首页 / 算法 / 基于用户的协同过滤算法
基于用户的协同过滤算法
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了基于用户的协同过滤算法,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2648字,纯文字阅读大概需要4分钟。
内容图文

一、协同过滤算法简介
协同过滤算法是一种较为著名和常用的推荐算法,它基于对用户历史行为数据的挖掘发现用户的喜好偏向,并预测用户可能喜好的产品进行推荐。也就是常见的“猜你喜欢”,和“购买了该商品的人也喜欢”等功能。它的主要实现由:
●根据和你有共同喜好的人给你推荐
●根据你喜欢的物品给你推荐相似物品
●根据以上条件综合推荐
因此可以得出常用的协同过滤算法分为两种,基于用户的协同过滤算法(user-based collaboratIve filtering),以及基于物品的协同过滤算法(item-based collaborative filtering)。特点可以概括为“人以类聚,物以群分”,并据此进行预测和推荐。
二、协同过滤算法的关键问题
实现协同过滤算法,可以概括为几个关键步骤:
1:根据历史数据收集用户偏好
2:找到相似的用户(基于用户)或物品(基于物品)
三、基于用户的协同过滤算法描述
基于用户的协同过滤算法的实现主要需要解决两个问题,一是如何找到和你有相似爱好的人,也就是要计算数据的相似度:
计算相似度需要根据数据特点的不同选择不同的相似度计算方法,有几个常用的计算方法:
(1)杰卡德相似系数(Jaccard similarity coefficient)
其实就是集合的交集除并集
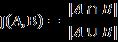
(2)夹角余弦(Cosine)
在二维空间中向量A(x1,y1)与向量B(x2,y2)的夹角余弦公式:
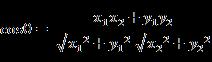
两个n维样本点a(x11,x12,…,x1n)和b(x21,x22,…,x2n)的夹角余弦:
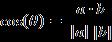
即 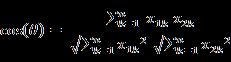
(3)其余方法,例如欧式距离、曼哈顿距离等相似性度量方法可以点此了解
找到与目标用户最相邻的K个用户
我们在寻找有有相同爱好的人的时候,可能会找到许多个,例如几百个人都喜欢A商品,但是这几百个人里,可能还有几十个人与你同时还喜欢B商品,他们的相似度就更高,我们通常设定一个数K,取计算相似度最高的K个人称为最相邻的K个用户,作为推荐的来源群体。
这里存在一个小问题,就是当用户数据量十分巨大的时候,在所有人之中找到K个基友花的时间可能会比较长,而且实际中大部分的用户是和你没有什么关系的,所以在这里需要用到反查表
所谓反查表,就是比如你喜欢的商品有A、B、C,那就分别以ABC为行名,列出喜欢这些商品的人都有哪些,其他的人就必定与你没有什么相似度了,从这些人里计算相似度,找到K个人
通过这K个人推荐商品
我们假设找到的人的喜好程度如下
| 你 | A | B | C | D |
| 甲(相似度25%) | √ | √ | √ | |
| 乙(相似度80%) | √ | √ |
那么对于产品ABCD,推荐度可以计算为:
●A:1*0.25=0.25
●B:1*0.25=0.25
●C:1*0.8=0.8
●D:1*0.25+1*0.8=1.05
很明显,我们首先会推荐D商品,其次是C商品,再后是其余商品
当然我们也可以采用其他的推荐度计算方法,但是我们一定会使用得到的相似度0.25和0.80,也即一定是进行加权的计算。
算法总结
这就是基于用户的协同推荐算法,总结步骤为
1.计算其他用户的相似度,可以使用反查表除掉一部分用户
2.根据相似度找到与你嘴相似的K个用户
3.在这些邻居喜欢的物品中,根据与你的相似度算出每一件物品的推荐度
4.根据相似度推荐物品
算法存在的问题
例如一段时间内非常流行的某种商品,或者某种通用的商品,购买的人非常多,此时如果列入正常计算过程中就没有太大意义了,并且会增加负担。可以给此种商品价一个权值或者在数据预处理阶段作为脏数据处理掉。
实战-待补
内容总结
以上是互联网集市为您收集整理的基于用户的协同过滤算法全部内容,希望文章能够帮你解决基于用户的协同过滤算法所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。