ORACLE的SQL练习---8. 窗口函数OVER()
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了ORACLE的SQL练习---8. 窗口函数OVER(),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含6217字,纯文字阅读大概需要9分钟。
内容图文
")
Over()窗口函数最常见的搭配有以下几种:
- rank(),dense_rank(),row_number() + over(partition by … order by …) 排名
- sum(),avg(),count()聚合函数+over(partition by … order by …)
- max(),min()+over(partition by … order by …) 最大值、最小值
- first_value(),last_value() + over(partition by … order by …) 第一条、最后一条记录
- lag(),lead() + over(partition by … order by …) 偏移量
其中的partition by 是分组,order by 是排序。这里的分组与group by 是不同的,最明显的是group by会影响返回结果的条数,但是partition by 不会。
案例用到的建表语句:
create table LX_05_SALARY
(
id NUMBER,
department_name VARCHAR2(100),
sal NUMBER,
pay_date DATE
)
插数语句:
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (1, 'A部门', 80000, to_date('10-01-2020', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (2, 'B部门', 60000, to_date('10-01-2020', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (3, 'C部门', 100000, to_date('10-01-2020', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (4, 'A部门', 70000, to_date('10-12-2019', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (5, 'B部门', 60000, to_date('10-12-2019', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (6, 'C部门', 80000, to_date('10-12-2019', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (7, 'C部门', 48000, to_date('10-12-2019', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (8, 'C部门', 92000, to_date('10-12-2019', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (9, 'B部门', 90000, to_date('10-12-2019', 'dd-mm-yyyy'));
insert into lx_05_salary (ID, DEPARTMENT_NAME, SAL, PAY_DATE)
values (10, 'B部门', 50000, to_date('10-12-2019', 'dd-mm-yyyy'));
具体的用法如下:
- rank(),dense_rank(),row_number() + over(partition by … order by …) 排名:
select a.department_name,
a.id,
a.sal,
rank() over(partition by a.department_name order by a.sal desc) as rank排名,
dense_rank() over(partition by a.department_name order by a.sal desc) as dense_rank排名,
