首页 / 更多教程 / 实践一次有趣的sql优化
实践一次有趣的sql优化
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了实践一次有趣的sql优化,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含9791字,纯文字阅读大概需要14分钟。
内容图文
 课程表
课程表
#课程表 create table Course( c_id int PRIMARY KEY, name varchar(10) )增加 100 条数据
#增加课程表100条数据
DROP PROCEDURE IF EXISTS insert_Course;
DELIMITER $
CREATE PROCEDURE insert_Course()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<=100 DO
INSERT INTO Course(`c_id`,`name`) VALUES(i, CONCAT('语文',i+''));
SET i = i+1;
END WHILE;
END $
CALL insert_Course();
运行耗时
课程数据
#学生表 create table Student( s_id int PRIMARY KEY, name varchar(10) )增加 7W 条数据
#学生表增加70000条数据
DROP PROCEDURE IF EXISTS insert_Student;
DELIMITER $
CREATE PROCEDURE insert_Student()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<=70000 DO
INSERT INTO Student(`s_id`,`name`) VALUES(i, CONCAT('张三',i+''));
SET i = i+1;
END WHILE;
END $
CALL insert_Student();
#成绩表 CREATE table Result( r_id int PRIMARY KEY, s_id int, c_id int, score int )增加 70W 条数据
#成绩表增加70W条数据
DROP PROCEDURE IF EXISTS insert_Result;
DELIMITER $
CREATE PROCEDURE insert_Result()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE sNum INT DEFAULT 1;
DECLARE cNum INT DEFAULT 1;
WHILE i<=700000 DO
if (sNum%70000 = 0) THEN
set sNum = 1;
elseif (cNum%100 = 0) THEN
set cNum = 1;
end if;
INSERT INTO Result(`r_id`,`s_id`,`c_id`,`score`) VALUES(i,sNum ,cNum , (RAND()*99)+1);
SET i = i+1;
SET sNum = sNum+1;
SET cNum = cNum+1;
END WHILE;
END $
CALL insert_Result();
测试
业务需求
查找 语文1 成绩为 100 分的考生
查询语句
#查询语文1考100分的考生 select s.* from Student s where s.s_id in (select s_id from Result r where r.c_id = 1 and r.score = 100)执行时间:0.937s 查询结果:32 位满足条件的学生 用了 0.9s ,来查看下查询计划:
EXPLAIN select s.* from Student s where s.s_id in (select s_id from Result r where r.c_id = 1 and r.score = 100)
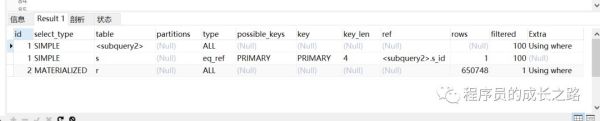 发现没有用到索引,type 全是 ALL ,那么首先想到的就是建立一个索引,建立索引的字段当然是在 where 条件的字段了。
查询结果中 type 列:all 是全表扫描,index 是通过索引扫描。
先给 Result 表的 c_id 和 score 建立个索引
发现没有用到索引,type 全是 ALL ,那么首先想到的就是建立一个索引,建立索引的字段当然是在 where 条件的字段了。
查询结果中 type 列:all 是全表扫描,index 是通过索引扫描。
先给 Result 表的 c_id 和 score 建立个索引
CREATE index result_c_id_index on Result(c_id); CREATE index result_score_index on Result(score);再次执行上述查询语句,时间为:0.027s 快了 34.7 倍(四舍五入),大大缩短了查询的时间,看来索引能极大程度的提高查询效率,在合适的列上面建立索引很有必要,很多时候都忘记建立索引,数据量小的时候没什么感觉,这优化的感觉很 nice 。 相同的 SQL 语句多次执行,你会发现第一次是最久的,后面执行所需的时间会比第一次执行短些许,原因是,相同语句第二次查询会直接从缓存中读取。 0.027s 很短了,但是还能再进行优化吗,仔细看下执行计划:
 查看优化后的 SQL :
查看优化后的 SQL :
SELECT
`example`.`s`.`s_id` AS `s_id`,
`example`.`s`.`name` AS `name`
FROM
`example`.`Student` `s` semi
JOIN ( `example`.`Result` `r` )
WHERE
(
( `example`.`s`.`s_id` = `<subquery2>`.`s_id` )
AND ( `example`.`r`.`score` = 100 )
AND ( `example`.`r`.`c_id` = 1 )
)
怎么查看优化后的语句呢?
