Java对象序列化为什么要使用SerialversionUID
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Java对象序列化为什么要使用SerialversionUID,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3904字,纯文字阅读大概需要6分钟。
内容图文

1. 什么是序列化?
对象 --》 字节序列 为序列化
字节序列 -》对象 为反序列化
2.为什么要序列化?
用途1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中
用途2)在网络上传送对象的字节序列
在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有 10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象
3.为什么要使用serialversionUID?
简单看一下 Serializable接口的说明
If a serializable class does not explicitly declare a serialVersionUID, then the serialization runtime will calculate a default serialVersionUID value for that class based on various aspects of the class, as described in the Java(TM) Object Serialization Specification.
如果用户没有自己声明一个serialVersionUID,接口会默认生成一个serialVersionUID
However, it is stronglyrecommended that all serializable classes explicitly declareserialVersionUID values, since the default serialVersionUID computation is highly sensitive to class details that may vary depending on compiler implementations, and can thus result in unexpectedInvalidClassExceptions during deserialization.
但是强烈建议用户自定义一个serialVersionUID,因为默认的serialVersinUID对于class的细节非常敏感,反序列化时可能会导致InvalidClassException这个异常。
e.g:1.使用默认的serialVersionUID
我们先建一个实体类Person 实现Serializable接口
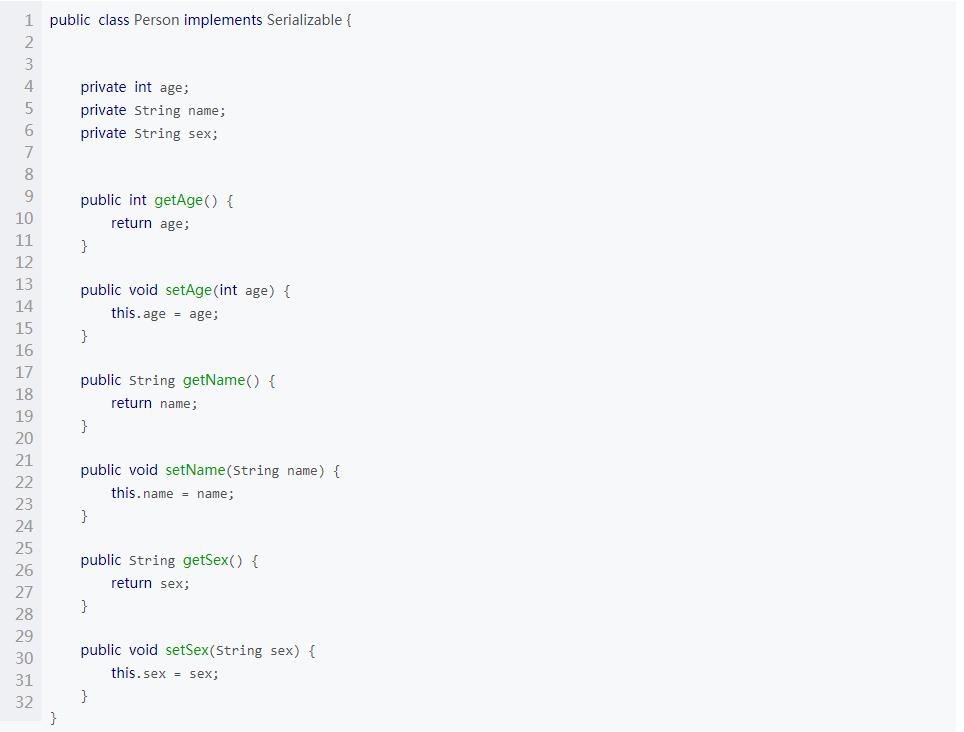
然后去序列化和反序列化它
public class TestPersonSerialize {
public static void main(String[] args) throws Exception {
serializePerson();
