基于 Scrapy-redis 的分布式爬虫设计 目录前言安装环境Debian / Ubuntu / Deepin 下安装Windows 下安装基本使用初始化项目创建爬虫运行爬虫爬取结果进阶使用分布式爬虫anti-anti-spiderURL Filter总结相关资料前言在本篇中,我假定您已经熟悉并安装了 Python3。 如若不然,请参考 Python 入门指南。关于 ScrapyScrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等...
scrapy-redis 分布式爬虫爬取房天下网站所有国内城市的新房和二手房信息先完成单机版的爬虫,然后将单机版爬虫转为分布式爬虫爬取思路1. 进入 https://www.fang.com/SoufunFamily.htm 页面,解析所有的省份和城市,获取到城市首页链接
2. 通过分析,每个城市的新房都是在首页链接上添加newhouse和house/s/字符串,二手房 都死在首页链接上添加esf字段
以上海为例:
首页:https://sh.fang.com/
新房:https://sh.newhouse....
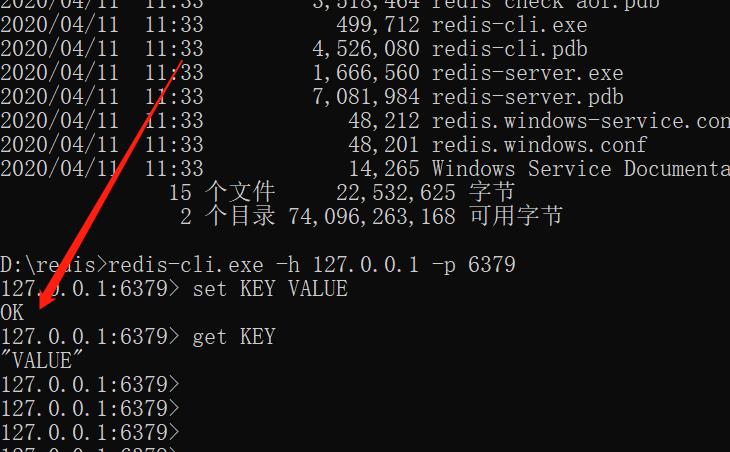
1.Redis连接启动服务:cd redis的安装路径------>redis-server.execd redis的安装路径------>redis-clipython中连接redis:#第一种连接from redis import StrictRedis
redis = StrictRedis(host=‘localhost‘,port=6379,db=0)
#第二种连接from redis import StrictRedis,ConnectionPool
pool = ConnectionPool(host=‘localhost‘,port=6379,db=0)
redis = StrictRedis(connection_pool=pool)
redis.set(‘name‘,‘bob‘)
print(...
1、如何将一个scrapy爬虫项目修改成为一个简单的分布式爬虫项目官方文档:https://scrapy-redis.readthedocs.io/en/stable/只用修改scrapy项目的两个文件就可以了一个是爬虫组件文件:# -*- coding: utf-8 -*-import scrapy
from scrapy_redis.spiders import RedisSpider# 自定义爬虫类的继承类不再是scrapy.spiders下面的爬虫类,
# 而是scrapy-redis.spiders下面的爬虫类class DistributedSpiderSpider(RedisSpider):name = ‘d...
本篇文章给大家带来的内容是关于如何使用Redis的Bloomfilter去重,既用上了Bloomfilter的海量去重能力,又用上了Redis的可持久化能力,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。前言:“去重”是日常工作中会经常用到的一项技能,在爬虫领域更是常用,并且规模一般都比较大。去重需要考虑两个点:去重的数据量、去重速度。为了保持较快的去重速度,一般选择在内存中进行去重。数据量不大时,可以直接放在内...
因为发现爬虫爬取出来的数据如果按照表结构划分后存储,不仅麻烦而且非常大的冗余
干脆试试用这样的非关系数据库来试试存储效果如何。
这里我不打算用redis 进行比较,因为他是内存数据库,他擅长的领域应该是缓存和少量数据的统计归类
(做这个的还有另外一大家伙memcache),redis 以后相配合 其他应用提高效率的。
这里相比较的主要是mongodb和mysql 的性能差,就特定指的是这样复杂的关系网络的应用环境下!!apt-cache depend...
