python利用beautifulsoup多页面爬虫
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python利用beautifulsoup多页面爬虫,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含512字,纯文字阅读大概需要1分钟。
内容图文

利用了beautifulsoup进行爬虫,解析网址分页面爬虫并存入文本文档:
结果:
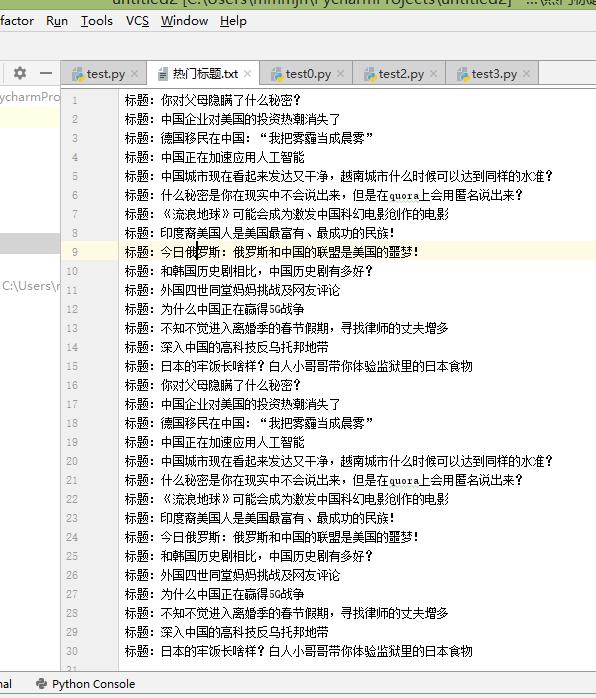
源码:
from bs4 import BeautifulSoup
from urllib.request import urlopen
with open("热门标题.txt","a",encoding="utf-8") as f:
for i in range(2):
url = "http://www.ltaaa.com/wtfy-{}".format(i)+".html"
html = urlopen(url).read()
soup = BeautifulSoup(html,"html.parser")
titles = soup.select("div[class = 'dtop' ] a") # CSS 选择器
for title in titles:
print(title.get_text(),title.get('href'))# 标签体、标签属性
f.write("标题:{}\n".format(title.get_text()))
内容总结
以上是互联网集市为您收集整理的python利用beautifulsoup多页面爬虫全部内容,希望文章能够帮你解决python利用beautifulsoup多页面爬虫所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】