九章算法笔记 4.宽度优先搜索 Breadth First Search
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了九章算法笔记 4.宽度优先搜索 Breadth First Search,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含11769字,纯文字阅读大概需要17分钟。
内容图文

算法与题型 cs3k.com
- DFS: 用于搜索, 题目中有ALL字样
- 二分法: 用于时间复杂度小于O(n)的情况
- 分治法: 二叉树问题, 子问题和父问题有关系
- BFS:- 二叉树上的宽搜- 图上的宽搜: 拓扑排序- 棋盘上的宽搜
什么时候应该用BFS?
- 图的遍历 Traversal in Graph:
– 层级遍历 Level Order Traversal: 有先碰到后碰到的问题, 分距离远近
– 由点及面 Connected Component: 联通问题, 比如Smallest Rectangle Enclosing Black Pixels这道题就可以用灌水法做: 二分法O(Row * logCol + Col * LogRow), 灌水法O(R * C)- 拓扑排序 Topological Sorting: 有向图********pic4.2 - 最短路径 Shortest Path in Simple Graph
– 仅限简单图求最短路径(图中每条边长度都是1,且没有方向)
– ps: 如果问最长的路径呢? 用DP或者dfs所有路径找一遍
Binary Tree Level Order Traversal
cs3k.com
VECTOR用ARRAY来实现:
开一个n的区间, 指针指向开头; 不够的时候, 再开一个2n的区间, 把指针挪过来.
用循环数组实现先进先出的队列:
FIFO队列包含两个基本操作:插入(put)一个新的项,删除(get)一个最早插入的项。
循环数组实现方式:
对于每一个队列数据结构,我们保留一个数组S,其最多存放的Nmax个元素,定义两个位置front和rear分别指向队列的头尾两端,此外我们用N来记录队列中实际存在的元素 的个数。
对于一个元素item入队,我们让N和rear增1,然后置s[rear]=item;
对于一个元素item入队,我们让N减1,让front增1.
注意:这种实现有一个潜在的问题。假设数组的Nmax=10,经过10次入队后,队列似乎已经满了,因为此时rear=9.然而,队列中可能只存在小于9个的元素,因为 之前入队的操作可能伴随着出队的操作。例如我们将1,2,3,4,5,6,7,8,9,10一次入队,然后又进行2次出队操作,此时front指向数组元素S[2]处的位置,此时队列中只 有8个元素,这时rear仍然指向数组的最后一个元素S[Nmax-1]的位置,此时我们有没有办法继续进行入队操作呢?
简单的解决方法是:只要front和rear到达数组的末尾,它就又绕回到开头,这种实现方式就是循环数组的实现。这样队列的操作就局限在所定义的数组这块存储空间内。
STACK SYNTAX:
push, pop, top

QUEUE SYNTAX
push, pop,front,back

这道题的实现:
Given a binary tree, return the level order traversal of its nodes’ values. (ie, from left to right, level by level).

- 模板一般是一个while大循环之后一个for小循环.
- 31行为什么要先取出queue的size呢?因为for循环里面的检查条件, 每次都执行一遍, 不是开始多大就多大.
- 一般不能用stack, 因为同一层的节点会反过来.
stack: DFS
queue: BFS - 分层遍历比不分层遍历多一个for循环
- 时空复杂度都是O(n), ps:一般二叉树问题的时空复杂度都是O(n).
一般时间复杂度都是看最里面的循环体进出了多少次,这道题的while和for循环的最坏情况都是n次,但是时间复杂度不是n*n,是因为最坏的情况不能同时发生.
Binary Tree Serialization
cs3k.com
什么是序列化?
将“内存”中结构化的数据变成“字符串”的过程
序列化:object to string
反序列化:string to object
什么时候需要序列化?
