python爬虫从企查查获取企业信息-手工绕开企查查的登录验证
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python爬虫从企查查获取企业信息-手工绕开企查查的登录验证,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3464字,纯文字阅读大概需要5分钟。
内容图文

想要从企查查爬取企业信息,如果没有登录直接检索,邮箱、电话都被隐藏了:
上面的图片是之前截的图,今天再次检索,好像又可见了:

不过单击查看详情时,还是会被隐藏:

不管怎么说,只要企查查想限制登录,总会出现这样那样的问题。只有登录,才能彻底避免此类问题。
爬虫想要登录,如果与网站上的验证码正面硬刚,可能会比较麻烦,
首先要拖动滑块:
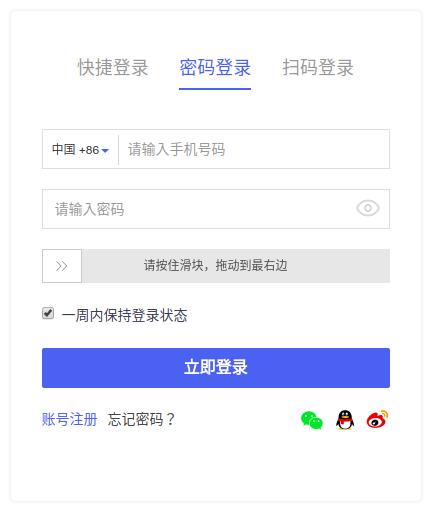
然后还要输入验证码:
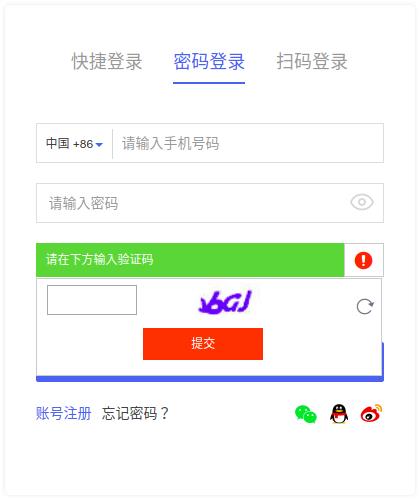
可能有些手段能够解决,但是今天我们来讲一个更加简单的方法。
思想:selenium库+chrome插件可以模拟人为操作浏览器的过程,是否能够在打开某个网页后让程序休眠一会,人为进行一些操作后,再由程序继续执行相应的操作呢?答案是:可以。
话不多说,上代码:
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import xlwt
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#伪装成浏览器,防止被识破
option = webdriver.ChromeOptions()
option.add_argument('--user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"')
driver = webdriver.Chrome(chrome_options=option)
#打开登录页面
driver.get('https://www.qichacha.com/user_login')
#单击用户名密码登录的标签
tag = driver.find_element_by_xpath('//*[@id="normalLogin"]')
tag.click()
#将用户名、密码注入
driver.find_element_by_id('nameNormal').send_keys('username')
driver.find_element_by_id('pwdNormal').send_keys('passwd')
time.sleep(10)#休眠,人工完成验证步骤,等待程序单击“登录”
#单击登录按钮
btn = driver.find_element_by_xpath('//*[@id="user_login_normal"]/button')
btn.click()
inc_list = ['阿里巴巴','腾讯','今日头条','滴滴','美团']
inc_len = len(inc_list)
for i in range(inc_len):
txt = inc_list[i]
time.sleep(1)
if (i==0):
#向搜索框注入文字
txt=txt.decode('utf-8')
driver.find_element_by_id('searchkey').send_keys(txt)
#单击搜索按钮
srh_btn = driver.find_element_by_xpath('//*[@id="V3_Search_bt"]')
srh_btn.click()
else:
#向搜索框注入下一个公司地址
txt=txt.decode('utf-8')
driver.find_element_by_id('headerKey').send_keys(txt)
#搜索按钮
srh_btn = driver.find_element_by_xpath('/html/body/header/div/form/div/div/span/button')
srh_btn.click()
#获取首个企业文本
print(i+1)
inc_full = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/a').text
print(inc_full)
money = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[1]/span[1]').text
print(money)
date = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[1]/span[2]').text
print(date)
mail_phone = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[2]').text
print(mail_phone)
addr = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[3]').text
print(addr)
try:
stock_or_others = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/p[4]').text
print(stock_or_others)
except:
pass
#获取网页地址,进入
inner = driver.find_element_by_xpath('//*[@id="search-result"]/tr[1]/td[3]/a').get_attribute("href")
driver.get(inner)
#单击进入后 官网 通过href属性获得:
inc_web = driver.find_element_by_xpath('//*[@id="company-top"]/div[2]/div[2]/div[3]/div[1]/span[3]/a').get_attribute("href")
print("官网:"+inc_web)
print(' ')
driver.close()
#bug list:
#UnicodeDecodeError: 'utf8' codec can't decode byte 0xe9 in position 0: unexpected end of data
#原因:向搜索栏注入中文字符串时,必须先采用如下方式转换成utf-8编码
#解决:send_keys("阿里巴巴".decode('utf-8'))
单击可以下载源码
效果:

欢迎关注我的代码仓库 ?https://github.com/rock4you/
欢迎扫码关注公众号code4fun,更多技术贴等你来吐槽:

内容总结
以上是互联网集市为您收集整理的python爬虫从企查查获取企业信息-手工绕开企查查的登录验证全部内容,希望文章能够帮你解决python爬虫从企查查获取企业信息-手工绕开企查查的登录验证所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。