C语言小知识(基于Linux)——个人笔记,不定时更新
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了C语言小知识(基于Linux)——个人笔记,不定时更新,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3979字,纯文字阅读大概需要6分钟。
内容图文
——个人笔记,不定时更新")
一、switch case语法,在case中定义变量时,需要在case的有效范围内使用花括号包起来,否则会编译报错;
switch (name){
case "zhangSan":{
int age = 13;
break;
}
case "liSi":{
int age = 14;
break;
}
default:{
break;
}
}
二、规定结构体以n字节对齐
在C语言结构体中,字节对齐方式默认为最大类型字节对齐;比如:
struct Class{
char age;
int id;
}class;
这个结构体有两个成员,分别为1字节的age与4字节的id(32位编译时);实际占用了5个字节的空间,但是此时sizeof(class) == 8;因为最大的成员 id 占了4个字节,所以会以4字节对齐;age就会补充3个字节的保留位来字节对齐。
但是在数据流的处理中,为节约资源,一般每个字节甚至每个bit都需物尽其用;所以上述结构只需要5字节有效空间;
此时就可以使用#pragma pack(n)来进行n字节对齐;
#pragma pack(1)
struct Class{
char age;
int id;
}class;
#pragma pack()
现在sizeof(class)就会等于5了;age只占1字节;在结构体之后加上#pragma pack()是为了限制1字节对齐的范围;#pragma pack()之后的数据结构又会以默认最大成员类型来进行字节对齐;
三、结构中按bit定义变量
可以在定义变量时,变量名之后,分号;之前 加上 : n 来规定此变量占用的位数;
#pragma pack(1)
struct ZhangSan{
unsigned char gender_flag : 1;
unsigned char age : 7;
unsigned short height : 6;
unsigned short weight : 6;
unsigned short id : 4;
}zhangSan;
#pragma pack()
此时gender_flag 成员与age 成员就共用一个字节的空间,height 与 weight 与 id 共用两个字节的空间;sizeof(zhangSan) == 3;
四、数据大小端
1.位序
有如下结构:
struct ZhangSan{
unsigned char gender_flag : 1;
unsigned char age : 7;
}zhangSan;
其中 gender_flag 与 age 共用了一个字节(8bit)的空间,一个占1bit,一个占7bit;但是bit占的位置却是与平台相关的;就有可能出现如下两种排列情况:
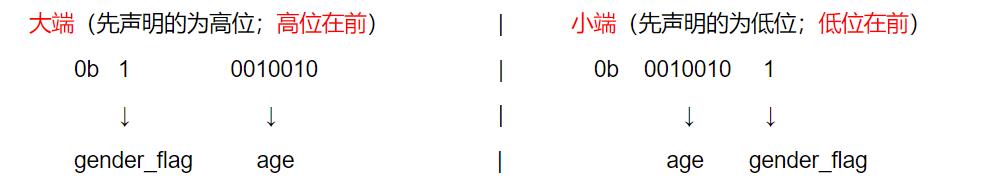
为了解决这种差异化,一般规定传输时的位序都为大端;即在基本类型里声明多个位域时,每个位域看做一个整体,先声明的排在前面,后声明的排在后面;在声明结构体时就可以依据本机的位序来声明位域,从而在接收数据流时能顺利的取出每一个位域。
Linux系统中一般可以通过判断是否定义了宏 __LITTLE_ENDIAN_BITFIELD 与 __BIG_ENDIAN_BITFIELD 来区分当前的位序定义;
若这两个宏同时都没有定义,还可以添加 对字节序的判断来得出本机的位序定义,如下:
#if !defined(__LITTLE_ENDIAN_BITFIELD) && !defined(__BIG_ENDIAN_BITFIELD)
#if (__BYTE_ORDER__==__ORDER_LITTLE_ENDIAN__)
#define __LITTLE_ENDIAN_BITFIELD
#elif (__BYTE_ORDER__==__ORDER_BIG_ENDIAN__)
#define __BIG_ENDIAN_BITFIELD
#endif
#endif
struct ZhangSan{
#if defined(__LITTLE_ENDIAN_BITFIELD)
unsigned char gender_flag : 1;
unsigned char age : 7;
#elif defined(__BIG_ENDIAN_BITFIELD)
unsigned char age : 7;
unsigned char gender_flag : 1;
#endif
}zhangSan;
加了如上修饰之后,即可保证接收到的大端数据流中的位域都能成功的映射到本机所定义的位域;
2.字节序
在数据流跨平台的传递中,经常会遇到大小端不对齐的情况;比如一个int数据在大端机器中的存储方式是高位在前,低位在后,
比如0x33224411在内存中的存放方式就是先存0x33,再存0x22,以此类推。如下:
buf[0] = 0x33; buf[1] = 0x22; buf[2] = 0x44; buf[3] = 0x11;
而小端平台就刚好相反,是低位在前,高位在后;同样的数据0x33224411在小端中的存放方式就是先存0x11,再存0x44,以此类推。如下:
buf[0] = 0x11; buf[1] = 0x44; buf[2] = 0x22; buf[3] = 0x33;
为了使数据统一,所以一般规定了在网络中传输的数据都以大端模式传递,收到数据之后再把数据从大端模式转为本机的模式即可正常使用;
在linux系统的#include <endian.h>中提供了一系类字节序转换的函数:
#include <endian.h> // 将主机字节序转换为大端字节序 uint16_t htobe16(uint16_t host_16bits); uint32_t htobe32(uint32_t host_32bits); uint64_t htobe64(uint64_t host_64bits); // 将主机字节序转换为小端字节序 uint16_t htole16(uint16_t host_16bits); uint32_t htole32(uint32_t host_32bits); uint64_t htole64(uint64_t host_64bits); // 将大端字节序转换为主机字节序 uint16_t be16toh(uint16_t big_endian_16bits); uint32_t be32toh(uint32_t big_endian_32bits); uint64_t be64toh(uint64_t big_endian_64bits); // 将小端字节序转换为主机字节序 uint16_t le16toh(uint16_t little_endian_16bits); uint32_t le32toh(uint32_t little_endian_32bits); uint64_t le64toh(uint64_t little_endian_64bits);
内容总结
以上是互联网集市为您收集整理的C语言小知识(基于Linux)——个人笔记,不定时更新全部内容,希望文章能够帮你解决C语言小知识(基于Linux)——个人笔记,不定时更新所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。