首页 / C语言 / 文学研究助手【C语言实现】数据结构实验
文学研究助手【C语言实现】数据结构实验
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了文学研究助手【C语言实现】数据结构实验,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3812字,纯文字阅读大概需要6分钟。
内容图文

目录
文学研究助手【C语言实现】->数据结构实验
数据结构实验:文学研究助手【C语言实现】
实验内容
文学研究人员需要统计某篇英语小说中某些特定单词的出现次数和位置。设计一个实现此目标的文字统计系统。
英文小说存放于一文本文件中,待统计的词汇集合要一次输入完毕,程序的输出结果是每个词的出现次数和出现位置所在行的行号,格式自行设计。
实验要求
约定小说的词汇一律不跨行。这样,每读入一行,就统计每个词在这行中的出现次数。
出现位置所在行的行号可以用链表存储。若某行中出现了不只一次,不必存多个相同的行号
测试数据
以自己的 C 源程序模拟英文小说,C 语言的保留字作为待统计的词汇集。
关键代码
文件读取与输出函数
char *FileRead(char ch[]) {
FILE *fp;
char *c = (char *)malloc(20000*sizeof(char));
char str[20000];
if( (fp=fopen(ch,"rt")) == NULL ) {
puts("文件打开失败或文件路径错误!!!");
exit(0);
}
/*拷贝文件中的字符串到数组str,并打印str*/
while(fgets(str, 20000, fp) != NULL) {
printf("%s", str);
}
fclose(fp);
return c;
}
统计文本文件中给定单词的数量
/*统计文本文件中给定单词的数量*/
int count(char * word) {
FILE * fp;
char ch,w[20];
int j = 0,num = 0;
//打开文件
if((fp = fopen(file_path,"r")) == NULL) {
printf("无法打开文件或文件路径错误!!!\n");
return 0;
}
//只要文件不结束,就一直判断
while(!feof(fp)) {
//取文件中的每个单词
ch = fgetc(fp);
j = 0;
//只要不是空格或转行或() {} [] , ; 等,其所遇到的字母都隶属于一个单词
while(ch != ' ' && ch != '\n' &&ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' && ch !=',' && ch != ';'&& !feof(fp)) { //ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' &&ch != '"' && ch !='\''
w[j++] = ch;
ch = fgetc(fp);
}
//给单词的最后添加结束符,防止各个单词的长度不同,导致从数组读取单词时多读的现象发生
w[j] = '\0';
//判断每个单词是否与给定单词相同,若相同,则计数变量num +1
if(strcmp(w,word) == 0) {
num++;
}
}
//最终返回计数变量 num 的值
return num;
}
检索并输出给定单词所在行号、在该行中出现的次数以及各自的具体位置
