首页 / MYSQL / Mysql调优-5查询优化
Mysql调优-5查询优化
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Mysql调优-5查询优化,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3962字,纯文字阅读大概需要6分钟。
内容图文

查询优化
1.分析查询慢的原因:
硬件+程序的原因
1>网络对查询是有影响的,网络IO的影响;
2>CPU:
3>IO:
4>上下文切换:服务器中n个任务执行,任务的切换
5>系统调用:
6>生成统计信息:show profiles;
7>锁等待时间:
2.优化数据访问:
MyISAM:共享读锁+读占写锁;只能锁表
InnoDB:共享锁+排他锁;锁表或者行;InnoDB锁的对象是索引,如果锁的列是索引列,锁的是行;没有索引的话锁的是表;
2.1查询性能低下的主要原因是访问的数据太多,某些查询不可避免的需要筛选大量的数据,我们可以通过减少访问数据量的方式进行优化->IO的问题;
1>确认应用程序是否在检索大量超过需要的数据;
两条sql一致,只是查询条件不一致,索引字段是一致的,rows不一致,因为如果查询的数据量非常大的话,就有可能出现不用索引,但是阈值是不确定的(30%?)。
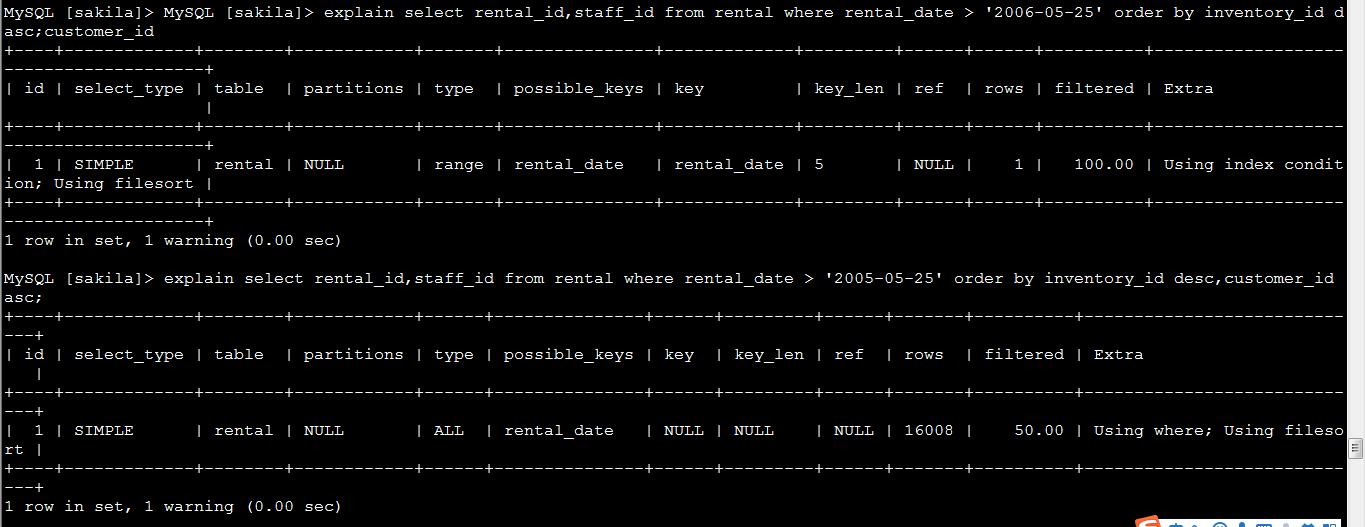
实际只需要5条,但是rows缺筛选了16008条;->SQL优化
limit 10000,10000这个值特别大,影响了sql的查询进行全表扫描,可以使用子查询来解决?
