目前我正在使用com.crealytics.spark.excel来读取excel文件,但是使用这个库我无法将数据集写入excel文件.这个link说使用hadoop办公室库(org.zuinnote.spark.office.excel)我们可以读写excel文件
请帮我把数据集对象写入spark java中的excel文件.解决方法:您可以使用org.zuinnote.spark.office.excel来使用数据集读取和写入Excel文件.示例在https://github.com/ZuInnoTe/spark-hadoopoffice-ds/给出.但是,如果您在数据集中读取Excel...
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.*;
import scala.Tuple2;import java.net.URL;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Iterator;
import java.util.List;public class wordcount{public static ...
我的文本文件中包含以下行:Some different lines....Name : Praveen
Age : 24
Contact : 1234567890
Location : India Some different lines....Name : John
Contact : 1234567890
Location : UK Some different lines.... Name : Joe
Age : 54
Contact : 1234567890
Location : US 一些不同的行指示其间还有其他信息.
现在,我需要阅读文件并提取人员信息.如果缺少任何键,则应将其读取为空字符串(第二人称信息...
我想确保我正在对数据的分层样本进行培训.
似乎Spark 2.1和更早版本通过JavaPairRDD.sampleByKey(…)和JavaPairRDD.sampleByKeyExact(…)对此提供了支持,如here所述.
但是:我的数据存储在Dataset< Row>中,而不是JavaPairRDD中.第一列是标签,所有其他都是功能(从libsvm格式的文件导入).
获得我的数据集实例的分层样本的最简单方法是什么,最后有一个Dataset< Row>.再次?
在某种程度上,这个问题与Dealing with unbalanced datasets ...
我在Spark中遇到“任务无法序列化”错误.我已经搜索并尝试使用某些帖子中建议的静态函数,但是它仍然会给出相同的错误.
代码如下:public class Rating implements Serializable {private SparkSession spark;private SparkConf sparkConf;private JavaSparkContext jsc;private static Function<String, Rating> mapFunc;public Rating() {mapFunc = new Function<String, Rating>() {public Rating call(String str) {return Rati...
我是spark框架的新手.我试图使用spark和java创建一个示例应用程序.我有以下代码
的pom.xml<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.10</artifactId><version>1.6.1</version>
</dependency>资源import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;public class SparkTest {public static void main(String[] args) {SparkConf sparkConf = new SparkConf().setAppName("Ex...
在当前早期发布的名为High Performance Spark的教科书中,Spark的开发人员注意到:To allow Spark the flexibility to spill some recordsto disk, it is important to represent your functions inside of mapPartitions in such away that your functions don’t force loading the entire partition in-memory (e.g.implicitly converting to a list). Iterators have many methods we can write functional styletransformation...
我是新手,我想要使用group-by& reduce从CSV中找到以下内容(使用一行):Department, Designation, costToCompany, StateSales, Trainee, 12000, UPSales, Lead, 32000, APSales, Lead, 32000, LASales, Lead, 32000, TNSales, Lead, 32000, APSales, Lead, 32000, TN Sales, Lead, 32000, LASales, Lead, 32000, LAMarketing, Associate, 18000, TNMarketing, Associate, 18000, TNHR, Manager, 58000, TN我想通过Department,Design...
首先,感谢您抽出时间阅读我的问题.
我的问题如下:在Spark with Java中,我在两个数据帧中加载了两个csv文件的数据.
这些数据框将具有以下信息.
Dataframe机场Id | Name | City
-----------------------
1 | Barajas | MadridDataframe airport_city_stateCity | state
----------------
Madrid | Espa?a我想加入这两个数据帧,使它看起来像这样:
数据帧结果Id | Name | City | state
--------------------------
1 | Bar...
需求:
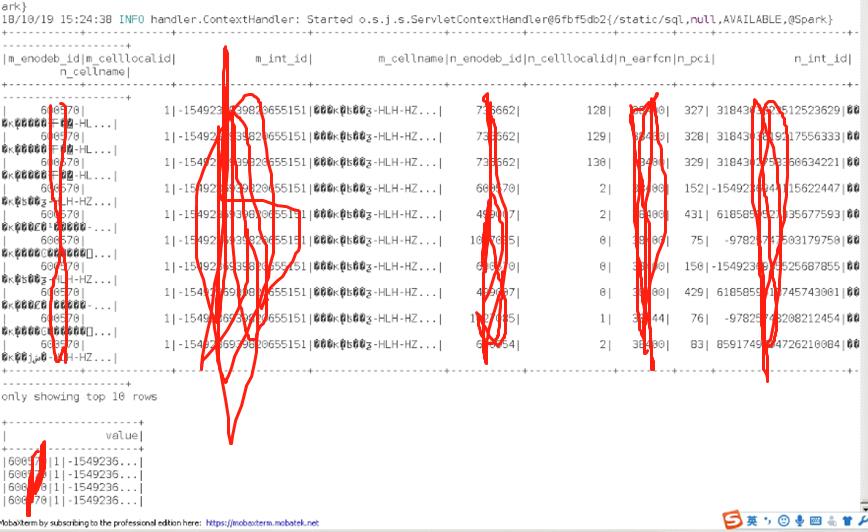
由于一个大文件,在spark中加载性能比较差。于是把一个大文件拆分为多个小文件后上传到hdfs,然而在spark2.2下如何加载某个目录下多个文件呢?public class SparkJob {public static void main(String[] args) {String filePath = args[0];// initialize spark sessionString appName = "Streaming-MRO-Load-Multiple-CSV-Files-Test";SparkSession sparkSession = SparkHelper.getInstance().getAndConfigureSparkSession(a...
我在我的网络应用程序中使用NGINX和sparkjava.我确信我已正确启用所有CORS标头.仍然,我得到“XMLHttpRequest无法加载http://localhost:3003/platformAPI/login.无效的HTTP状态代码404”错误.下面提到的是我的客户端和服务器方法分别来自extjs和spark java.我已经检查了浏览器的网络选项卡以获取响应和请求标头.它们也在下面提到.任何帮助让我知道我的方法有什么问题是非常感谢:)
来自Nginx的客户端方法:function(button, event, o...