- 将内存中的数据持久化存储时内存中重要的数据不能只是呆在内存里,这样断电就没有了,所需需要用一种方式写入硬盘,在需要的时候,能否再从硬盘中读出来在内存中重新创建
- 网络传输时机器与机器之间交换数据的时候,不可能互相去读对方的内存。只能讲数据变成字符流数据(字符串)后常用的一些序列化手段:XMLJson是个hash map,key是string, value是list/int或另一个hash map
Thrift (by Facebook)
ProtoBuf (by Google)
一些序列化的例子:
- 比如一个数组,里面都是整数,我们可以简单的序列化为”[1,2,3]”
- 一个整数链表,我们可以序列化为,”1->2->3”
- 一个哈希表(HashMap),我们可以序列化为,”{\”key\”: \”value\”}”
序列化算法设计时需要考虑的因素:
- 压缩率。对于网络传输和磁盘存储而言,当然希望更节省如 Thrift, ProtoBuf 都是为了更快的传输数据和节省存储空间而设计的
- 可读性。我们希望开发人员,能够通过序列化后的数据直接看懂原始数据是什么如 Json,LintCode 的输入数据
二叉树如何序列化?
? 你可以使用任何方式进行序列化, bfs,dfs, 前中后序都行,只要serialization之后unserialization回来的一样就可以. ?Binary Tree Serialization
cs3k.com
Design an algorithm and write code to serialize and deserialize a binary tree. Writing the tree to a file is called ‘serialization’ and reading back from the file to reconstruct the exact same binary tree is ‘deserialization’. ?Example
An example of testdata: Binary tree {3,9,20,#,#,15,7}, denote the following structure:
3
/ \
9 20
/ \
15 7
class Solution {
/**
* This method will be invoked first, you should design your own algorithm
* to serialize a binary tree which denote by a root node to a string which
* can be easily deserialized by your own "deserialize" method later.
*/
public String serialize(TreeNode root) {
if (root == null) {
return "{}";
}
ArrayList<TreeNode> queue = new ArrayList<TreeNode>();
queue.add(root);
for (int i = 0; i < queue.size(); i++) {
TreeNode node = queue.get(i);
if (node == null) {
continue;
}
queue.add(node.left);
queue.add(node.right);
}
while (queue.get(queue.size() - 1) == null) {
queue.remove(queue.size() - 1);
}
StringBuilder sb = new StringBuilder();
sb.append("{");
sb.append(queue.get(0).val);
for (int i = 1; i < queue.size(); i++) {
if (queue.get(i) == null) {
sb.append(",#");
} else {
sb.append(",");
sb.append(queue.get(i).val);
}
}
sb.append("}");
return sb.toString();
}
/**
* This method will be invoked second, the argument data is what exactly
* you serialized at method "serialize", that means the data is not given by
* system, it's given by your own serialize method. So the format of data is
* designed by yourself, and deserialize it here as you serialize it in
* "serialize" method.
*/
public TreeNode deserialize(String data) {
if (data.equals("{}")) {
return null;
}
String[] vals = data.substring(1, data.length() - 1).split(",");
ArrayList<TreeNode> queue = new ArrayList<TreeNode>();
TreeNode root = new TreeNode(Integer.parseInt(vals[0]));
queue.add(root);
int index = 0;
boolean isLeftChild = true;
for (int i = 1; i < vals.length; i++) {
if (!vals[i].equals("#")) {
TreeNode node = new TreeNode(Integer.parseInt(vals[i]));
if (isLeftChild) {
queue.get(index).left = node;
} else {
queue.get(index).right = node;
}
queue.add(node);
}
if (!isLeftChild) {
index++;
}
isLeftChild = !isLeftChild;
}
return root;
}
}
图上的宽度优先搜索
cs3k.com
- 和树上的有什么区别?
– 图上可能有环 - 所以图上的需要个hash map或者一个hash set记录走没走过这个节点
Graph Valid Tree
Given n nodes labeled from 0 to n - 1 and a list of undirected edges (each edge is a pair of nodes), write a function to check whether these edges make up a valid tree.
