Javascript 获取文档元素
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Javascript 获取文档元素,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1828字,纯文字阅读大概需要3分钟。
内容图文

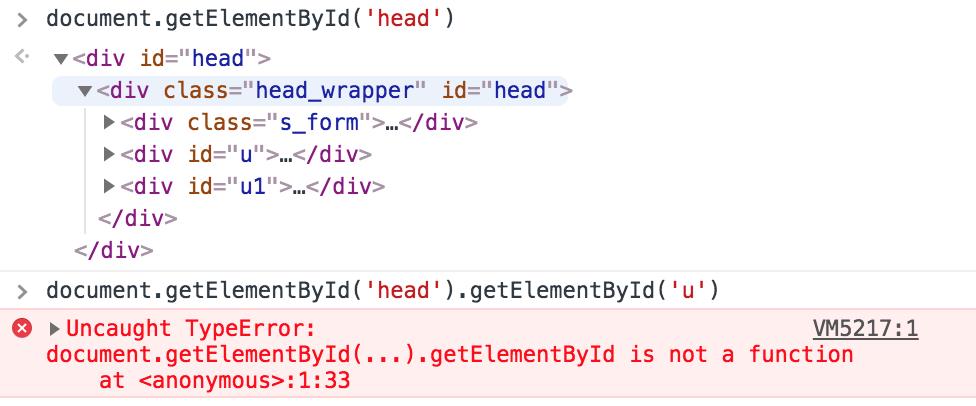
一、getElementById()
参数:id 属性,必须唯一。
返回:元素本身。若 id 不唯一,则返回第一个匹配的元素。
定义的位置:仅 document(即:除 document 之外的元素调用该方法,会报 is not a function)。
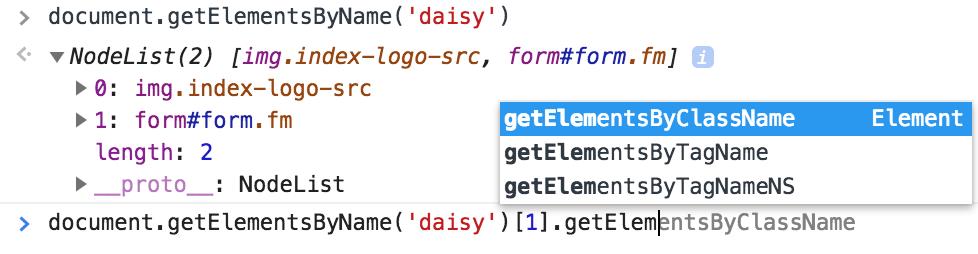
二、getElementsByName()
参数:name 属性,不必唯一。
返回:NodeList 对象。
定义的位置:仅 document。
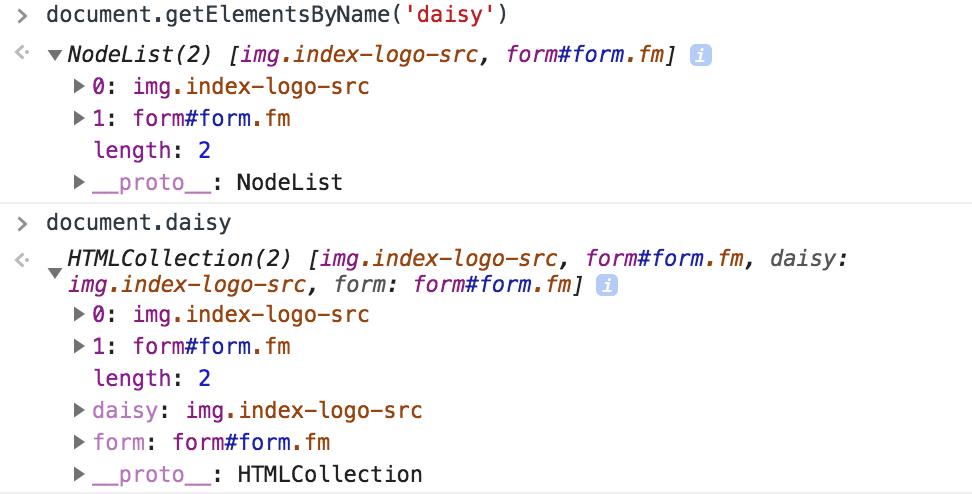
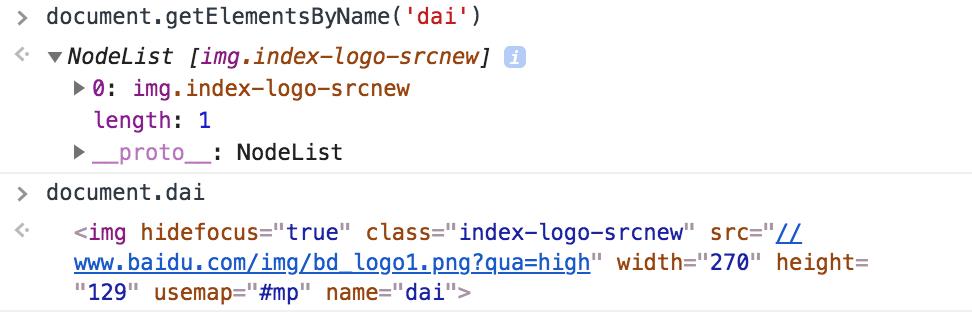
彩蛋:对于 <form>、<img>、<ifram>,当且仅当为上述元素设置 name 属性的时候,Window 对象会自动创建一个对应的属性,并可通过 document.name 来获取。若 name 仅匹配上一个元素,则返回元素本身,若匹配上多个元素,则返回 HTMLCollection 对象。
三、document.getElementsByTagName()
参数:1、HTML 元素,不必唯一,不区分大小写。
2、* , 匹配所有元素。
返回:HTMLCollection 对象。
定义的位置:document 和 element(即:可以在任意元素下调用该方法,获取指定元素的后代元素)。

彩蛋:对于 <form>、<img>、<a>,可通过 document.forms/.images/.links 来获取元素,返回 HTMLCollection 对象。并包含通过 name/id 索引的方法。

四、getElementsByClassName()
参数:1、字符串参数,不必唯一。
2、若需多个 className 匹配,使用空格分隔每个 class 。
3、若文档开头对<!DOCTYPE>声明选择的是‘怪异模式’渲染,则 className 不区分大小写,若选择的是‘严格模式’渲染,则需区分大小写。
返回:HTMLCollection 对象。
定义的位置:document 和 element。
五、querySelectorAll()
参数:css 选择器的字符串参数(ID:#、class:.、tag:div、属性:p[name=x]、文档结构:ul>li:first-child、获取多个元素:div, #log)。
返回:1、返回选择器匹配的所有元素的 NodeList 对象。
2、没有匹配的元素,返回 空的 NodeList 对象。
3、选择器字符串非法,抛出异常。
定义的位置:document 和 element。

彩蛋:JQuery 库中 css 选择器使用了一个与 querySelectorAll() 等效的方法,命名为 $()。
六、querySelector()
参数:css 选择器的字符串参数(ID:#、class:.、tag:div、属性:p[name=x]、文档结构:ul>li:first-child、获取多个元素:div, #log)。
返回:1、返回选择器匹配的第一个元素本身。
2、没有匹配的元素,返回 null。
定义的位置:document 和 element。

内容总结
以上是互联网集市为您收集整理的Javascript 获取文档元素全部内容,希望文章能够帮你解决Javascript 获取文档元素所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。