首页 / LINUX / 03--Linux grep 命令
03--Linux grep 命令
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了03--Linux grep 命令,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4553字,纯文字阅读大概需要7分钟。
内容图文

Grep 是 Global Regular Expression Print 的缩写。搜索指定文件的内容。
语法
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
常用选项
--help
-V, --version
-G, --basic-regexp BRE 模式,也是默认的模式
-E, --extended-regexp ERE 模式
-P, --perl-regexp PRE 模式
-F, --fixed-strings 指定的模式被解释为字符串
-i 忽略大小写
-o 只输出匹配到的部分(而不是整个行)
-v 反向选择,即输出没有没有匹配的行
-c 计算找到的符号行的次数
-n 顺便输出行号
# 常见用例
## 递归目录中的所有文件

grep -r 'world' ~/projects/
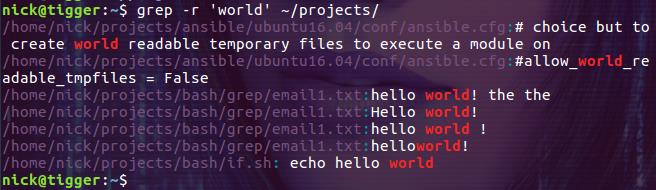
-d recurse 选项可以实现同样的功能如下:
$ grep 'world' -d recurse ~/projects/
一般情况下使用下面的命令(-n 显示行号,-w 表示匹配全词):
$ grep -rnw 'path' -e 'pattern'
## 在递归的过程中只输出匹配内容所在的文件名称如下:
如果我们只想查看匹配到的内容所在文件的名称,可以同时使用 r 和 -l, --files-with-matches 选项:
$ grep -rl email /home/nick/projects/bash/.git

## 在递归的过程中排除某些目录
可以在应用选项 r 的同时应用 --exclude-dir 选项来排除一些目录(注意,这里设置的也是正则表达式)如下:
$ grep -r --exclude-dir='.git' 'email' .
指定多个表达式如下:
$ grep -r --exclude-dir={.git,xgit} 'email' .
## 在递归的过程中排除指定的文件
可以在应用选项 r 的同时应用 --exclude 选项来排除一些文件(注意,这里采用的是 GLOB模式):
$ grep -r --exclude=*.txt 'email' .
不区分大小写
Grep 默认的匹配规则区分字符的大小写,使用选项 -i (小写字母i),会在匹配中忽略字符大小写如下:
$ grep -i 'hello' email1

## 只输出匹配到的部分(而不是整个行)
Grep 默认会输出匹配到的内容所在的整个行,使用选项 -o, --only-matching 则只输出匹配到的内容如下:
$ echo "abc 123 test" | grep -o '[0-9]\{1,3\}'
输出的结果为:123
在需要把匹配的内容存入变量时 -o 选项非常有用,比如下面的示例把从文件中匹配到的 IP 地址保存在变量 ip 中如下:
ip=$(grep -o '[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}' file.log)
if test -z "${ip}"; then
exit 1
fi
echo ${ip}
## 把匹配条件当成一个字符串
有时候我们想要匹配一个固定的字符串,但是其中包含了特殊字符,比如
$ grep '.*' email1.txt
这样的条件会返回文件中的每一行内容,这不是我们想要的。可以通过转义符来解决这个问题:
$ grep '\.\*' email1.txt
当然,我们还可以通过选项 F 来优美的解决这个问题,此时指定的条件会被当成一个字符串来匹配
$ grep -F '.*' email1.txt

## 同时输出匹配行后的 n 行
使用选项 -A n 可以输出匹配行后的 n 行,结合 ps 命令,可以用来查找某个进程的子进程。下面的例子通过 -A 1 输出容器运行的进程(bash):
$ ps fxa | grep -A 1 docker
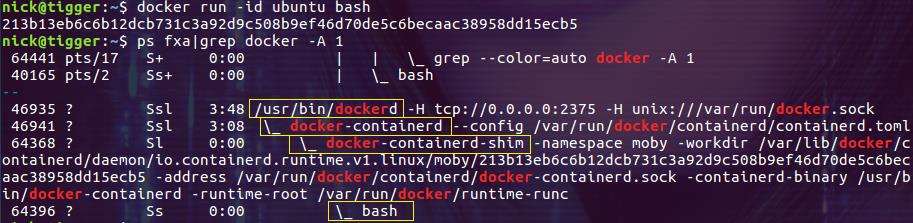
## 同时输出匹配行前后的行
有时我们想要看到匹配行的前后行的内容,使用选项 -C n 可以实现这个功能,比如下面的命令会同时输出匹配行前后 1 行的内容:
$ grep -C 1 'grey' email1.txt