2>确认mysql服务器是否在分析大量超过需要的数据行:
->总之就是是否能筛选更少的数据来达到需要的效果->减少IO量
2.2是否向数据库请求了不需要的数据:
1>查询不需要的记录:mysql一般是先返回全部数据再进行计算,优化查询limit记录
2>多表关联时返回全部列:

通过查询时间可以看出来,*尽量不要出现在select中,而且多表关联的时候,筛选哪些字段就明确获取哪些字段,多表关联,每个表尽量加别名.
3>总是取出全部列:
4>重复查询相同的数据:可以数据库缓存实现(8以后去掉了),但是需要考虑到数据库不停更新的情况,所以用redis实现,涉及到数据淘汰策略,LRU策略;
3.执行过程的优化:
3.1查询缓存:->命中率比较低,常量表可以放到缓存中;
3.2查询优化处理:
1>语法解析器
apach calcite ->AST
2>查询优化器
执行方式多种,选择最有效的优化方式来执行,CBO(基于成本的优化->选择)+RBO(基于规则的优化)
mysql的优化一般是基于成本的优化,不一定是执行最快的优化(例如多表的查询,并不能保证join的查询,除非强制,所以具体join顺序是不能保证的)
mysql不会考虑不受其控制的操作成本.
优化器的优化策略:
动态优化:每次执行都需要重新评估
静态优化:只需要一次
优化器的优化类型:
重新定义关联表的执行顺序,不强制指定顺序的话,优化器决定
将外连接转换为内连接,内连接效率高于外连接
使用等价变换规则: in推荐使用替代多个查询条件, and 和or推荐使用or,不影响
聚合函数使用的时候需要注意分组优于min,max,但是具体看需求
索引的效率更高
覆盖索引:所有查询列包含在索引字段中
子查询优化:
等值传播:film.film_id>500 and film_actor.film_id>500, 很少这样写,都是只写一个film_id>500即可.
? limit 10000,5 的只筛选5条数据;
join_buffer;->show variables like 'JOIN_BUFFER';
一般情况很少去改Mysql的优化器;
3.3排序(**):
排序:https://www.cnblogs.com/wt645631686/p/8320525.html
提高ORDER BY速度的技巧
1:ORDER BY时不要使用SELECT *,只查需要的字段。
a:当查询的字段大小综合小于max_length_for_sort_data而且排序字段不是TEXT|BLOB类型时,会用改进后的算法---单路排序,否则用老算法---多路排序。假设只需要查10个字段,但是SELECT *会查80个字段,那么就容易把sort_buffer缓冲区用满。
b:两种算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size大小。
2:增大sort_buffer_size参数大小
不管用哪种算法,提高这个参数都会提高效率。当然要根据系统能力去提高,因为这个参数是针对每个进程的。
3:增大max_length_for_sort_data参数大小
提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总量超出sort_buffer_size的概率就增大,明显症状是高的磁盘I/O活动和低的处理器使用率。
4.优化特定类型的查询:
4.1优化count的查询:
count(*) count(id) 和 count(1)在mysql中的查询效率是相同的;
myisam中只有没有任何where条件的count(*)才会比较快
使用近似值:OLAP中HyperLoglog
更复杂的优化:每次统计查询的时候,例如每次更新一条记录,缓存中要统计,可以借助于汇总表,缓存系统来优化.
4.2优化关联查询:
确保on或者using子句中的列上有索引,在创建索引的时候就要考虑到关联的顺序
确保任何的group by和order by中的表达式只涉及到一个表中的列,这样mysql才有可能使用索引来优化这个过程
4.3优化子查询:
子查询的sql尽量使用关联查询来进行替代,因为子查询的结果放临时表,涉及到io,所以能不用子查询尽量不要用子查询,join的临时表放最终的结果的
说明:https://www.cnblogs.com/cjjjj/p/12738334.html
4.4优化limit分页
5.推荐使用用户自定义变量:
select @@autocommit;
select @i:=@i+1;
内容总结
以上是互联网集市为您收集整理的Mysql调优-5查询优化全部内容,希望文章能够帮你解决Mysql调优-5查询优化所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。