/*检索并输出给定单词所在行号、在该行中出现的次数以及各自的具体位置*/
void search(char * word) {
FILE * fp;
char ch,w[20];
int j = 0,num = 0,row = 1,col[200],i = 0,k;
//尝试打开文本文件
if((fp = fopen(file_path,"r")) == NULL) {
printf("cannot open file\n");
return;
}
//遍历文本文件中的每个单词
while(!feof(fp)) {
ch = fgetc(fp);
j = 0, i++;
while(ch != ' ' && ch != '\n' &&ch != '(' && ch !=')' &&ch != '{' && ch !='}' &&ch != '[' && ch !=']' && ch !=',' && ch != ';'&& !feof(fp)) {
w[j++] = ch;
ch = fgetc(fp);
i++;
}
w[j]='\0';
//判断每个单词与给定单词是否相等
if(strcmp(w,word) == 0) {
//如果相同,记录该单词在该行中的位置,同时计数变量 num+1
col[num] = i-j,
num++;
}
//如果遇到转行或者文件结束,则输出该行中单词的数量以及相应位置
if(ch == '\n' || feof(fp)) {
if(num) {
printf("第%d行出现了%d次,位置分别是:[ ",row,num);
for(k = 0 ; k < num; k++) {
printf(" %d",col[k]);
if (k != num-1) printf(",");
}
printf("]\n");
}
//转行,row +1,同时 i 和 num 都清零
row ++;
i = 0;
num = 0;
}
}
}
备注
备注:运行程序之前,我已经提前将2个txt文本文件放入D盘根目录。也可以放入其他目录,但是请注意文件路径为全英文路径,不能有中文等奇怪的,要不然会报一些无法预料的错误。
其中,我在c.txt中事先放入源代码(尽量不要出现中文注释),用于读入统计,当然你也可以拷贝一篇英语文章到c.txt。
我在d.txt里放了C语言的保留字用于统计这些保留字在源文件中出现的次数。每个保留字独占一行。如图
运行结果
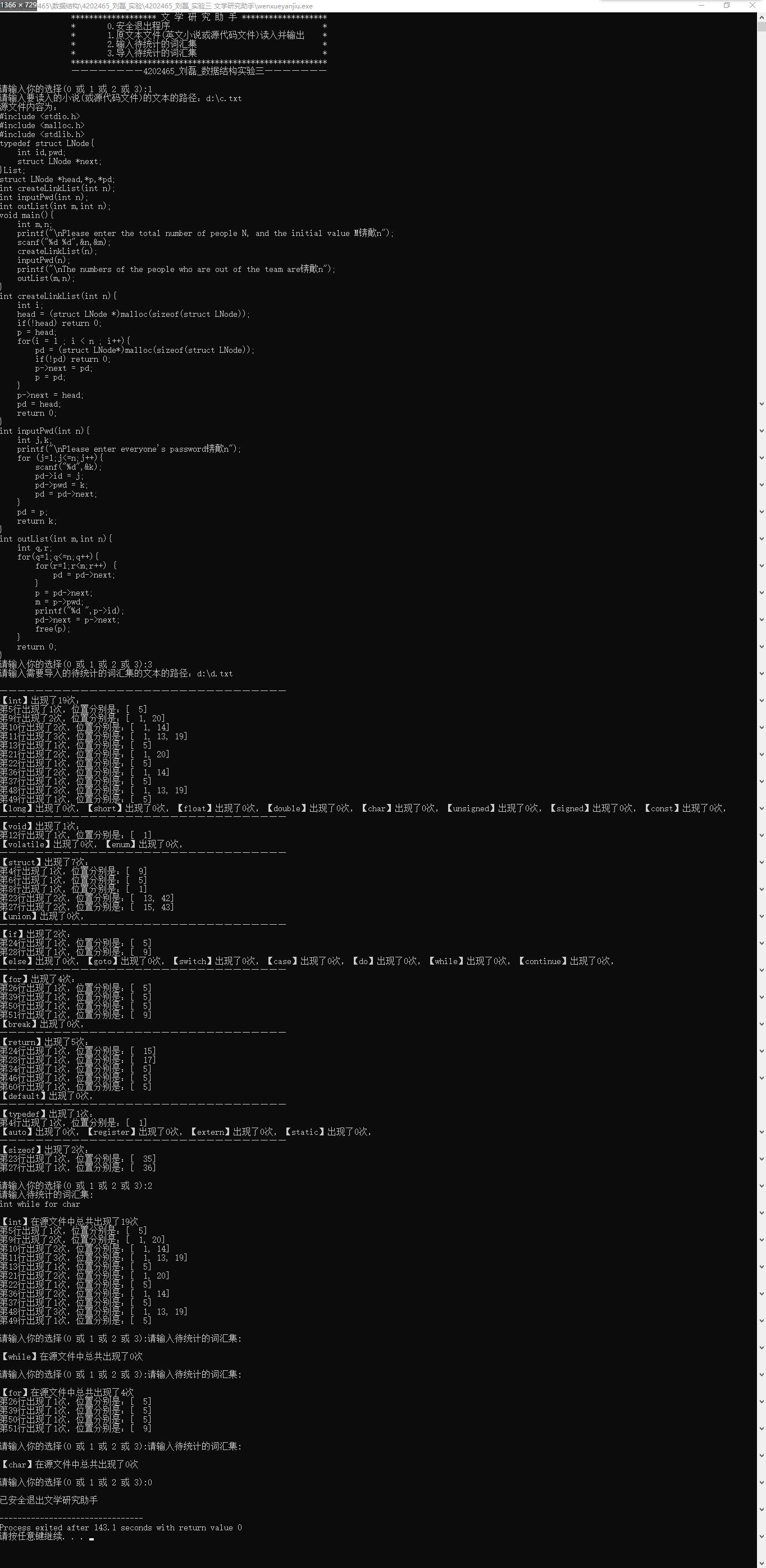
其他补充说明
- 对于待统计的词汇集,可以让用户通过键盘输入多个待统计的词汇集,也可以读取待统计的词汇集单词来获取保留字并一一进行统计和位置查找。
- FileRead 函数设计时将文本文件中的字符串读入字符数组时,字符数组长度应尽量大一些。打印输出字符数组即源文件内容。
- count 函数中,取文件中的每个单词,除了考虑单词前的空格符换行符外,还应考虑单词前可能出现的逗号和(括号等等符号。 通过库函数 strcmp()来判断每个单词是否与给定单词相同,若相同,则计数变量 num +1
- search 函数遍历文本文件中的每个单词时,记录与给定单词相同的单词的所在行和列.
- 代码似乎挺low的,还请各位指教。
内容总结
以上是互联网集市为您收集整理的文学研究助手【C语言实现】数据结构实验全部内容,希望文章能够帮你解决文学研究助手【C语言实现】数据结构实验所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。