1.1打开浏览器,访问redist官网https://redis.io/download 1.2如图所示:点击windows目录下的learn morn进入github下载界面1.3如下图所示:点击clone or download下载源码压缩包
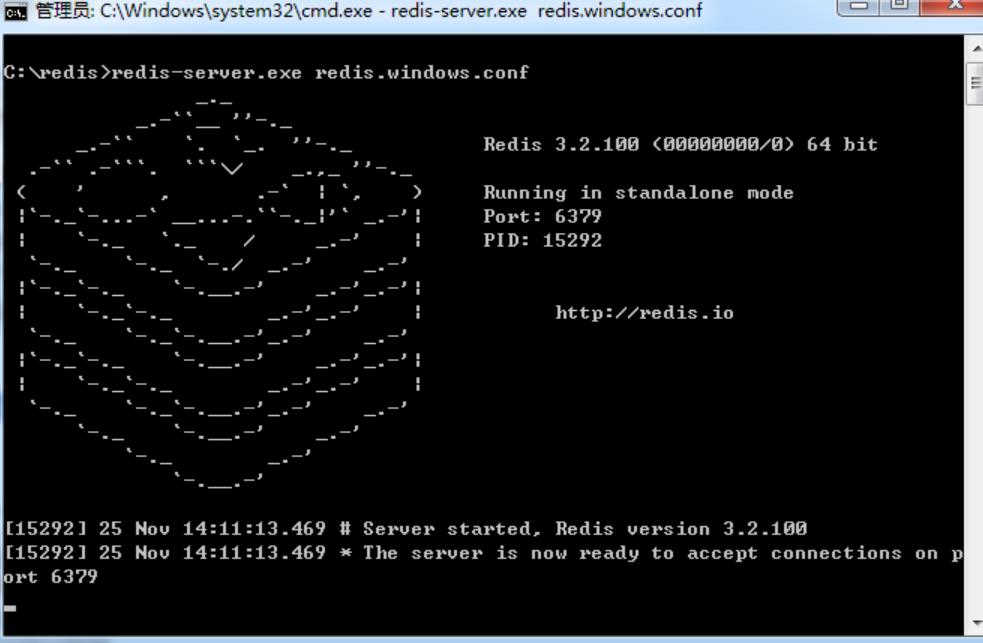
2.redis的安装及验证
2.1解压及安装过程省略,安装后目录 各文件的含义文件名
简要redis-benchmark.exe
基准测试redis-check-aof.exe
aofredischeck-dump.exe
dumpredis-cli.exe
客户端redis-server.exe
服务器redis.windows.conf
配置文件
...
抓取下网页代码之后,下一步就是从网页中提取信息,提取信息的方式有多种多样,可以使用正则来提取,但是写起来会相对比较繁琐。在这里还有许多强大的解析库,如 LXML、BeautifulSoup、PyQuery 等等,提供了非常强大的解析方法,如 XPath 解析、CSS 选择器解析等等,利用它们我们可以高效便捷地从从网页中提取出有效信息。
本节我们就来介绍一下这些库的安装过程。
1.2.1 LXML的安装
LXML 是 Python 的一个解析库,支持 HTML 和 XM...
在前面一节我们介绍了几个数据库的安装方式,但这仅仅是用来存储数据的数据库,它们提供了存储服务,但如果想要和 Python 交互的话也同样需要安装一些 Python 存储库,如 MySQL 需要安装 PyMySQL,MongoDB 需要安装 PyMongo 等等,本节我们来说明一下这些库的安装方式。
1.4.1 PyMySQL的安装
在前面一节我们了解了 MySQL 的安装方式,在 Python3 中如果想要将数据存储到 MySQL 中就需要借助于 PyMySQL 来操作,本节我们介绍一下 Py...
Redis 是一个基于内存的高效的键值型非关系型数据库,存取效率极高,而且支持多种存储数据结构,使用也非常简单,在本节我们介绍一下 Python 的 Redis 操作,主要介绍 RedisPy 这个库的用法。
1. 准备工作
在本节开始之前请确保已经安装好了 Redis 及 RedisPy库,如果要做数据导入导出操作的话还需要安装 RedisDump,如没有安装可以参考第一章的安装说明。
2. Redis、StrictRedis
RedisPy 库提供两个类 Redis 和 StrictRedis 用于实...
同学们在使用scrapy-redis分布式爬虫框架开发的时候会发现,其默认只能发送GET请求,不能直接发送POST请求,这就导致我们在开发一些爬虫工具的时候出现问题,那么如何才能让scrapy-redis发送POST请求呢?scrapy-redis爬虫这里我们以美团网站为例,先来说一说需求,也就是说美团POST请求形式。我们以获取某个地理坐标下,所有店铺类别列表请求为例。获取所有店铺类别列表时,我们需要构造一个包含位置坐标经纬度等信息的表单数据,以...