方法如下(在命令窗口执行):
#先执行 EXPLAIN select s.* from Student s where s.s_id in (select s_id from Result r where r.c_id = 1 and r.score = 100); #在执行 show warnings;结果如下
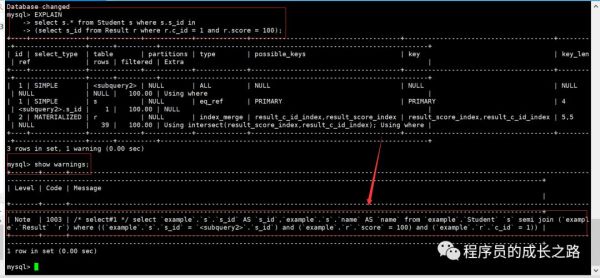 有 type = all
按照之前的想法,该 SQL 执行的顺序是执行子查询
有 type = all
按照之前的想法,该 SQL 执行的顺序是执行子查询
select s_id from Result r where r.c_id = 1 and r.score = 100耗时:1.402s 得到如下结果(部分)
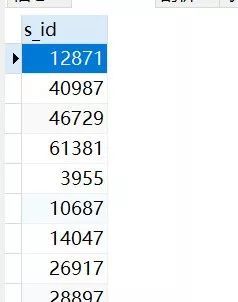 然后在执行
然后在执行
select s.* from Student s where s.s_id in (12871,40987,46729,61381,3955,10687,14047,26917,28897,31174,38896,56518,10774,25030,9778,12544,24721,27295,60361, 38479,46990,66988,6790,35995,46192,47578,58171,63220,6685,67372,46279,64693)耗时:0.222s 比一起执行快多了,查看优化后的 SQL 语句,发现MySQL 竟然不是先执行里层的查询,而是将 SQL 优化成了 exists 字句,执行计划中的 select_type 为 MATERIALIZED(物化子查询)。MySQL 先执行外层查询,在执行里层的查询,这样就要循环学生数量*满足条件的学生 ID 次,也就是 7W * 32 次。 物化子查询: 优化器使用物化能够更有效的来处理子查询。物化通过将子查询结果作为一个临时表来加快查询执行速度,正常来说是在内存中的。mysql 第一次需要子查询结果是,它物化结果到一张临时表中。在之后的任何地方需要该结果集,mysql 会再次引用临时表。优化器也许会使用一个哈希索引来使得查询更快速代价更小。索引是唯一的,排除重复并使得表数据更少。 那么改用连接查询呢? 这里为了重新分析连接查询的情况,先暂时删除索引 result_c_id_index ,result_score_index 。
DROP index result_c_id_index on Result; DROP index result_score_index on Result;连接查询
select s.* from Student s INNER JOIN Result r on r.s_id = s.s_id where r.c_id = 1 and r.score = 100;执行耗时:1.293s 查询结果
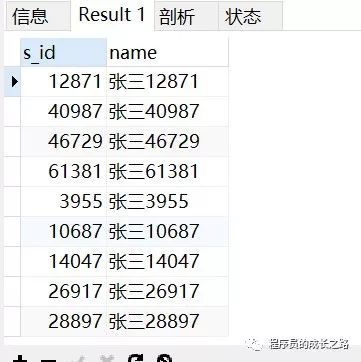 用了 1.2s ,来看看执行计划( EXPLAIN + 查询 SQL 即可查看该 SQL 的执行计划):
用了 1.2s ,来看看执行计划( EXPLAIN + 查询 SQL 即可查看该 SQL 的执行计划):
 这里有连表的情况出现,我猜想是不是要给 result 表的 s_id 建立个索引
这里有连表的情况出现,我猜想是不是要给 result 表的 s_id 建立个索引
CREATE index result_s_id_index on Result(s_id); show index from Result;
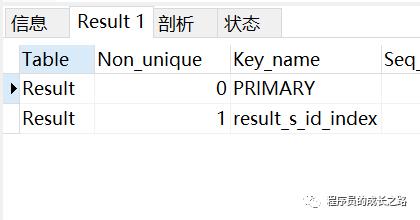 在执行连接查询
耗时:1.17s (有点奇怪,按照所看文章的时间应该会变长的)
看下执行计划:
在执行连接查询
耗时:1.17s (有点奇怪,按照所看文章的时间应该会变长的)
看下执行计划:
 优化后的查询语句为:
优化后的查询语句为:
SELECT
`example`.`s`.`s_id` AS `s_id`,
`example`.`s`.`name` AS `name`
FROM
`example`.`Student` `s`
JOIN `example`.`Result` `r`
WHERE
(
( `example`.`s`.`s_id` = `example`.`r`.`s_id` )
AND ( `example`.`r`.`score` = 100 )
AND ( `example`.`r`.`c_id` = 1 )
)
貌似是先做的连接查询,在进行的 where 条件过滤。
回到前面的执行计划:
这里是先做的 where 条件过滤,再做连表,执行计划还不是固定的,那么我们先看下标准的 sql 执行顺序:
 正常情况下是先 join 再进行 where 过滤,但是我们这里的情况,如果先 join ,将会有 70W 条数据发送 join ,因此先执行 where 过滤式明智方案,现在为了排除 mysql 的查询优化,我自己写一条优化后的 sql 。
先删除索引
