pandas中Series和Dataframe数据类型互转pandas中series和dataframe数据类型互转利用to_frame()实现Series转DataFrame利用squeeze()实现单列数据DataFrame转Series
s = pd.Series([1,2,3])s0 1
1 2
2 3
dtype: int64s = s.to_frame(name="列名")s
列名011223
s.squeeze()0 1
1 2
2 3
Name: 列名, dtype: int64到这里就结束了,如果对你有帮助,欢迎点赞关注评论,你的点赞对我很重要
Pandas数据处理:导?数据
导出数据
查看数据
数据选取
数据处理
数据分组和排序
数据合并
# 在使用之前,需要导入pandas库
import pandas as pd导?数据:pd.DataFrame() # 自己创建数据框,用于练习pd.read_csv(filename) # 从CSV?件导?数据pd.read_table(filename) # 从限定分隔符的?本?件导?数据pd.read_excel(filename) # 从Excel?件导?数据pd.read_sql(query,connection_object) # 从SQL表/库导?数据pd.read_json(json_string)...
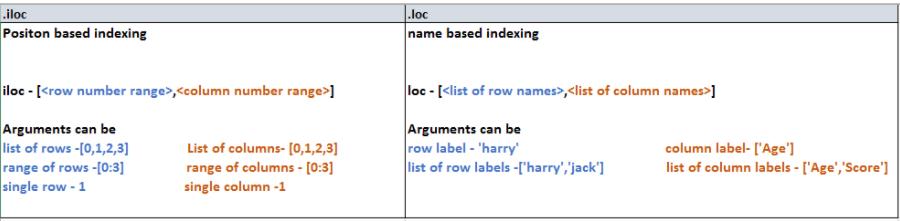
pandas数据索引之loc、iloc、ix详解及实例
先来个总结:
loc函数:通过行索引 "Index" 中的具体值来取行数据(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第二行的数据)
ix函数:这个东东在pandas后来升级的时候被抛弃掉了,因为它多余了,所以我们忘掉它吧!这里面的核心说道就在于:index它有可能不是从0开始到N排布的(强调的是数据块天生的存储类型的索引,而不是人为设定的不按照套路出牌的那一种),...
pandas:数据分析
pandas是一个强大的Python数据分析的工具包。pandas是基于NumPy构建的。
pandas的主要功能具备对其功能的数据结构DataFrame、Series集成时间序列功能提供丰富的数学运算和操作灵活处理缺失数据
安装方法:pip install pandas引用方法:import pandas as pd
pandas:Series
Series是一种类似于一位数组的对象,由一组数据和一组与之相关的数据标签(索引)组成。
创建方式:
pd.Series([4,7,-5,3])pd.Series([4,7,...
什么是pandas
pandas数据读取
03.?Pandas数据结构
encoding: utf-8
import time
import pandas as pd
import pymysqldef getrel(sql):‘‘‘连接mysql数据库,根据条件查询出来我们所需要数据:return: 根据条件从sql查询出来的数据‘‘‘conn = pymysql.connect(host=‘localhost‘, user=‘root‘, password=‘123‘,db=‘db_test‘, charset=‘utf8mb4‘)cur = conn.cursor()cur.execute(sql) # 输入要查询的SQLrel = cur.fetchall()cur.close()conn.close()return reldef getxl...
本文内容是根据 莫烦Python 网站的视频整理的笔记,笔记中对代码的注释更加清晰明了, 同时根据所有笔记还整理了精简版的思维导图, 可在此专栏查看, 想观看视频可直接去他的网站, 源文件已经上传到主页中的资源一栏中,有需要的可以去看看,我主页中的思维导图中内容大多从我的笔记中整理而来,相应技巧可在笔记中查找原题, 有兴趣的可以去 我的主页 了解更多计算机学科的精品思维导图整理本文可以转载,但请注明来处,觉得整理的不错的...
第四章 pandas统计分析基础
4.1读/写不同数据源的数据
4.1.1读/写数据库数据
1、数据库数据读取
import MySQLdbfrom sqlalchemy import create_engine
from sqlalchemy.orm import sessionmakerengine = create_engine("mysql+pymysql://root:123456@127.0.0.1/testdb?charset=utf8mb4")
session = sessionmaker(bind=engine)
print(engine)
print(session)
Engine(mysql+pymysql://root:***@127.0.0.1/testdb?charset=utf8mb4)
se...
Pandas是Python的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观的处理关系型、标记型数据。 Pandas适用于处理以下类型的数据:
与SQL或Excel表类似的,含异构列的表格数据;有序和无序(非固定频率)的时间序列数据;带行列标签的矩阵数据,包括同构或异构型数据;任意其它形式的观测、统计数据集,数据转入Pandas数据结构时不必事先标记。
Pandas的主要数据结构是Series(一维数据)与DataFrame(二维数据)...
def readf(file):t0 = time.time()data=pd.read_csv(file,low_memory=False,encoding=gbk#,nrows=100)t1 = time.time()print(耗时%0.3f秒钟%(t1-t0))return data
d1=readf(file1)
t0 = time.time()
d1.to_pickle(d1.pkl)
t1 = time.time()
print(耗时%0.3f秒钟%(t1-t0))
t0 = time.time()
d2=pd.read_pickle(d1.pkl)
t1 = time.time()
print(耗时%0.3f秒钟%(t1-t0))print(d1.shape)
print(d2.shape)测试读取40多万数据的速度:
耗时...
1.map
用于series的一种方法,用于替换掉series中的数值,或者新增一列对应到series的数值
首先建立一个dataframeimport pandas as pd import numpy as npmusic_genre=['hiphop','jazz','pop','funk','rock','classical','r&b','electronic']
city=['广州市','厦门市','深圳市','西安市','武汉市','上海市','成都市','郑州市','重庆市','北京市','天津市']
data=pd.DataFrame({'gender': [ x for x in np.random.randint(0,2,1...