tensorflow(三十八):Batch Normalization
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了tensorflow(三十八):Batch Normalization,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1212字,纯文字阅读大概需要2分钟。
内容图文
:Batch Normalization")
一、不进行归一化,某些W变化对loss影响较大
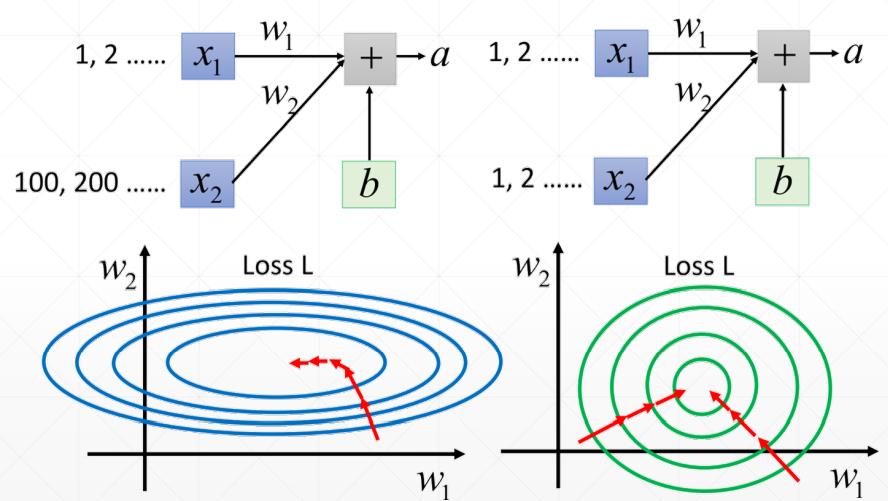
二、进行归一化
1、可以看到,Batch Norm结束后,只得到三个数值,每个通道一个。

2、正常的Batch Norm过后,均值为0,方差为1,但是需要再加一个贝塔和伽马。(B,r)需要学出来。


变成了均值为B,方差为r。
三、用法
1、下面的center是均值B,scale是方差r。最后一个参数用于测试时候。


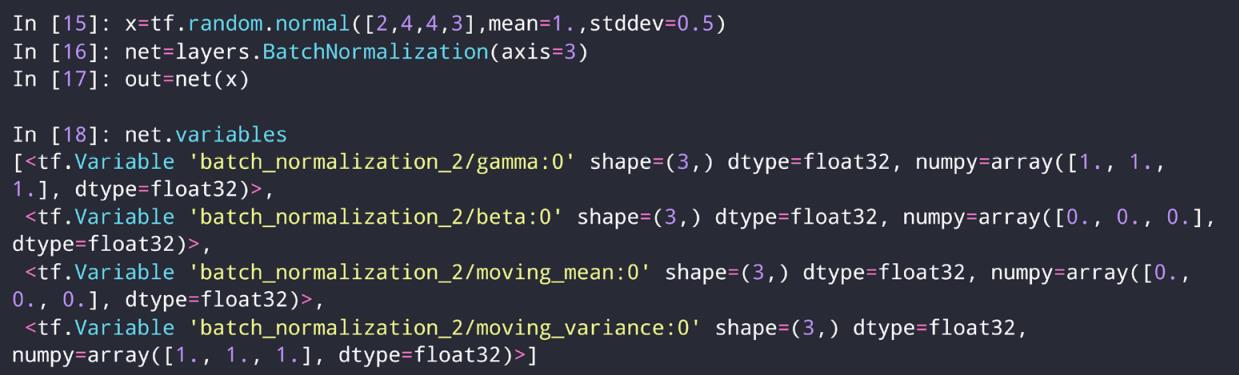
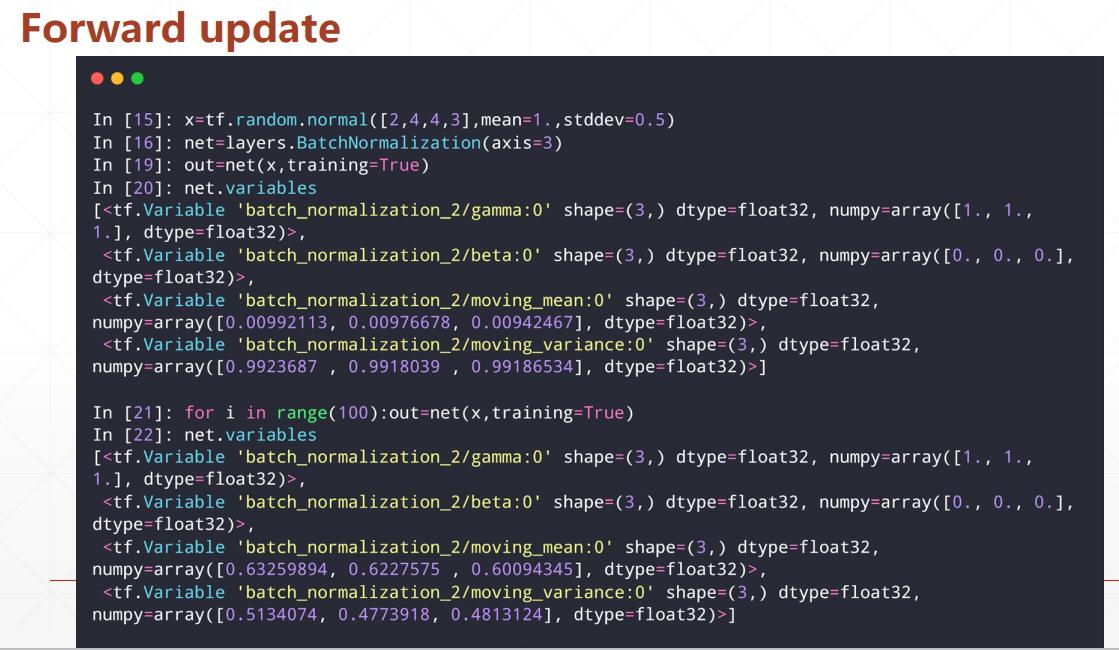


import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers
# 2 images with 4x4 size, 3 channels
# we explicitly enforce the mean and stddev to N(1, 0.5)
x = tf.random.normal([2,4,4,3], mean=1.,stddev=0.5)
net = layers.BatchNormalization(axis=-1, center=True, scale=True,
trainable=True)
out = net(x)
print('forward in test mode:', net.variables)
out = net(x, training=True)
print('forward in train mode(1 step):', net.variables)
for i in range(100):
out = net(x, training=True)
print('forward in train mode(100 steps):', net.variables)
optimizer = optimizers.SGD(lr=1e-2)
for i in range(10):
with tf.GradientTape() as tape:
out = net(x, training=True)
loss = tf.reduce_mean(tf.pow(out,2)) - 1
grads = tape.gradient(loss, net.trainable_variables)
optimizer.apply_gradients(zip(grads, net.trainable_variables))
print('backward(10 steps):', net.variables)
内容总结
以上是互联网集市为您收集整理的tensorflow(三十八):Batch Normalization全部内容,希望文章能够帮你解决tensorflow(三十八):Batch Normalization所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】