tokenizer.encode和tokenizer.tokenize
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了tokenizer.encode和tokenizer.tokenize,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1108字,纯文字阅读大概需要2分钟。
内容图文

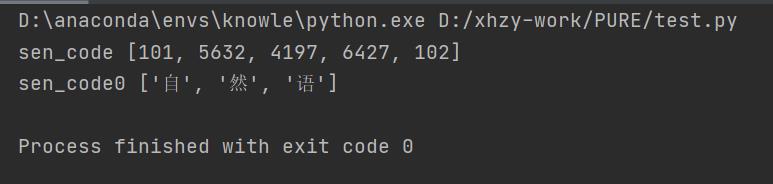
一个是返回token,一个是返回其在字典中的id,如下
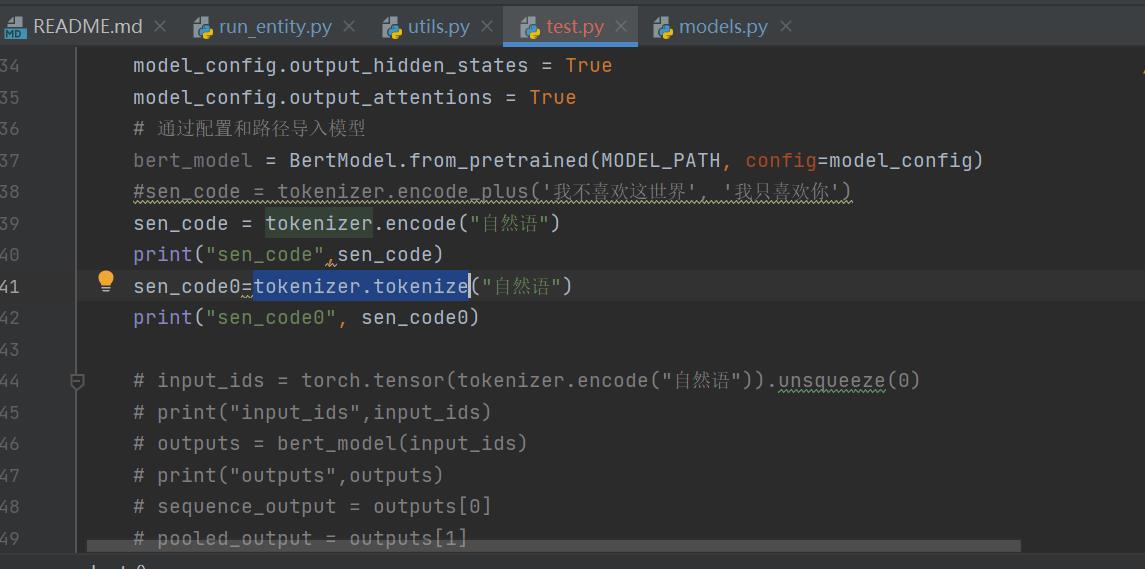
def bert_():
model_name = 'bert-base-chinese'
MODEL_PATH = 'D:/xhzy-work/PURE/models/bert-base-chinese/'
# a.通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
# b. 导入配置文件
model_config = BertConfig.from_pretrained(model_name)
# 修改配置
model_config.output_hidden_states = True
model_config.output_attentions = True
# 通过配置和路径导入模型
bert_model = BertModel.from_pretrained(MODEL_PATH, config=model_config)
#sen_code = tokenizer.encode_plus('我不喜欢这世界', '我只喜欢你')
sen_code = tokenizer.encode("自然语")
print("sen_code",sen_code)
sen_code0=tokenizer.tokenize("自然语")
print("sen_code0", sen_code0)
# input_ids = torch.tensor(tokenizer.encode("自然语")).unsqueeze(0)
# print("input_ids",input_ids)
# outputs = bert_model(input_ids)
# print("outputs",outputs)
# sequence_output = outputs[0]
# pooled_output = outputs[1]
# print("outputs",outputs)
# print("sequence_output",sequence_output.shape) ## 字向量
# print("pooled_output",pooled_output.shape) ## 句向量
# print('tokenizer.cls_token',tokenizer.cls_token)
if __name__ == '__main__':
bert_()
内容总结
以上是互联网集市为您收集整理的tokenizer.encode和tokenizer.tokenize全部内容,希望文章能够帮你解决tokenizer.encode和tokenizer.tokenize所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】