Spark SQL用UDF实现按列特征重分区
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Spark SQL用UDF实现按列特征重分区,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3186字,纯文字阅读大概需要5分钟。
内容图文

Spark SQL用UDF实现按列特征重分区
浪尖 浪尖聊大数据
欢迎关注,浪尖公众号,bigdatatip,建议置顶。
这两天,球友又问了我一个比较有意思的问题:

解决问题之前,要先了解一下Spark 原理,要想进行相同数据归类到相同分区,肯定要有产生shuffle步骤。
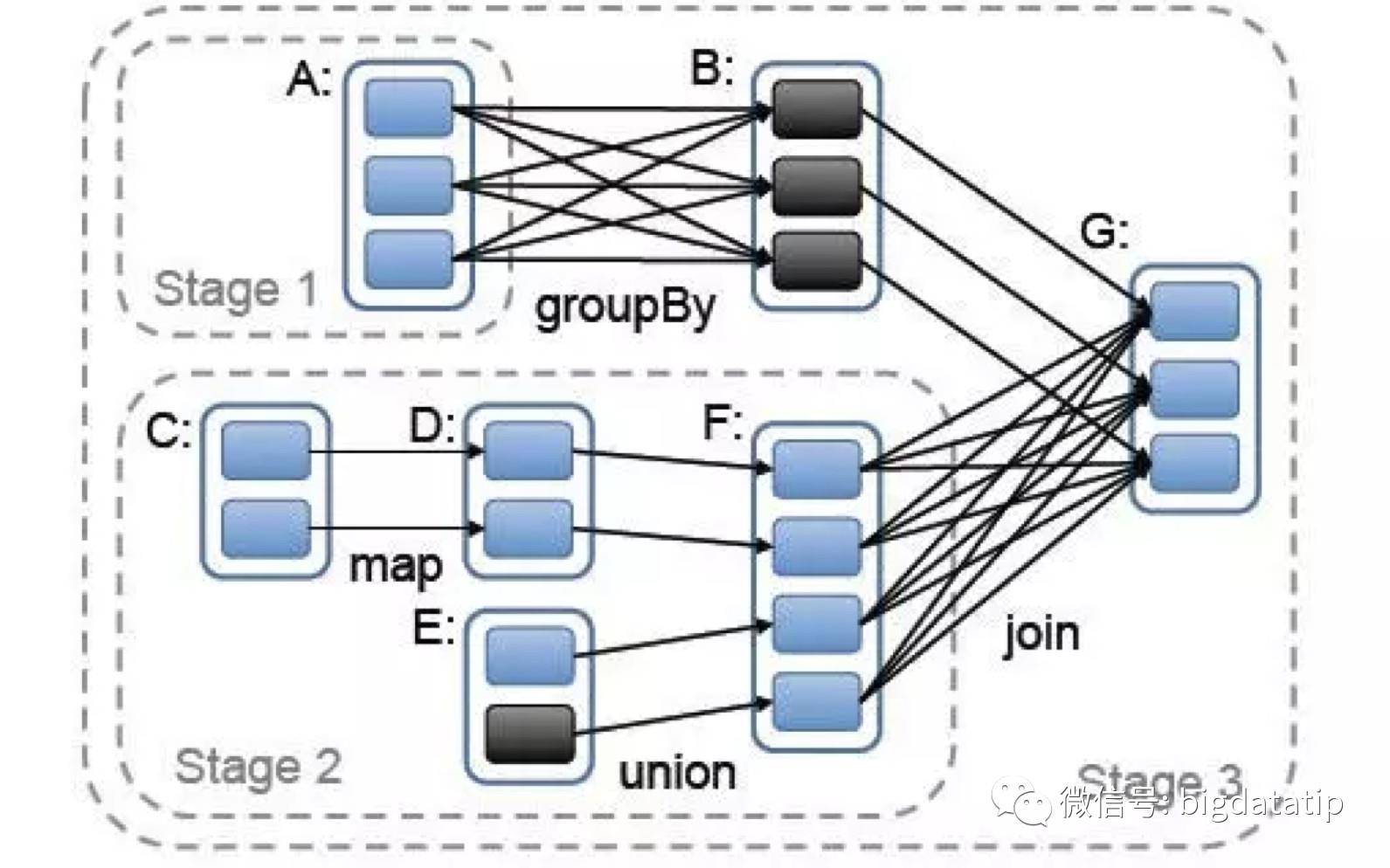
比如,F到G这个shuffle过程,那么如何决定数据到哪个分区去的呢?这就有一个分区器的概念,默认是hash分区器。
假如,我们能在分区这个地方着手的话肯定能实现我们的目标。
那么,在没有看Spark Dataset的接口之前,浪尖也不知道Spark Dataset有没有给我门提供这种类型的API,抱着试一试的心态,可以去Dataset类看一下,这个时候会发现有一个函数叫做repartition。
/**
* Returns a new Dataset partitioned by the given partitioning expressions, using
* `spark.sql.shuffle.partitions` as number of partitions.