正常情况下是先 join 再进行 where 过滤,但是我们这里的情况,如果先 join ,将会有 70W 条数据发送 join ,因此先执行 where 过滤式明智方案,现在为了排除 mysql 的查询优化,我自己写一条优化后的 sql 。
先删除索引
DROP index result_s_id_index on Result;执行自己写的优化 sql
SELECT
s.*
FROM
(
SELECT * FROM Result r WHERE r.c_id = 1 AND r.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id
耗时为:0.413s
比之前 sql 的时间都要短。
查看执行计划
 先提取 result 再连表,这样效率就高多了,现在的问题是提取 result 的时候出现了扫描表,那么现在可以明确需要建立相关索引。
先提取 result 再连表,这样效率就高多了,现在的问题是提取 result 的时候出现了扫描表,那么现在可以明确需要建立相关索引。
CREATE index result_c_id_index on Result(c_id); CREATE index result_score_index on Result(score);再次执行查询
SELECT
s.*
FROM
(
SELECT * FROM Result r WHERE r.c_id = 1 AND r.score = 100
) t
INNER JOIN Student s ON t.s_id = s.s_id
耗时为:0.044s
这个时间相当靠谱,快了 10 倍。
执行计划:
 我们会看到,先提取 result ,再连表,都用到了索引。
那么再来执行下 sql :
我们会看到,先提取 result ,再连表,都用到了索引。
那么再来执行下 sql :
EXPLAIN select s.* from Student s INNER JOIN Result r on r.s_id = s.s_id where r.c_id = 1 and r.score = 100;执行耗时:0.050s 执行计划:
 这里是 mysql 进行了查询语句优化,先执行了 where 过滤,再执行连接操作,且都用到了索引。
扩大测试数据,调整内容为 result 表的数据增长到 300W ,学生数据更为分散。
这里是 mysql 进行了查询语句优化,先执行了 where 过滤,再执行连接操作,且都用到了索引。
扩大测试数据,调整内容为 result 表的数据增长到 300W ,学生数据更为分散。
DROP PROCEDURE IF EXISTS insert_Result_TO300W;
DELIMITER $
CREATE PROCEDURE insert_Result_TO300W()
BEGIN
DECLARE i INT DEFAULT 700001;
DECLARE sNum INT DEFAULT 1;
DECLARE cNum INT DEFAULT 1;
WHILE i<=3000000 DO
INSERT INTO Result(`r_id`,`s_id`,`c_id`,`score`)
VALUES(i,(RAND()*69999)+1 ,(RAND()*99)+1 , (RAND()*99)+1);
SET i = i+1;
END WHILE;
END $
CALL insert_Result_TO300W();
更换了一下数据生成的方式,全部采用随机数格式。
先回顾下:
show index from Result;
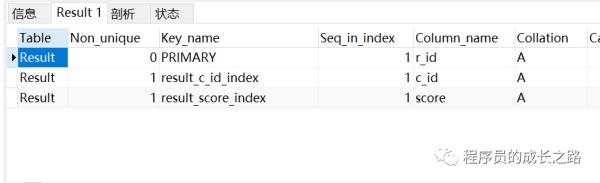 执行 sql
执行 sql
select s.* from Student s INNER JOIN Result r on r.s_id = s.s_id where r.c_id = 81 and r.score = 84;执行耗时:1.278s 执行计划:
 这里用到了 intersect 并集操作,即两个索引同时检索的结果再求并集,再看字段 score 和 c_id 的区分度,但从一个字段看,区分度都不是很大,从 Result 表检索,c_id = 81 检索的结果是 81 ,score = 84 的结果是 84 。
而 c_id = 81 and score = 84 的结果是 19881,即这两个字段联合起来的区分度还是比较高的,因此建立联合索引查询效率将会更高,从另外一个角度看,该表的数据是 300W ,以后会更多,就索引存储而言,都是不小的数目,随着数据量的增加,索引就不能全部加载到内存,而是要从磁盘读取,这样索引的个数越多,读磁盘的开销就越大,因此根据具体业务情况建立多列的联合索引是必要的,我们来试试。
这里用到了 intersect 并集操作,即两个索引同时检索的结果再求并集,再看字段 score 和 c_id 的区分度,但从一个字段看,区分度都不是很大,从 Result 表检索,c_id = 81 检索的结果是 81 ,score = 84 的结果是 84 。