## 在输出中显示行号
使用选 -n 可以在输出中显示行号:
grep -n 'hello' email.txt
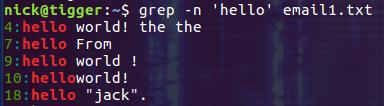
## 统计匹配到的行的数量
使用选项 -c 可以统计匹配到的行的数量:
grep -C 'hello' email.txt

## 反转匹配条件
如果我们想要获取正则表达式没有匹配到的行,可以使用选项 -v, --invert-match:
$ grep -v '^[a-zA-Z].*' email1.txt
## 只匹配完整的行
如果我们只对一个完整的行感兴趣,可以使用选项 -x, --line-regexp。这样会忽略那些包含在行中的内容:
$ grep -x 'hello world' email.txt

## 从文件中读取正则表达式
如果正则表达式太长,或者是需要指定多个正则表达式,可以把它们放在文件中,然后使用 选项 -f FILE, --file=FILE 来指定这个文件。如果指定了多个正则表达式(每行一个),任何一个匹配到的结果都会被输出:
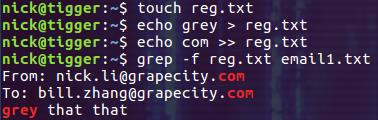
BRE(basic regular expression)
| 语法 | 说明 | 解释 |
| . | 匹配一个任意的字符 | 在 [] 中 . 号并不是元字符 |
| ^ | 行的起始 | ^ 和 $ 匹配的是一个位置而不是具体的文本 |
| $ | 行的结束 | ^ 和 $ 匹配的是一个位置而不是具体的文本 |
| * | 匹配 0 次或多次 | 不匹配上一次表达式,匹配上一次或匹配多次,并生成所有可能的匹配 匹配尽可能多的次数,如果实在无法匹配,也不要紧 |
| [] | 匹配若干个字符之一 | 又叫字符组、字符类,比如 [0-9]、[a-z]、[A-Z] 只有在字符组内部 - 才是元字符,表示一个范围 |
| [^...] | 排除型字符组 | 字符组以 ^ 开头,它会匹配一个任何未列出的字符 |
| \? | 可选元素 | 在 BRE 中需要使用转义符 \ 出现一次或者不出现 |
| \+ | 匹配 1 次或多次 | 在 BRE 中需要使用转义符 \ 匹配前面表达式的至少一个搜索项 匹配尽可能多的次数,如果实在无法匹配,也不要紧 |
| \{min,max\} | 量词区间 | 在 BRE 中需要使用转义符 \ |
| \| | 或(多选结构) | 在 BRE 中需要使用转义符 \ bob\|nick 能够同时匹配其中任意一个的正则表达式,此时的子表达式被称为 "多选分支" 多选结构可以包括很多字符,但不能超越括号的界限 |
| \(\) | 分组 | 在 BRE 中需要使用转义符 \ 括号能够 "记住" 它们包含的子表达式匹配的文本 反向引用(backreference)是正则表达式的特性之一,它允许我们匹配与表达式先前部分匹配的同样的文本 |
| \<\> | 单词分界符 | 在 BRE 中需要使用转义符 \ < 和 > 本身并不是源字符,只有它们与反斜线结合时才具有单词分界符的含义 |
| \ | 转义符 | 如果需要匹配的某个字符本身就是元字符,就需要使用转义符 |
| 命名的字符类 | 命名的预定义字符类 | [[:upper:]] [A-Z] [[:lower:]] [a-z] [[:digit:]] [0-9] [[:alnum:]] [0-9a-zA-Z] [[:space:]] 空格或 tab [[:alpha:]] [a-zA-Z] |
内容总结
以上是互联网集市为您收集整理的03--Linux grep 命令全部内容,希望文章能够帮你解决03--Linux grep 命令所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。