* The resulting Dataset is hash partitioned.
*
* This is the same operation as "DISTRIBUTE BY" in SQL (Hive QL).
*
* @group typedrel
* @since 2.0.0
*/
@scala.annotation.varargs
def repartition(partitionExprs: Column*): Dataset[T] = {
repartition(sparkSession.sessionState.conf.numShufflePartitions, partitionExprs: _*)
}可以传入列表达式来进行重新分区,产生的新的Dataset的分区数是由参数spark.sql.shuffle.partitions决定,那么是不是可以满足我们的需求呢?
明显,直接用是不行的,可以间接使用UDF来实现该功能。
方式一-简单重分区
首先,实现一个UDF截取列值共同前缀,当然根据业务需求来写该udf
val substring = udf{(str: String) => {
str.substring(0,str.length-1)
}}注册UDF
spark.udf.register("substring",substring)创建Dataset
val sales = spark.createDataFrame(Seq(
("Warsaw1", 2016, 100),
("Warsaw2", 2017, 200),
("Warsaw3", 2016, 100),
("Warsaw4", 2017, 200),
("Beijing1", 2017, 200),
("Beijing2", 2017, 200),
("Warsaw4", 2017, 200),
("Boston1", 2015, 50),
("Boston2", 2016, 150)
)).toDF("city", "year", "amount")执行充分去操作
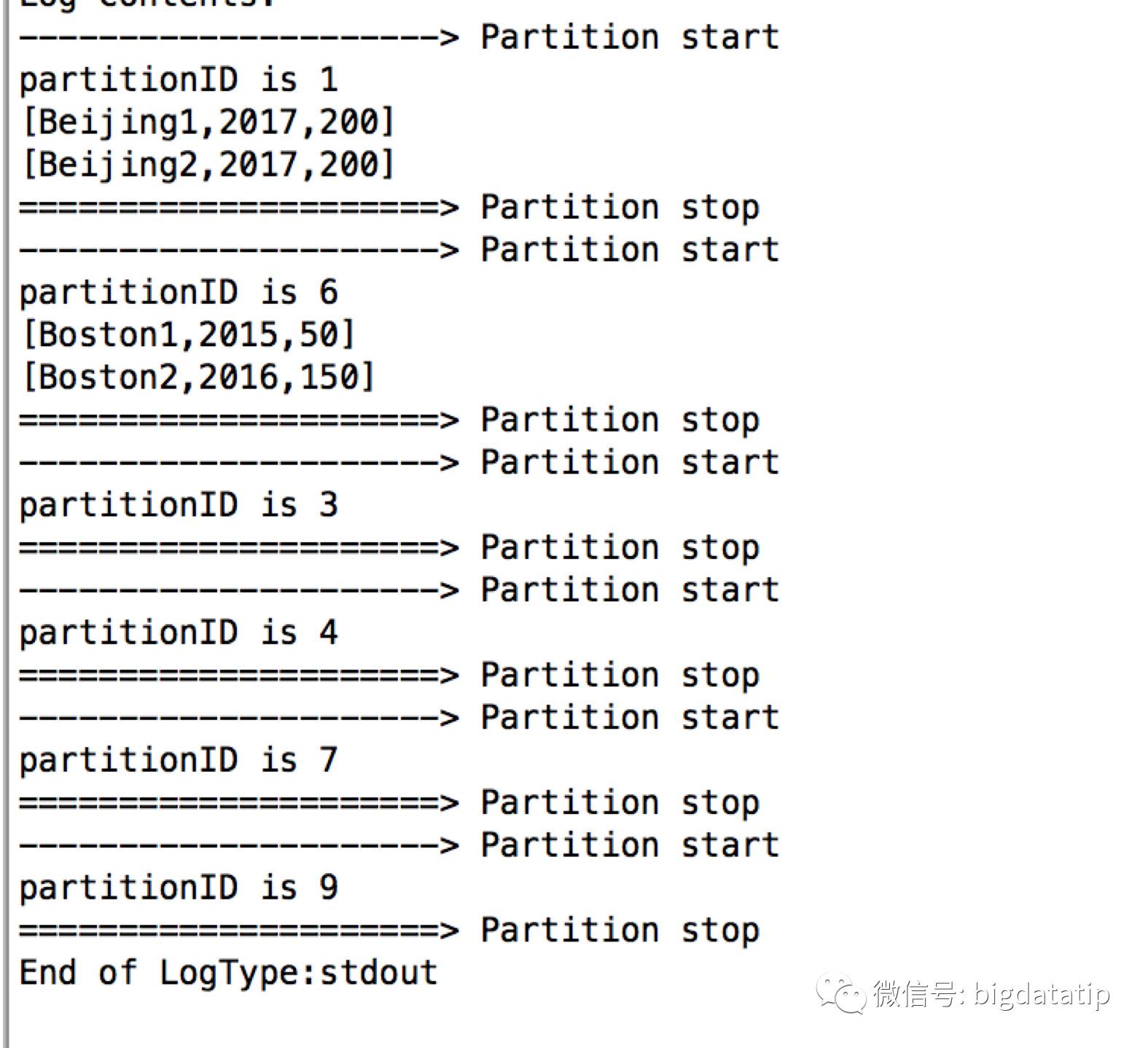
val res = sales.repartition(substring(col("city")))打印分区ID及对应的输出结果
res.foreachPartition(partition=>{
println("---------------------> Partition start ")
println("partitionID is "+TaskContext.getPartitionId())
partition.foreach(println)
println("=====================> Partition stop ")