row_number() over(partition by a.department_name order by a.sal desc) as row_number排序
from lx_05_salary a;
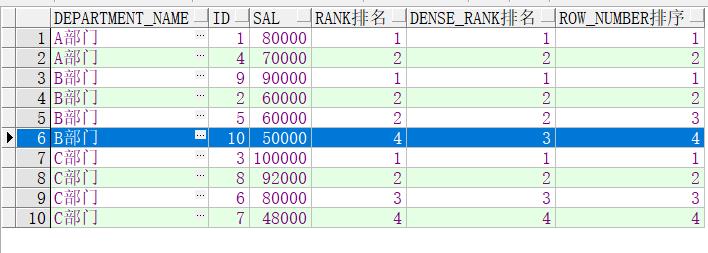
由上图结果可以看出:
rank()的排名如果有并列出现,下一名会跳过并列的名次。有两个同时排名第二,那下一条就是第四名。
dense_rank()的排名与rank()不同,出现并列不会跳过并列的名次,依然按顺序排名。例如:两个第二名,下一条还是第三名。
row_number()不会出现并列的情况,一直顺序排下去。
知道这三者之间的区别之后,就需要在实际应用中选择合适方式来使用。
- sum(),avg(),count()聚合函数+over(partition by … order by …)
select a.department_name,a.id,a.sal,
sum(a.sal)over(partition by a.department_name order by a.id ) as 部门内连续求和 ,
sum(a.sal)over(partition by a.department_name) as 部门求和,
round(a.sal/sum(a.sal)over(partition by a.department_name),4)*100 as 每人占部门份额 ,
sum(a.sal)over(order by a.department_name) as 部门连续求和,
sum(a.sal)over(order by a.id) as 人员连续求和,
sum(a.sal) over() as 总计,
round(a.sal/sum(a.sal) over(),4)*100 as 人员份额,
round(sum(a.sal) over(partition by a.department_name)/sum(a.sal) over(),4)*100 as 部门份额
from lx_05_salary a
order by a.department_name;
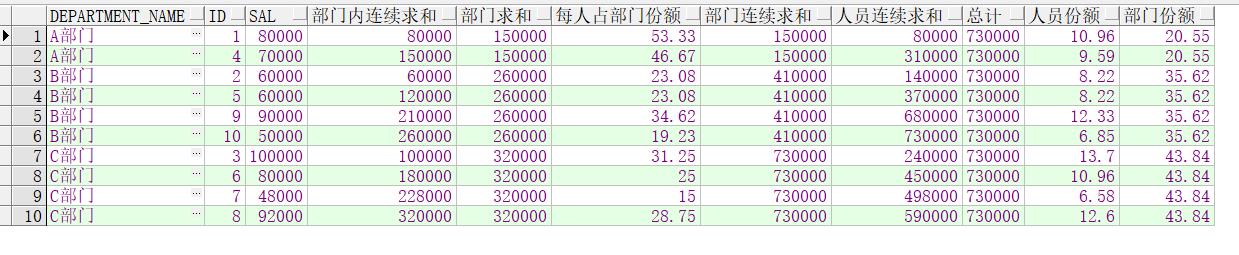
over()中使用order by 会在分组内连续向下求和。不使用的话就只会在当前分组下求合计。avg(),count()的用法是一致的。
- max(),min()+over(partition by … order by …) 最大值、最小值
select a.department_name,
a.id,
a.sal,
max(a.sal) over(partition by a.department_name order by a.sal desc) as max_desc,
min(a.sal) over(partition by a.department_name order by a.sal desc) as min_desc_失效,
min(a.sal) over(partition by a.department_name order by a.sal desc rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as min_desc,
max(a.sal) over(partition by a.department_name order by a.sal asc) as max_asc_失效,
max(a.sal) over(partition by a.department_name order by a.sal asc rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as max_asc,
min(a.sal) over(partition by a.department_name order by a.sal asc) as min_asc
from lx_05_salary a
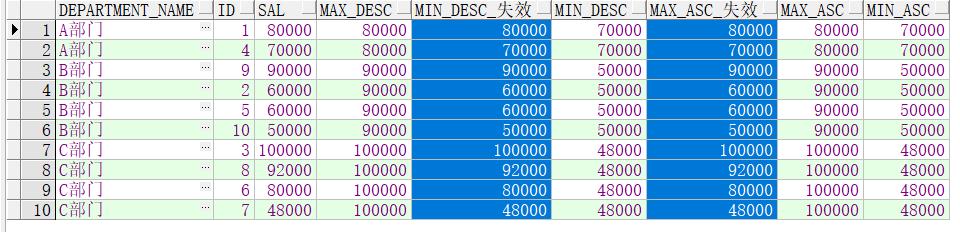
min(),max()在使用order by的时候会有无效的情况,要么就去掉order by 要么向上面例子使用(rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)具体的可以参考这位大神的文章https://blog.csdn.net/weixin_34306446/article/details/85697339