一个graph是不是tree的决定条件有两个:
- 点比边个数多一个
- 所有点都要连通: 对于连通性问题, bfs是最好的方法之一.
public class Solution {
/**
* @param n an integer
* @param edges a list of undirected edges
* @return true if it's a valid tree, or false
*/
public boolean validTree(int n, int[][] edges) {
if (n == 0) {
return false;
}
if (edges.length != n - 1) {
return false;
}
Map<Integer, Set<Integer>> graph = initializeGraph(n, edges);
// bfs
Queue<Integer> queue = new LinkedList<>();
Set<Integer> hash = new HashSet<>();
queue.offer(0);
hash.add(0);
while (!queue.isEmpty()) {
int node = queue.poll();
for (Integer neighbor : graph.get(node)) {
if (hash.contains(neighbor)) {
continue;
}
hash.add(neighbor);
queue.offer(neighbor);
}
}
return (hash.size() == n);
}
private Map<Integer, Set<Integer>> initializeGraph(int n, int[][] edges) {
Map<Integer, Set<Integer>> graph = new HashMap<>();
for (int i = 0; i < n; i++) {
graph.put(i, new HashSet<Integer>());
}
for (int i = 0; i < edges.length; i++) {
int u = edges[i][0];
int v = edges[i][1];
graph.get(u).add(v);
graph.get(v).add(u);
}
return graph;
}
}
Clone Graph
cs3k.com
Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors.
How we serialize an undirected graph:
Nodes are labeled uniquely.
We use # as a separator for each node, and , as a separator for node label and each neighbor of the node.
As an example, consider the serialized graph {0,1,2#1,2#2,2}.
The graph has a total of three nodes, and therefore contains three parts as separated by #.
- First node is labeled as
0. Connect node0to both nodes1and2. - Second node is labeled as
1. Connect node1to node2. - Third node is labeled as
2. Connect node2to node2(itself), thus forming a self-cycle.
Visually, the graph looks like the following:
1
/ \
/ \
0 --- 2
/ \
\_/
public class Solution {
/**
* @param node: A undirected graph node
* @return: A undirected graph node
*/
public UndirectedGraphNode cloneGraph(UndirectedGraphNode node) {
if (node == null) {
return node;
}
// use bfs algorithm to traverse the graph and get all nodes.
ArrayList<UndirectedGraphNode> nodes = getNodes(node);
// copy nodes, store the old->new mapping information in a hash map
HashMap<UndirectedGraphNode, UndirectedGraphNode> mapping = new HashMap<>();
for (UndirectedGraphNode n : nodes) {
mapping.put(n, new UndirectedGraphNode(n.label));
}
// copy neighbors(edges)
for (UndirectedGraphNode n : nodes) {
UndirectedGraphNode newNode = mapping.get(n);
for (UndirectedGraphNode neighbor : n.neighbors) {
UndirectedGraphNode newNeighbor = mapping.get(neighbor);
newNode.neighbors.add(newNeighbor);
}
}
return mapping.get(node);
}
private ArrayList<UndirectedGraphNode> getNodes(UndirectedGraphNode node) {
Queue<UndirectedGraphNode> queue = new LinkedList<UndirectedGraphNode>();
HashSet<UndirectedGraphNode> set = new HashSet<>();
queue.offer(node);
set.add(node);
while (!queue.isEmpty()) {
UndirectedGraphNode head = queue.poll();
for (UndirectedGraphNode neighbor : head.neighbors) {
if(!set.contains(neighbor)){
set.add(neighbor);
queue.offer(neighbor);
}
}
}
return new ArrayList<UndirectedGraphNode>(set);
}
}
三步走:
- 通过一个点找到所有的点
- 克隆点, 即点变新的点
- 克隆边, 即边变新的边
劝分不劝合, 编程能分开的尽量分开写。
能用BFS, 一定不用DFS, 因为dfs有recursion, 容易stack over flow
Search Graph Nodes
cs3k.com
由点及面
不用做分层遍历
Given a undirected graph, a node and a target, return the nearest node to given node which value of it is target, return NULL if you can’t find.
There is a mapping store the nodes’ values in the given parameters.
