清华学霸告诉你一款能取代 Scrapy 的爬虫框架 feapder
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了清华学霸告诉你一款能取代 Scrapy 的爬虫框架 feapder,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4338字,纯文字阅读大概需要7分钟。
内容图文

Python 最流行的爬虫框架是 Scrapy,它主要用于爬取网站结构性数据
今天推荐一款更加简单、轻量级,且功能强大的爬虫框架
介绍及安装
和 Scrapy 类似,feapder 支持轻量级爬虫、分布式爬虫、批次爬虫、爬虫报警机制等功能
内置的 3 种爬虫如下:
-
AirSpider
轻量级爬虫,适合简单场景、数据量少的爬虫
-
Spider
分布式爬虫,基于 Redis,适用于海量数据,并且支持断点续爬、自动数据入库等功能
-
BatchSpider
分布式批次爬虫,主要用于需要周期性采集的爬虫
在实战之前,我们在虚拟环境下安装对应的依赖库
# 安装依赖 pip3 install feapder
我们以最简单的 AirSpider 来爬取一些简单的数据
详细实现步骤如下( 5 步)
创建爬虫项目
首先,我们使用「 feapder create -p 」命令创建一个爬虫项目

创建爬虫 AirSpider
命令行进入到 spiders 文件夹目录下,使用「 feapder create -s 」命令创建一个爬虫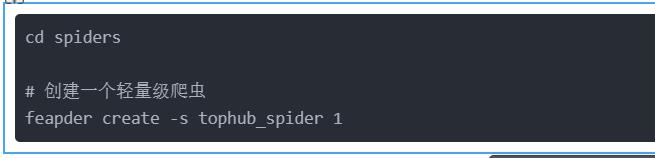
其中
-
1 为默认,表示创建一个轻量级爬虫 AirSpider
-
2 代表创建一个分布式爬虫 Spider
-
3 代表创建一个分布式批次爬虫 BatchSpider
配置数据库、创建数据表、创建映射 Item
以 Mysql 为例,首先我们在数据库中创建一张数据表
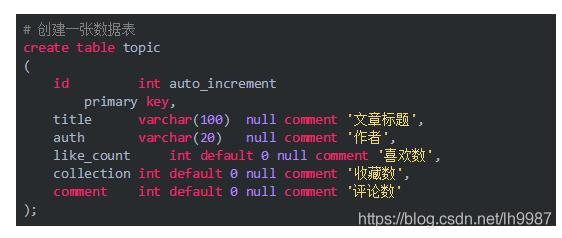
然后,打开项目根目录下的 settings.py 文件,配置数据库连接信息
#?settings.py
MYSQL_IP?=?"localhost"
MYSQL_PORT?=?3306
MYSQL_DB?=?"xag"
MYSQL_USER_NAME?=?"root"
MYSQL_USER_PASS?=?"root"
最后,创建映射 Item( 可选 )
进入到 items 文件夹,使用「 feapder create -i 」命令创建一个文件映射到数据库
PS:由于 AirSpider 不支持数据自动入库,所以这步不是必须
编写爬虫及数据解析
第一步,首先使「 MysqlDB 」初始化数据库
from?feapder.db.mysqldb?import?MysqlDB
class?TophubSpider(feapder.AirSpider):
????def?__init__(self,?*args,?**kwargs):
????????super().__init__(*args,?**kwargs)
????????self.db?=?MysqlDB()
第二步,在 start_requests 方法中,指定爬取主链接地址,使用关键字「download_midware 」配置随机 UA
import?feapder
from?fake_useragent?import?UserAgent
def?start_requests(self):
????yield?feapder.Request("https://tophub.today/",?download_midware=self.download_midware)
def?download_midware(self,?request):
????#?随机UA
????#?依赖:pip3 install fake_useragent
????ua?=?UserAgent().random
????request.headers?=?{'User-Agent':?ua}
????return?request
第三步,爬取首页标题、链接地址
使用 feapder 内置方法 xpath 去解析数据即可
def?parse(self,?request,?response):
????#?print(response.text)
????card_elements?=?response.xpath('//div[@class="cc-cd"]')
????#?过滤出对应的卡片元素【什么值得买】
????buy_good_element?=?[card_element?for?card_element?in?card_elements?if
????????????????????????card_element.xpath('.//div[@class="cc-cd-is"]//span/text()').extract_first()?==?'什么值得买'][0]
????#?获取内部文章标题及地址
????a_elements?=?buy_good_element.xpath('.//div[@class="cc-cd-cb?nano"]//a')
????for?a_element?in?a_elements:
????????#?标题和链接
????????title?=?a_element.xpath('.//span[@class="t"]/text()').extract_first()
????????href?=?a_element.xpath('.//@href').extract_first()
????????#?再次下发新任务,并带上文章标题
????????yield?feapder.Request(href,?download_midware=self.download_midware,?callback=self.parser_detail_page,
??????????????????????????????title=title)
第四步,爬取详情页面数据
上一步下发新的任务,通过关键字「 callback 」指定回调函数,最后在 parser_detail_page 中对详情页面进行数据解析
def?parser_detail_page(self,?request,?response):
????"""
????解析文章详情数据
????:param?request:
????:param?response:
????:return:
????"""
????title?=?request.title
????url?=?request.url
????#?解析文章详情页面,获取点赞、收藏、评论数目及作者名称
????author?=?response.xpath('//a[@class="author-title"]/text()').extract_first().strip()
????print("作者:",?author,?'文章标题:',?title,?"地址:",?url)
????desc_elements?=?response.xpath('//span[@class="xilie"]/span')
????print("desc数目:",?len(desc_elements))
????#?点赞
????like_count?=?int(re.findall('\d+',?desc_elements[1].xpath('./text()').extract_first())[0])
????#?收藏
????collection_count?=?int(re.findall('\d+',?desc_elements[2].xpath('./text()').extract_first())[0])
????#?评论
????comment_count?=?int(re.findall('\d+',?desc_elements[3].xpath('./text()').extract_first())[0])
????print("点赞:",?like_count,?"收藏:",?collection_count,?"评论:",?comment_count)
数据入库
使用上面实例化的数据库对象执行 SQL,将数据插入到数据库中即可
#?插入数据库
sql?=?"INSERT?INTO?topic(title,auth,like_count,collection,comment)?values('%s','%s','%s','%d','%d')"?%?(
title,?author,?like_count,?collection_count,?comment_count)
#?执行
self.db.execute(sql)最后
本篇文章通过一个简单的实例,聊到了 feapder 中最简单的爬虫 AirSpider
若需要相关爬虫资料的可以扫一扫 备注【爬虫】

内容总结
以上是互联网集市为您收集整理的清华学霸告诉你一款能取代 Scrapy 的爬虫框架 feapder全部内容,希望文章能够帮你解决清华学霸告诉你一款能取代 Scrapy 的爬虫框架 feapder所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。