同学们在使用scrapy-redis分布式爬虫框架开发的时候会发现,其默认只能发送GET请求,不能直接发送POST请求,这就导致我们在开发一些爬虫工具的时候出现问题,那么如何才能让scrapy-redis发送POST请求呢?
scrapy-redis爬虫
这里我们以美团网站为例,先来说一说需求,也就是说美团POST请求形式。我们以获取某个地理坐标下,所有店铺类别列表请求为例。获取所有店铺类别列表时,我们需要构造一个包含位置坐标经纬度等信息的表单数据,...
同学们在使用scrapy-redis分布式爬虫框架开发的时候会发现,其默认只能发送GET请求,不能直接发送POST请求,这就导致我们在开发一些爬虫工具的时候出现问题,那么如何才能让scrapy-redis发送POST请求呢? scrapy-redis爬虫 这里我们以美团网站为例, 先来说一说需求,也就是说美团POST请求形式。我们以获取某个地理坐标下,所有店铺类别列表请求为例。获取所有店铺类别列表时,我们需要构造一个包含位置坐标经纬度等...
Scrapy框架进阶+Redis入门
1. 设置代理IP1.1 基本概念1.2 设置代理IP
2. scrapy集成selenium2.1 代码需求2.2 案例代码
3. Scrapy框架进阶——Redis数据库3.1 基本概念3.2 redis数据库的使用:1. 设置代理IP
1.1 基本概念
什么是代理IP: 代理IP服务器是在计算机上运行的专用计算机或软件系统,其充当端点设备(例如计算机)与用户或客户端从其请求服务的另一服务器之间的中介。
为什么要设置代理IP:
突破自身的IP访问限制,防止因...
文章目录
第二十三章 scrapy_redis讲解1. python和redis的交互2. scrapy_redis讲解3. 下载scrap_redis案例第二十三章 scrapy_redis讲解
1. python和redis的交互
首先安装redis,pip install redis。
Collecting redisDownloading redis-3.5.3-py2.py3-none-any.whl (72 kB)|████████████████████████████████| 72 kB 207 kB/s
Installing collected packages: redis
Successfully installed redis...
Redis库安装原来只需这样简单三步")
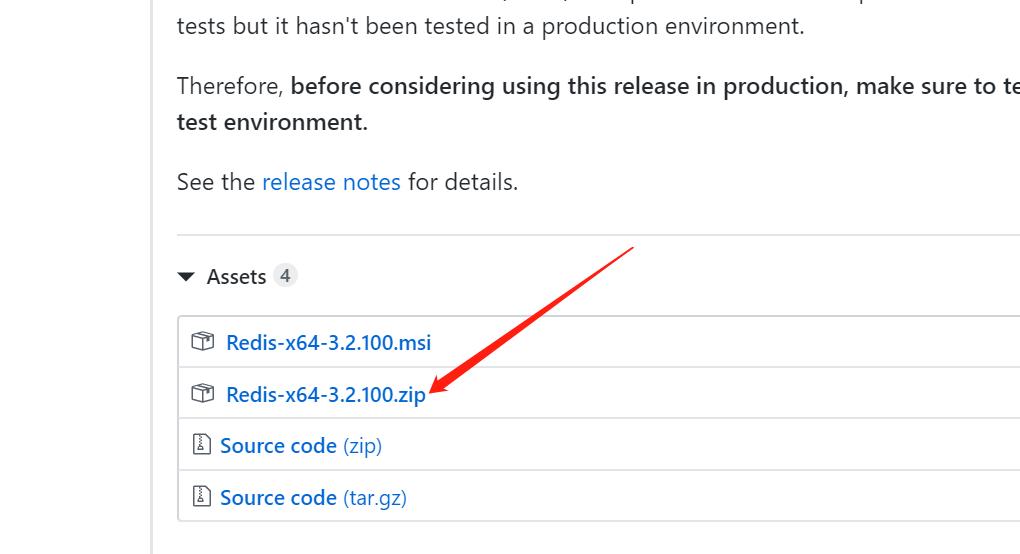 解压后,将文件夹重新命名为 redis,那你的redis文件夹所在目录就为C:/redis。
解压后,将文件夹重新命名为 redis,那你的redis文件夹所在目录就为C:/redis。