It’s guaranteed there is only one available solution
Example
2------3 5
\ | |
\ | |
\ | |
\ | |
1 --4
Give a node 1, target is 50
there a hash named values which is [3,4,10,50,50], represent:
Value of node 1 is 3
Value of node 2 is 4
Value of node 3 is 10
Value of node 4 is 50
Value of node 5 is 50
Return node 4
public class Solution {
/**
* @param graph a list of Undirected graph node
* @param values a hash mapping, <UndirectedGraphNode, (int)value>
* @param node an Undirected graph node
* @param target an integer
* @return the a node
*/
public UndirectedGraphNode searchNode(ArrayList<UndirectedGraphNode> graph,
Map<UndirectedGraphNode, Integer> values,
UndirectedGraphNode node,
int target) {
// Write your code here
Queue<UndirectedGraphNode> queue = new LinkedList<UndirectedGraphNode>();
Set<UndirectedGraphNode> hash = new HashSet<UndirectedGraphNode>();
queue.offer(node);
hash.add(node);
while (!queue.isEmpty()) {
UndirectedGraphNode head = queue.poll();
if (values.get(head) == target) {
return head;
}
for (UndirectedGraphNode nei : head.neighbors) {
if (!hash.contains(nei)){
queue.offer(nei);
hash.add(nei);
}
}
}
return null;
}
}
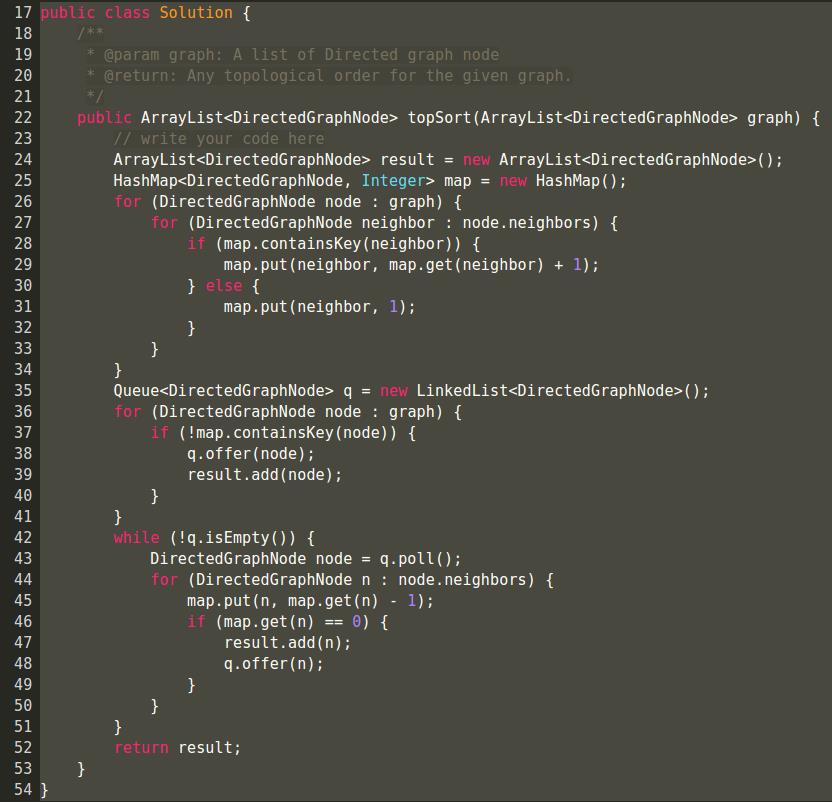
Topological Sorting
cs3k.com
-可以用DFS?
可以,但是不推荐
-应用场景
选课
编译:编译的时候用link的东西,所以要看看有没有循环依赖。
-关心能否进行拓扑排序, 即是关心有没有环
-入度: 指向一个节点的边的个数
Given an directed graph, a topological order of the graph nodes is defined as follow:
- For each directed edge
A -> Bin graph, A must before B in the order list. - The first node in the order can be any node in the graph with no nodes direct to it.
Find any topological order for the given graph.
? Example
For graph as follow:
The topological order can be:
[0, 1, 2, 3, 4, 5]
[0, 2, 3, 1, 5, 4]
...
Course Schedule
There are a total of n courses you have to take, labeled from 0 to n - 1.
Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: [0,1]
Given the total number of courses and a list of prerequisite pairs, is it possible for you to finish all courses?
Example
Given n = 2, prerequisites = [[1,0]]
Return true
Given n = 2, prerequisites = [[1,0],[0,1]]
Return false

内容总结
以上是互联网集市为您收集整理的九章算法笔记 4.宽度优先搜索 Breadth First Search全部内容,希望文章能够帮你解决九章算法笔记 4.宽度优先搜索 Breadth First Search所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。