Person p = deserializePerson();
System.out.println(p.getName()+";"+p.getAge());
}
private static void serializePerson() throws FileNotFoundException,IOException {
Person person = new Person();
person.setName("测试实例");
person.setAge(25);
person.setSex("male");
ObjectOutputStream oo = new ObjectOutputStream(new FileOutputStream(
new File("E:/person.txt")));
oo.writeObject(person);
System.out.println("序列化成功");
oo.close();
}
private static Person deserializePerson() throws IOException, Exception {
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(new File("E:/person.txt")));
Person person = (Person) ois.readObject();
System.out.println("反序列化成功");
return person;
}
}
结果如图
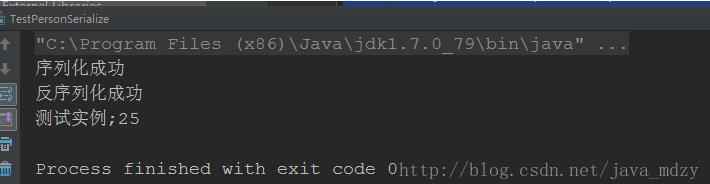
如果我们先尽心序列化,然后在反序列化之前修改了Person类会怎样呢
运行结果

可以看到,当我们修改Person类的时候,Person类对应的SerialversionUID也变化了,而序列化和反序列化就是通过对比其SerialversionUID来进行的,一旦SerialversionUID不匹配,反序列化就无法成功。在实际的生产环境中,我们可能会建一系列的中间Object来反序列化我们的pojo,为了解决这个问题,我们就需要在实体类中自定义SerialversionUID。
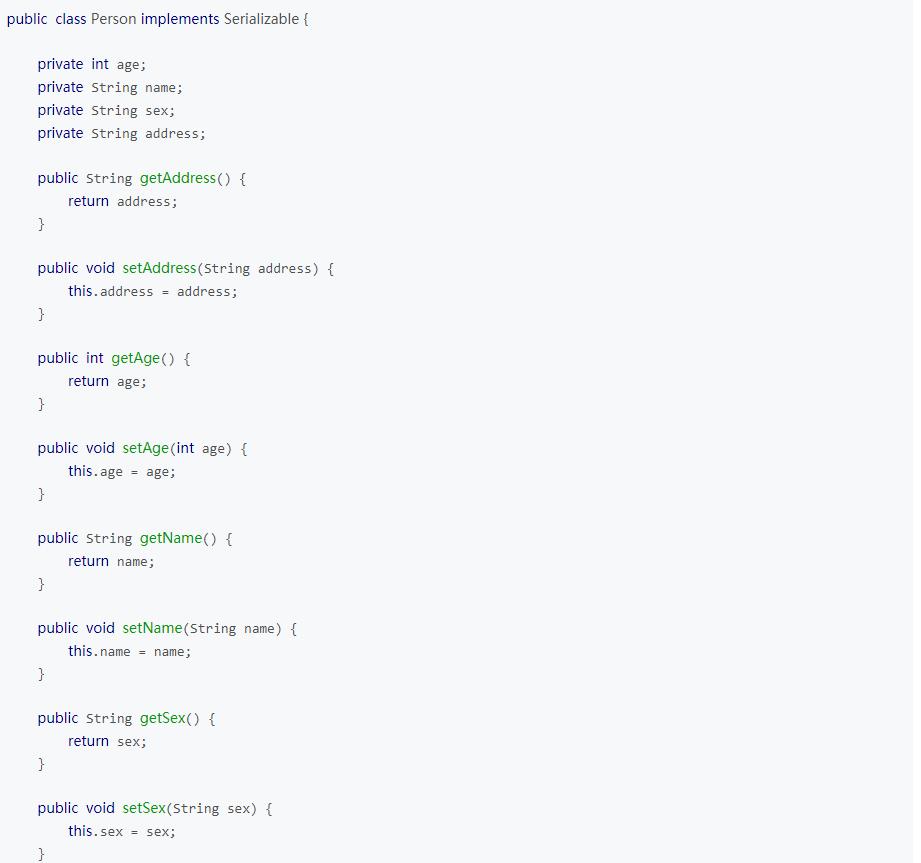
e.g:3 在Person类中加入自定义SerialversionUID
public class Person implements Serializable {
private static final long serialVersionUID = -5809782578272943999L;
private int age;
private String name;
private String sex;
private String address;
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}
不管我们序列化之后如何更改我们的Person(不删除原有字段),最终都可以反序列化成功。
内容总结
以上是互联网集市为您收集整理的Java对象序列化为什么要使用SerialversionUID全部内容,希望文章能够帮你解决Java对象序列化为什么要使用SerialversionUID所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。