首页 / 爬虫 / 基于python的批量网页爬虫
基于python的批量网页爬虫
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了基于python的批量网页爬虫,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2665字,纯文字阅读大概需要4分钟。
内容图文

在各个网站,较久远的天气信息基本需要付费购买,因此为了花费更少的代价,得到完整的信息,我们经常会对一个网站进行爬虫,这篇文章是我第一次爬虫的心得,因为是第一次进行爬虫,python程序运行时间较长,若有错误,请大佬指出。
爬取网站https://en.tutiempo.net/climate/ws-567780.html上昆明每月的平均天气信息。以昆明1942年7月为例,观测网站https://en.tutiempo.net/climate/07-1942/ws-567780.html,可以发现,绿色代表月份,蓝色代表年份,我们需要爬取的信息是1942年到2019年每月的信息。即https://en.tutiempo.net/climate/01-1942/ws-567780.html到https://en.tutiempo.net/climate/12-2019/ws-567780.html每个网页上图1红框内的信息。
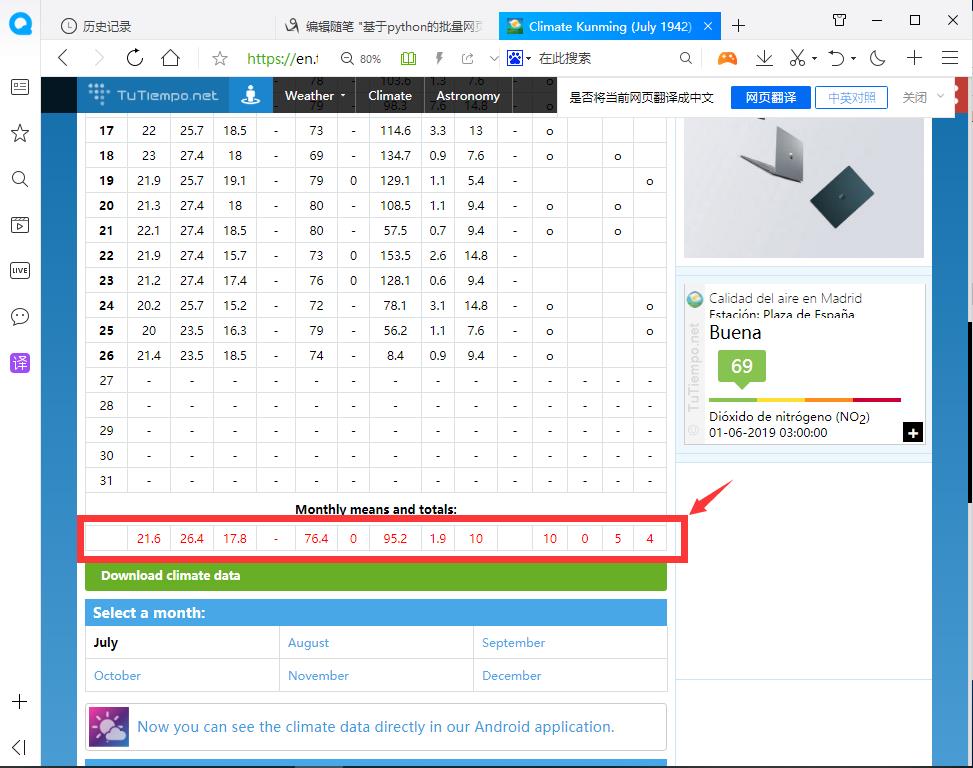
图1
F12观测网页结构如图2,找到该红框所对应的代码(html小白可以把鼠标放在代码上,出现的蓝筐即为该代码所构成的网页模块)。

图2
发现红框对应的网页代码如图3所示:

图3
因此构造python字符匹配代码:
'<td class="tc2">(.*)</td><td class="tc3">(.*)</td><td class="tc4">(.*)</td><td class="tc5">(.*)</td><td class="tc6">(.*)</td><td class="tc7">(.*)</td><td class="tc8">(.*)</td><td class="tc9">(.*)</td><td class="tc10">(.*)</td><td> </td><td>(.*)</td><td>(.*)</td><td>(.*)</td><td>(.*)</td>'
构造出的整体python代码如下:
import requests
import re
from xlwt import *
book = Workbook(encoding='utf-8')
sheet = book.add_sheet('Sheet1') #创建一个sheet
for j in range(78):
# 一共78年
for k in range(12):
# 一共12个月
print(j,k)
try:
# 匹配字符串
word2 = '<td class="tc2">(.*)</td><td class="tc3">(.*)</td><td class="tc4">(.*)</td><td class="tc5">(.*)</td><td class="tc6">(.*)</td><td class="tc7">(.*)</td><td class="tc8">(.*)</td><td class="tc9">(.*)</td><td class="tc10">(.*)</td><td> </td><td>(.*)</td><td>(.*)</td><td>(.*)</td><td>(.*)</td>'
# 在1到9月前面加个0
if(k<9):
url = "https://en.tutiempo.net/climate/0{}-{}/ws-567780.html".format(k + 1, j + 1942)
else:
url = "https://en.tutiempo.net/climate/{}-{}/ws-567780.html".format(k + 1, j + 1942)
f = requests.get(url) # Get该网页从而获取该html内容
str = f.content.decode()
# 返回查找到的数据
wordlist2 = re.findall(re.compile(word2), str)
for i in range(13):
# 将数据存入book中
print(wordlist2[0][i])
a = j*12+k
sheet.write(a, i, label=wordlist2[0][i])
except:
print()
# 将book保存到表格里
book.save("weather.xls")
运行后得到的excel表格见图5,经过ctrl+F进行字符替换和excel表的数据-分列-完成操作后,得到表格见图6,进行一些修饰,见图7表格。

图5

图6

图7
最后,本篇文章乃作者原创,禁止将本篇文章内容用于商业用途,若需转载请标明出处。
内容总结
以上是互联网集市为您收集整理的基于python的批量网页爬虫全部内容,希望文章能够帮你解决基于python的批量网页爬虫所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。