趣味实战!Python爬虫爬取丁香园用户主页(第一节)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了趣味实战!Python爬虫爬取丁香园用户主页(第一节),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4651字,纯文字阅读大概需要7分钟。
内容图文
")
目录
0.写在前面
1.分析页面
2.获取页面源码
3.解析数据
4.数据存储及导出
4.1 数据存储
4.2 数据导出
5.pandas实现导出
6.面向对象封装
0.写在前面
目标页面
http://i.dxy.cn/profile/yilizhongzi
目的
爬取丁香园用户主页的信息,这些信息如下图字段:

爬取字段图
也就是从用户主页提取这些数据,那么我们开始实战!
1.分析页面

分析页面图
我们需要爬取的信息就是上述图中侧边栏信息,它对应的源码如图中红色方框所示!
思路
第一步:获取页面源码
第二步:通过xpath解析对应数据,并存储为字典格式
第三步:存储至MongoDB数据库,并利用可视化工具导出csv文件
第四步:存储至excel中(或csv文件)中
2.获取页面源码
def get_html(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
req = requests.get(self.url, headers=headers).text
# print(req)
return req3.解析数据
xpath解析方法
以下面实际例子为例:
谷歌浏览器右键检查,页面分析源码,找到如下图的div,然后会发现class="follows-fans clearfix"里面包含这三个关注、粉丝、丁当相关信息。
那么通过xpath解析即可获取到相应的数据。具体的xpath语法,请参看网上资料,此处不做详细解释。只对相应语句添加相应注释。认真看注释!!!

元素提取图
'''
满足class值的div下面的所有p标签的text()属性,因为上述第一个p标签下面还有a标签,所有这里直接取的就是关注/粉丝/丁当这些字符串,每个对应的值28/90/1128,通过进一步定位到a标签进行解析。参看第二行代码。
'''
force_fan_dd_key = selector.xpath('//div[@class="follows-fans clearfix"]//p/text()')
force_fan_dd_value = selector.xpath('//div[@class="follows-fans clearfix"]//p/a/text()')下面对获取用户信息进行封装
import requests
from lxml import etree
def get_UserInfo(self):
raw_html = self.get_html()
selector = etree.HTML(raw_html)
key_list = []
value_list = []
force_fan_dd_key = selector.xpath('//div[@class="follows-fans clearfix"]//p/text()')
force_fan_dd_value = selector.xpath('//div[@class="follows-fans clearfix"]//p/a/text()')
for each in force_fan_dd_key:
key_list.append(each)
for each in force_fan_dd_value:
value_list.append(each)
UserInfo_dict = dict(zip(key_list, value_list)) # 两个list合并为dict
# print(UserInfo_dict) # {'关注': '28', '粉丝': '90', '丁当': '1128'}
user_home = selector.xpath('//p[@class="details-wrap__items"]/text()')[0]
user_home = user_home.replace(',', '') # 去掉逗号,否则使用MongoDB可视化工具导出csv文件报错!
# print(user_home)
UserInfo_dict['地址'] = user_home
user_profile = selector.xpath('//p[@class="details-wrap__items details-wrap__last-item"]/text()')[0]
UserInfo_dict['座右铭'] = user_profile
# print(UserInfo_dict)
# 帖子被浏览
article_browser = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-topic fl"]/p/text()')
UserInfo_dict[article_browser[0]] = article_browser[1]
# 帖子被投票
article_vote = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-vote fl"]/p/text()')
UserInfo_dict[article_vote[0]] = article_vote[1]
# 帖子被收藏
article_collect = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-fav fl"]/p/text()')
UserInfo_dict[article_collect[0]] = article_collect[1]
# 在线时长共
onlie_time = selector.xpath('//li[@class="statistics-wrap__items statistics-wrap__item-time fl"]/p/text()')
UserInfo_dict[onlie_time[0]] = onlie_time[1]
# print(UserInfo_dict)
return UserInfo_dict4.数据存储及导出
4.1 数据存储
import pymongo MONGO_URI = 'localhost' MONGO_DB = 'test' # 定义数据库 MONGO_COLLECTION = 'dxy' # 定义数据库表 def __init__(self, user_id, mongo_uri, mongo_db): self.url = base_url + user_id # 这行代码与数据存储无关 self.client = pymongo.MongoClient(mongo_uri) self.db = self.client[mongo_db] def Save_MongoDB(self, userinfo): self.db[MONGO_COLLECTION].insert(userinfo) self.client.close()
MongoDB可视化工具:MongoDB Compass Community
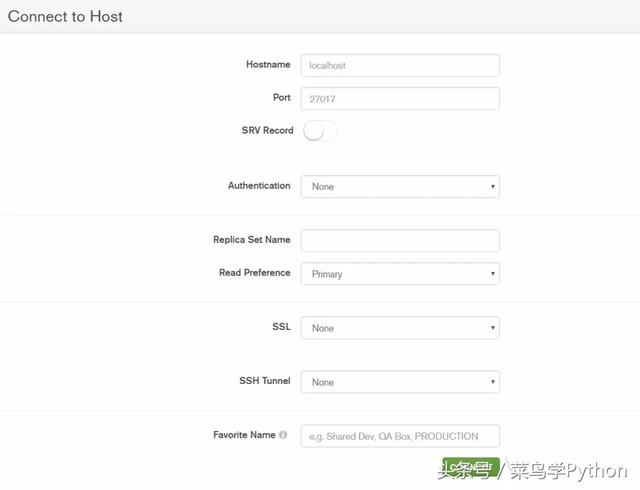
MongoDB可视化工具图
安装好后,每次打开会提示连接数据库,这里就是不变动任何信息,直接点CONNECT即可!
注意一个区别:Collection就是数据库的表!如下图就是test数据库中的dxy表。

MongoDB存储结果图
4.2 数据导出
选择左上角的Collection->Export Collection,然后弹出如下图的框,选择导出格式及存储文件路径,保存即可!

导出结果

MongoDB导出结果图
5.pandas实现导出
import pandas as pd
def Sava_Excel(self, userinfo):
key_list = []
value_list = []
for key, value in userinfo.items():
key_list.append(key)
value_list.append(value)
key_list.insert(0, '用户名') # 增加用户名列
value_list.insert(0, user) # 增加用户名
# 利用pandas进行导出
data = pd.DataFrame(data=[value_list], columns=key_list)
print(data)
'''
表示以用户名命名csv文件,并去掉DataFame序列化后的index列(这就是index=False的意思),并以utf-8编码,
防止中文乱码。
注意:一定要先用pandas的DataFrame序列化后,方可使用to_csv方法导出csv文件!
'''
data.to_csv('./' + user + '.csv', encoding='utf-8', index=False)6.面向对象封装
最后,采用面向对象思想对上述代码进行封装。
内容总结
以上是互联网集市为您收集整理的趣味实战!Python爬虫爬取丁香园用户主页(第一节)全部内容,希望文章能够帮你解决趣味实战!Python爬虫爬取丁香园用户主页(第一节)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。