1 <= m <= 100 and 1 <= n <= 100. Following this are m lines of n characters each (not counting the end-of-line characters). Each character corresponds to one plot, and is either `*', representing the absence of oil, or `@', representing an oil pocket. Output For each grid, output the number of distinct oil deposits. Two different pockets are part of the same oil deposit if they are adjacent horizontally, vertically, or diagonally. An oil deposit will not contain more than 100 pockets. Sample Input
Sample Output
|
思路:深搜求联通块。
参考代码:
import java.util.Scanner;
/**
* @Author syrdbt
* @Date 2019/7/12 17:36
*/
public class Main {
public char a[][]; //
public int road[][] = {{-1, -1, -1, 0, 0, 1, 1, 1},
{-1, 0, 1, -1, 1, -1, 0, 1}}; //8个方位
public boolean vis[][];
int m, n;
public Main(char[][] a, int m, int n) {
this.a = a;
this.m = m;
this.n = n;
vis = new boolean[m][n];
}
public void dfsLtk(int nowI, int nowJ) {
vis[nowI][nowJ] = true;
// 遍历邻接点
for (int i=0; i<8; i++) {
int tempI = nowI+road[0][i];
int tempJ = nowJ+road[1][i];
if (judge(tempI, tempJ)) {
dfsLtk(tempI, tempJ);
}
}
}
public boolean judge(int i, int j) {
if (i >= 0 && i < m && j >=0 && j < n) {
if (vis[i][j] == false && a[i][j] == '@')
return true;
else
return false;
}
return false;
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int m, n;
while (true) {
m = scanner.nextInt();
n = scanner.nextInt();
if (m == 0 && n ==0) {
break;
}
char a[][] = new char[m][n];
for (int i=0; i<m; i++) {
String str = scanner.next();
for (int j=0; j<n; j++) {
a[i][j] = str.charAt(j);
// System.out.println(a[i][j]);
}
}
Main myDfsStudy = new Main(a, m, n);
int ans = 0;
for (int i=0; i<m; i++) {
for (int j=0; j<n; j++) {
if (myDfsStudy.a[i][j] == '@' && myDfsStudy.vis[i][j] == false) {
ans ++;
myDfsStudy.dfsLtk(i, j);
}
}
}
System.out.println(ans);
}
}
}
参考文献
- 数据结构 - 严蔚敏、吴伟民 - 清华大学出版社
内容总结
以上是互联网集市为您收集整理的深度优先搜索(DFS) 学习、Java代码实现全部内容,希望文章能够帮你解决深度优先搜索(DFS) 学习、Java代码实现所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。