首页 / REDIS / redis数据库(一)
redis数据库(一)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了redis数据库(一),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4299字,纯文字阅读大概需要7分钟。
内容图文
")
redis数据库 一
一、Nosql概述
1、为什么要用Nosql
1.1 单机 MySQL 的美好时代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。 在那个时候,更多的都是静态网页,动态交互类型的网站不多,数据库更是没压力。
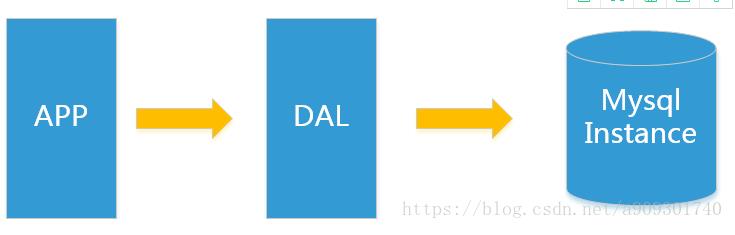
上述架构下,我们来看看数据存储的瓶颈是什么?
DAL : Data Access Layer(数据访问层 – Hibernate,MyBatis)
数据量的总大小一个机器放不下时。 数据的索引(B+ Tree)一个机器的内存放不下时。 访问量(读写混合)一个实例不能承受。 如果满足了上述1 or 3个时,只能对数据库的整体架构进行重构。
1.2 Memcached(缓存)+MySQL+垂直拆分
后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常时尚的技术产品。

Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务,在Memcached服务器上,又发展了根据hash算法来进行多台Memcached缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效的弊端。
1.3 Mysql主从读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了。

1.4 分库分表+水平拆分+mysql集群
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM在写数据的时候会使用表锁,在高并发写数据的情况下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。
ps:这就是为什么 MySQL 在 5.6 版本之后使用 InnoDB 做为默认存储引擎的原因 – MyISAM 写会锁表,InnoDB 有行锁,发生冲突的几率低,并发性能高。
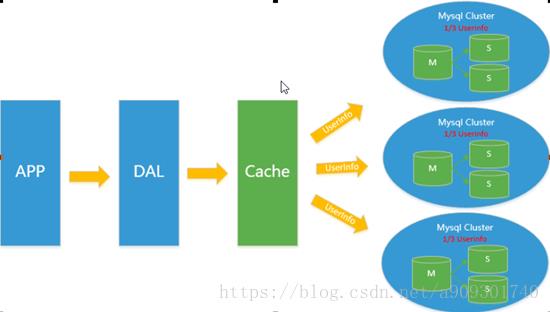
同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门
技术,是面试的热门问题也是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的
表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不
能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
1.5 MySQL的扩展性瓶颈
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常
的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从
MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场
景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前
使用MySQL的开发人员面临的问题。
1.6 今天是什么样子?

最前面的是企业级防火墙,后面通过负载均衡主机(软负载:Nginx,硬负载:F5)在 web 服务器集群
之间进行调度,再由具体的 web 服务器(Tomcat)去访问缓存,访问数据库。
1.7 为什么用NoSQL?
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人
信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户
数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的
数据。
2、什么是NoSQL
NoSQL = Not Only SQL (不仅仅是SQL) 关系型数据库:表格 ,行 ,列
很多的数据类型用户的个人信息,社交网络,地理位置。这些数据类型的存储不需要一个固定的格式!
不需要多月的操作就可以横向扩展的 ! Map<String,Object> 使用键值对来控制!
NoSQL,泛指非关系型数据库,主要分为四大类:
2.1 key-value存储数据库。
该类数据库使用哈希表,在哈希表中包含特定的key和与其对应的指向特定数据的指针。常用的有
Redis。
2.2 列存储数据库。
该类数据库主要用来应对分布式存储的海量数据,一个键指向了多个列。常用的有HBase。
2.3 文档型数据库。
该类数据库将结构化、半结构化的文档以特定格式存储,如json格式。一个文档相当于关系型数据库中
的一条记录,也是处理信息的基本单位。常用的有MongoDB。
2.4 图形数据库
该类数据库使用图形理论来存储实体之间的关系信息,最主要的组成部分是:结点集、连接节点的关
系。常用的有Neo4j,朋友圈社交网络,广告推荐!如脉脉。
非关系型数据库的特点:
1.数据模型比较简单。
2.对数据库性能的要求比较高。
3.不需要高度的数据一致性。
内容总结
以上是互联网集市为您收集整理的redis数据库(一)全部内容,希望文章能够帮你解决redis数据库(一)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。