})浪尖这里spark.sql.shuffle.partitions设置的数值为10.
输出结果截图如下:

方式二-SQL实现
对于Dataset的repartition产生的shuffle是不需要进行聚合就可以产生shuffle使得按照字段值进行归类到某些分区。
SQL的实现要实现重分区要使用group by,然后udf跟上面一样,需要进行聚合操作。
完整代码如下:
val sales = spark.createDataFrame(Seq(
("Warsaw1", 2016, 100),
("Warsaw2", 2017, 200),
("Warsaw3", 2016, 100),
("Warsaw4", 2017, 200),
("Beijing1", 2017, 200),
("Beijing2", 2017, 200),
("Warsaw4", 2017, 200),
("Boston1", 2015, 50),
("Boston2", 2016, 150)
)).toDF("city", "year", "amount")
sales.registerTempTable("temp");
val substring = udf{(str: String) => {
str.substring(0,str.length-1)
}}
spark.udf.register("substring",substring)
val res = spark.sql("select sum(amount) from temp group by substring(city)")
//
res.foreachPartition(partition=>{
println("---------------------> Partition start ")
println("partitionID is "+TaskContext.getPartitionId())
partition.foreach(println)
println("=====================> Partition stop ")
})输出结果如下:
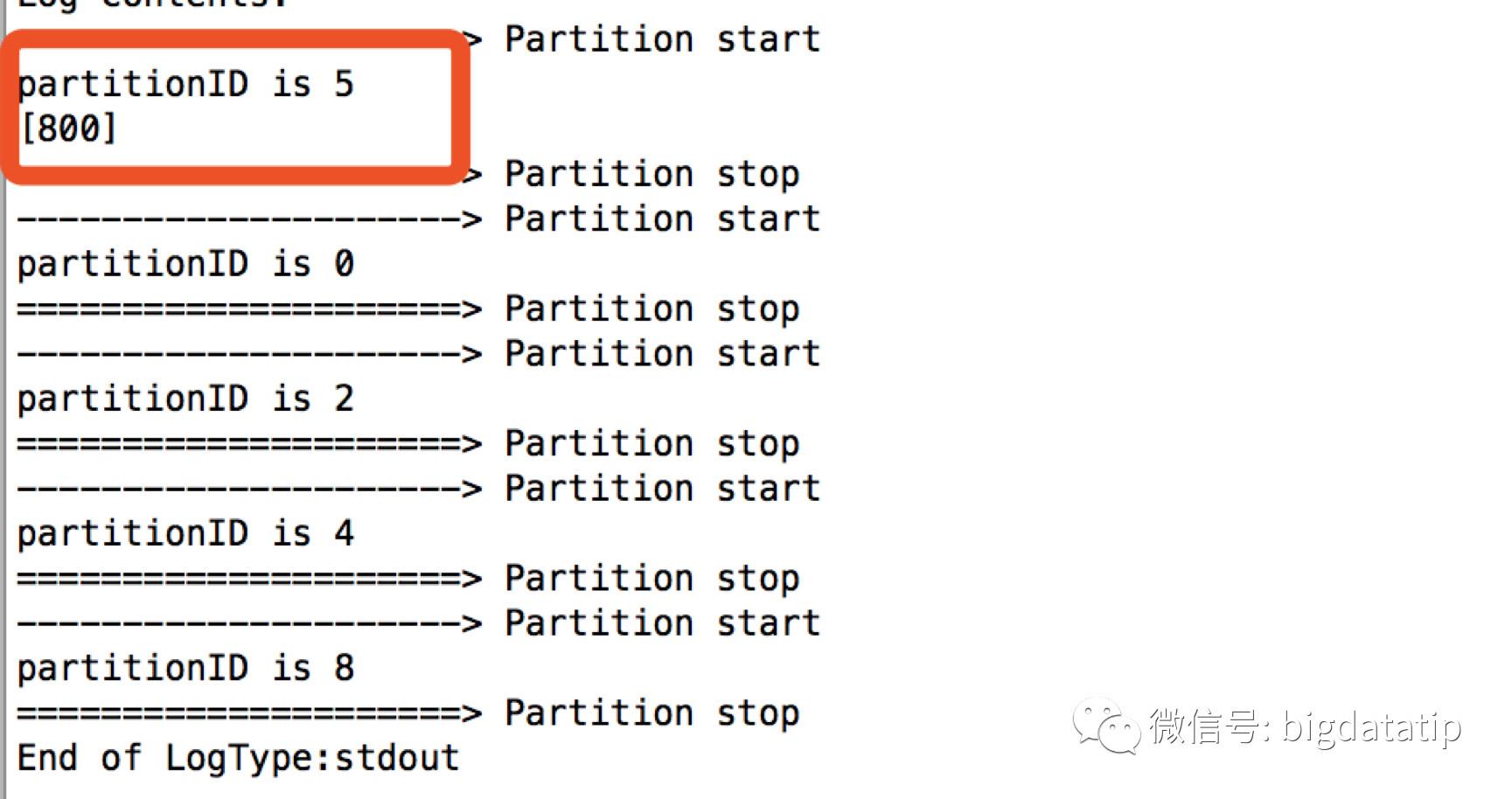
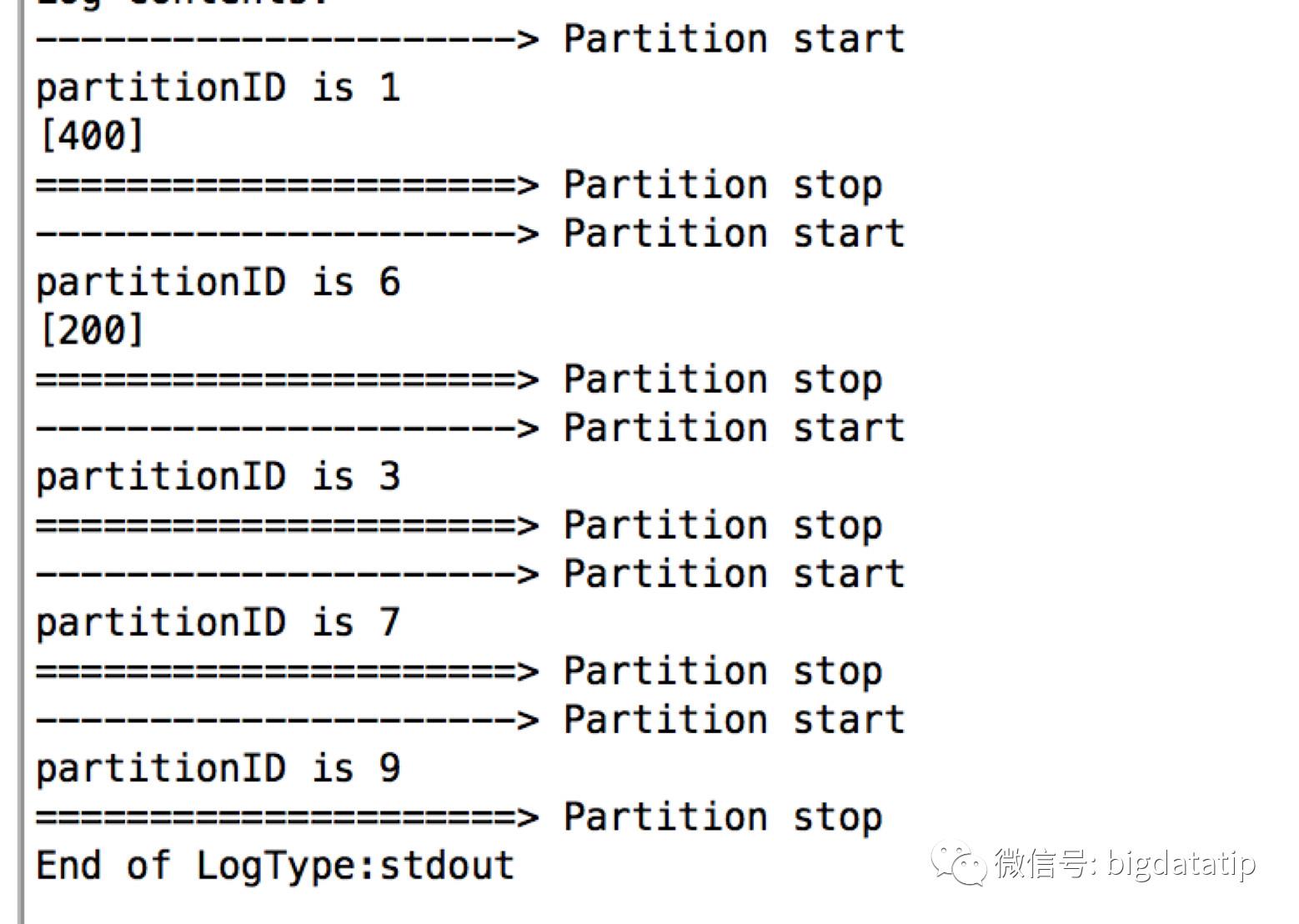
由上面的结果也可以看到task执行结束时间是无序的。
浪尖在这里主要是讲了Spark SQL 如何实现按照自己的需求对某列重分区。
那么,浪尖在这里就顺带问一下,如何用Spark Core实现该功能呢?
内容总结
以上是互联网集市为您收集整理的Spark SQL用UDF实现按列特征重分区全部内容,希望文章能够帮你解决Spark SQL用UDF实现按列特征重分区所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。