我的设备上每秒将2000条数据插入数据库,2个设备总共4000条,当在程序里面直接用insert语句插入时,两个设备同时插入大概总共能插入约2800条左右,数据丢失约1200条左右,测试了很多方法,整理出了两种效果比较明显的解决办法:方法一:使用Sql Server函数:1.将数据组合成字串,使用函数将数据插入内存表,后将内存表数据复制到要插入的表。2.组合成的字符换格式:111|222|333|456,7894,7458|0|1|2014-01-01 12:15:16;1111|2222|33...
1.1:增加次数据文件 从SQL SERVER 2005开始,数据库不默认生成NDF数据文件,一般情况下有一个主数据文件(MDF)就够了,但是有些大型的数据库,由于信息很多,而且查询频繁,所以为了提高查询速度,可以把一些表或者一些表中的部分记录分开存储在不同的数据文件里 由于CPU和内存的速度远大于硬盘的读写速度,所以可以把不同的数据文件放在不同的物理硬盘里,这样执行查询的时候,就可以让多个硬盘同时进行查询,以充分利用CPU和内...
void Main(string[] args){int count = 0;string readerPath=@"C:\Users\Administrator\Desktop\readerDemo.csv";string writerPath=@"C:\Users\Administrator\Desktop\writeDemo.csv";if (File.Exists(writerPath)){File.Delete(writerPath);}using (StreamReader reader = new StreamReader(readerPath,Encoding.UTF8)){while (!reader.EndOfStream){string line = reader.ReadLine();using (StreamWriter writer = new StreamWr...
gridid,lng,lat from finger_lib_server where lng>min_lng and lng<max_lng and lat>min_lat and lat<max_lat;发现问题,使用下边的语句查看数据库是否有锁存在: --查看被锁表: select request_session_id as spid,OBJECT_NAME(resource_associated_entity_id) as tableName from sys.dm_tran_locks where resource_type=‘OBJECT‘--spid 锁表进程 --tableName 被锁表名-- 解锁:declare @spid int Set @spid = 57...
数据库代码
USE [Test]
GO
/****** Object: Table [dbo].[Table_1] Script Date: 11/07/2017 17:27:29 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
SET ANSI_PADDING ON
GO
CREATE TABLE [dbo].[Table_1]([id] [varchar](100) NULL,[NodeId] [varchar](100) NULL,[t_B_NodeID] [varchar](100) NULL,[NodeType] [varchar](100) NULL,[AuthorityCode] [varchar](100) NULL,[NodeName] [varchar](100) NUL...
BULKINSERT 是SQLSERVER中提供的一条大数据量导入的命令,它运用DTS(SSIS)导入原理,可以从本地或远程服务器上批量导入数据库或文件数据。批量插入是一个独立的操作,优点是效率非常高。缺点是出现问题后不可以回滚。 BULKINSERT是用来将外部文件以一种特定
BULK INSERT是SQLSERVER中提供的一条大数据量导入的命令,它运用DTS(SSIS)导入原理,可以从本地或远程服务器上批量导入数据库或文件数据。批量插入是一个独立的操作,优点是...
分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间) 很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间 这里共享一个脚本 CREATE TABLE #tablespaceinfo ( nameinfo VARCHAR ( 500 ) , rowsinfo BIGINT , reserved分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间这里共享一个脚本CREATE TABL...
方法一:分步搬移(针对百万 数据 量) -----remove data---------- insert into BizOfferSearch_Insert_Temp select top 2000000 id,0 isinsert from BizOfferSearch a with(nolock) where ISPUBLISHED=2 and ISPUBLISHED3 and tradingservicetype in(1,3,4)方法一:分步搬移(针对百万数据量)
-----remove data----------
insert into BizOfferSearch_Insert_Temp
select top 2000000 id,0 isinsert from BizOfferSearch a with(no...
分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间) 很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间 这里共享一个脚本 CREATE TABLE #tablespaceinfo ( nameinfo VARCHAR ( 500 ) , rowsinfo BIGINT , reserved分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)
很多时候我们都需要计算数据库中各个表的数据量和每行记录所占用空间
这里共享一个脚本CREATE TA...
我的设备上每秒将2000条数据插入数据库,2个设备总共4000条,当在程序里面直接用insert语句插入时,两个设备同时插入大概总共能插入约2800条左右,数据丢失约1200条左右,测试了很多方法,整理出了两种效果比较明显的解决办法:
方法一:使用Sql Server函数:
1.将数据组合成字串,使用函数将数据插入内存表,后将内存表数据复制到要插入的表。
2.组合成的字符换格式:111|222|333|456,7894,7458|0|1|2014-01-01 12:15:16;1111|2222...
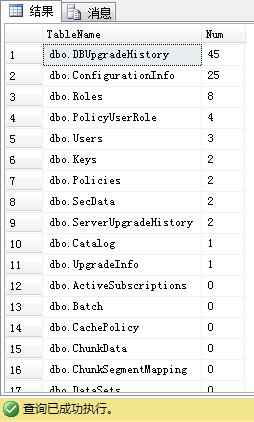
工作过程中,如果一个数据库的表比较多,手工编写统计脚本就会比较繁琐,于是摸索出自动生成各表统计数据量脚本的通用方法,直接上代码:create table #t
(ID int identity(1,1),name nvarchar(200)
)insert into #t(name)
select s.name + . + t.name as TableName
from sys.tables t
inner join sys.schemas s on s.schema_id = t.schema_iddeclare @iCount int = (select count(*) from #t), @i int = 1, @s nvarchar(max) = ...
原文: http://www.d1net.com/bigdata/news/284983.html
1.1:增加次数据文件
从SQL SERVER 2005开始,数据库不默认生成NDF数据文件,一般情况下有一个主数据文件(MDF)就够了,但是有些大型的数据库,由于信息很多,而且查询频繁,所以为了提高查询速度,可以把一些表或者一些表中的部分记录分开存储在不同的数据文件里
由于CPU和内存的速度远大于硬盘的读写速度,所以可以把不同的数据文件放在不同的物理硬盘...