而 c_id = 81 and score = 84 的结果是 19881,即这两个字段联合起来的区分度还是比较高的,因此建立联合索引查询效率将会更高,从另外一个角度看,该表的数据是 300W ,以后会更多,就索引存储而言,都是不小的数目,随着数据量的增加,索引就不能全部加载到内存,而是要从磁盘读取,这样索引的个数越多,读磁盘的开销就越大,因此根据具体业务情况建立多列的联合索引是必要的,我们来试试。
DROP index result_c_id_index on Result; DROP index result_score_index on Result; CREATE index result_c_id_score_index on Result(c_id,score);指向上述查询语句 消耗时间:0.025s 这个速度就就很快了,可以接受。
 该语句的优化暂时告一段落。
总结
该语句的优化暂时告一段落。
总结
- MySQL 嵌套子查询效率确实比较低
- 可以将其优化成连接查询
- 连接表时,可以先用 where 条件对表进行过滤,然后做表连接(虽然 MySQL 会对连表语句做优化)
- 建立合适的索引,必要时建立多列联合索引
- 学会分析 sql 执行计划,mysql 会对 sql 进行优化,所有分析计划很重要
索引优化
上面讲到子查询的优化,以及如何建立索引,而且在多个字段索引时,分别对字段建立了单个索引。 后面发现其实建立联合索引效率会更高,尤其是在数据量较大,单个列区分度不高的情况下。单列索引
查询语句如下:select * from user_test_copy where sex = 2 and type = 2 and age = 10索引:
CREATE index user_test_index_sex on user_test_copy(sex); CREATE index user_test_index_type on user_test_copy(type); CREATE index user_test_index_age on user_test_copy(age);分别对 sex ,type ,age 字段做了索引,数据量为300w 查询时间:0.415s 执行计划:
 发现 type = index_merge
这是mysql对多个单列索引的优化,对结果集采用intersect并集操作
发现 type = index_merge
这是mysql对多个单列索引的优化,对结果集采用intersect并集操作
多列索引
多列索引 我们可以在这3个列上建立多列索引,将表copy一份以便做测试。create index user_test_index_sex_type_age on user_test(sex,type,age);查询语句:
select * from user_test where sex = 2 and type = 2 and age = 10执行时间:0.032s 快了10多倍,且多列索引的区分度越高,提高的速度也越多。 执行计划:

最左前缀
多列索引还有最左前缀的特性: 都会使用到索引,即索引的第一个字段sex要出现在where条件中。 执行一下语句:select * from user_test where sex = 2 select * from user_test where sex = 2 and type = 2 select * from user_test where sex = 2 and age = 10
索引覆盖
就是查询的列都建立了索引,这样在获取结果集的时候不用再去磁盘获取其它列的数据,直接返回索引数据即可 如:select sex,type,age from user_test where sex = 2 and type = 2 and age = 10执行时间:0.003s 要比取所有字段快的多
排序
select * from user_test where sex = 2 and type = 2 ORDER BY user_name时间:0.139s 在排序字段上建立索引会提高排序的效率
select * from user_test where sex = 2 and type = 2 ORDER BY user_name最后附上一些sql调优的总结,以后有时间再深入研究
- 列类型尽量定义成数值类型,且长度尽可能短,如主键和外键,类型字段等等
- 建立单列索引
- 根据需要建立多列联合索引
- 当单个列过滤之后还有很多数据,那么索引的效率将会比较低,即列的区分度较低,那么如果在多个列上建立索引,那么多个列的区分度就大多了,将会有显著的效率提高。
- 根据业务场景建立覆盖索引
- 只查询业务需要的字段,如果这些字段被索引覆盖,将极大的提高查询效率
- 多表连接的字段上需要建立索引
- 这样可以极大的提高表连接的效率
- where条件字段上需要建立索引
- 排序字段上需要建立索引
- 分组字段上需要建立索引
- Where条件上不要使用运算函数,以免索引失效
·END·
内容总结
以上是互联网集市为您收集整理的实践一次有趣的sql优化全部内容,希望文章能够帮你解决实践一次有趣的sql优化所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】