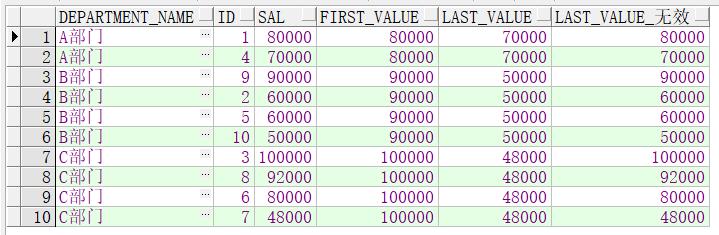
- first_value(),last_value() + over(partition by … order by …) 第一条、最后一条记录。
first_value(),last_value() 与max()和min()一样,在升序或者降序排序的时候也会有无效的情况。
select a.department_name,
a.id,
a.sal,
first_value(a.sal) over(partition by a.department_name order by a.sal desc) as first_value,
last_value(a.sal) over(partition by a.department_name order by a.sal desc rows BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as last_value,
last_value(a.sal) over(partition by a.department_name order by a.sal asc) as last_value_无效
from lx_05_salary a;
- lag(),lead() + over(partition by … order by …) 偏移量
语法:
lag(目标字段,偏移量,默认值) + over(partition by … order by …)
lead(目标字段,偏移量,默认值) + over(partition by … order by …)
举例:
没有默认值的会取空
select a.*,
lag(a.id, 1 ) over(partition by a.department_name order by a.id) as 同部门_上一id,
lead(a.id, 1 ) over(partition by a.department_name order by a.id) as 同部门_下一id,
lag(a.id,1) over(order by a.id) as 全部_上一id ,
lead(a.id,1) over(order by a.id) as 全部_下一id
from lx_05_salary a
order by a.department_name,a.id;
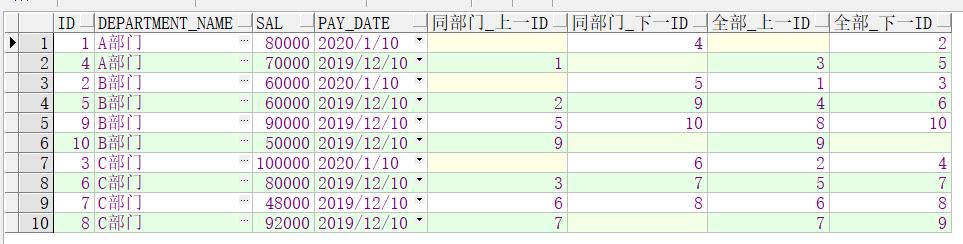
如果不写偏移量,默认是1,如下例:
select a.*,
lag(a.id ) over(partition by a.department_name order by a.id) as 同部门_上一id,
lead(a.id ) over(partition by a.department_name order by a.id) as 同部门_下一id,
lag(a.id ) over(order by a.id) as 全部_上一id ,
lead(a.id ) over(order by a.id) as 全部_下一id
from lx_05_salary a
order by a.department_name,a.id;
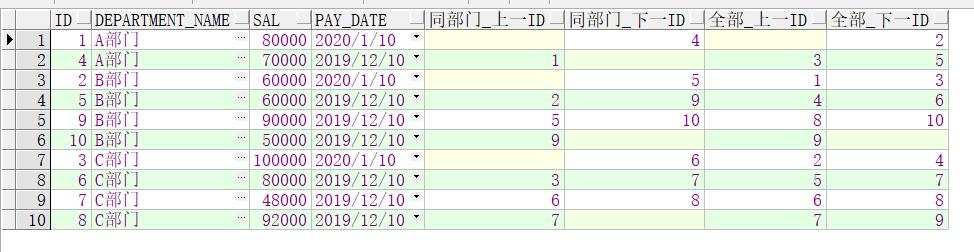
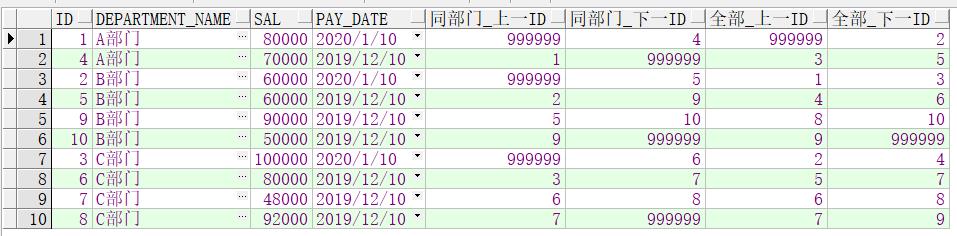
设置默认值的写法:
select a.*,
lag(a.id, 1,999999 ) over(partition by a.department_name order by a.id) as 同部门_上一id,
lead(a.id, 1,999999 ) over(partition by a.department_name order by a.id) as 同部门_下一id,
lag(a.id,1,999999 ) over(order by a.id) as 全部_上一id ,
lead(a.id,1,999999 ) over(order by a.id) as 全部_下一id
from lx_05_salary a
order by a.department_name,a.id;
内容总结
以上是互联网集市为您收集整理的ORACLE的SQL练习---8. 窗口函数OVER()全部内容,希望文章能够帮你解决ORACLE的SQL练习---8. 窗口函数OVER()所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。