【2020】基于交互注意力卷积神经网络的中文短文本分类
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了【2020】基于交互注意力卷积神经网络的中文短文本分类,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含7812字,纯文字阅读大概需要12分钟。
内容图文

文章目录
论文链接: Chinese Short Text Classification with Mutual-Attention Convolutional Neural Networks
来源:ACM Trans
作者:北京科技大学、中国科学院
摘要
基于词级和字符级特征相结合的方法可以有效地提高短文本分类性能。许多工作将两个级别的特征串联起来,而很少进行处理,这导致了特征信息的丢失。在这项工作中,我们提出了一个新的框架称为交互注意卷积神经网络,它集成了单词和字符级的特征而不丢失太多的特征信息。首先,通过将单词和字符特征与可训练矩阵相乘,生成两个具有对齐两级特征信息的矩阵。然后,我们把它们堆成一个三维张量。最后,我们使用卷积神经网络生成集成特征。在六个公共数据集上的大量实验表明,与现有方法相比,我们的新框架性能有所改善。
关键词 短文本分类,词级和字符级,特征整合,交互注意力,卷积神经网络
1 引言
文本分类作为评价模型表示能力最流行的下游任务,是研究和业界日益活跃的领域。它被广泛应用于新闻分类、垃圾信息识别、情感分析等领域。基于神经网络的文本分类方法主要分为三类:基于单词级的模型、基于字符级的模型和基于混合级的模型。
基于词级的模型关注于促进模型从词级特征中获得精确文本表示的能力[7,18,20,25,36]。这些模特通常在英文文本上表现很好。然而,在中文短文本任务中,它们对分词有很强的依赖性,有时会导致分类错误。
基于字符级的模型利用字符嵌入来避免分词问题[4,17,35]。同时,使用字符级特性可以减少词汇表外(OOV)的负面影响。但是在中文文本中,有些单词比中文字符更有意义,它们经常在文本中发挥重要的作用,特别是在短文本中。因此,在大多数情况下,基于字符级的模型的性能要低于基于单词级的模型。
近年来,基于混合层次的模型已被证明是一种强大的表示方法,在许多自然语言处理(NLP)领域被广泛应用[16,40]。在文本分类任务中,Wang等人[29]将单词、字符和概念级特征沿时间步长维度连接;然后,他们通过卷积神经网络生成文本表示。然而,在中文中,不同的分割会产生不同的序列长度。此外,在不同语料库上训练的单词和字符嵌入也不同。如图1所示,单词和字符级嵌入保持在两个独立的空间中,几乎没有重叠。因此,沿时间步长维度直接连接特征会削弱文本表示。
Zhou等人提出了成分双向长短时记忆(C-BLSTM),从两个独立的blstm中获得两级特征;然后,特征通过两个求和池层沿时间步维度被池化。最后,他们将汇集的特征连接在一起作为最终的文本表示。Zhou等在C-BLSTM的基础上,[44]在BLSTM的每个输出上增加了注意机制,提高了中文短文本分类的准确率。然而,这些基于混合级的方法在简单的一维和池化合并词级和字符级特征时丢失了一些特征信息。因此,我们希望恢复这些丢失的特征,以提高短文本分类的性能。
为了解决上述问题,我们提出了一个新的框架,称为互注意卷积神经网络(MACNN)。MACNN的目标是在不丢失过多特征信息的情况下整合词级和字符级特征。更具体地说,我们通过单词和字符级特征的相互关注来对齐它们,我们使用了一个卷积网络,通过堆叠将所有特征集成起来,形成一个三维张量。主要贡献可归纳如下:
- 我们提出了一个有效的端到端框架,利用交互注意力机制和卷积神经网络来整合单词和字符级特征。
- 提出了一种利用卷积神经网络整合两级特征的新方法,可以保留更多的特征信息。
- 在六个公共数据集上的大量实验表明,我们的工作优于其他现有方法。
在第二节中,我们回顾了文本分类的相关工作。第3节详细介绍了我们的方法。在第四节中,我们详细描述了实验评价的设置和实验结果。最后,我们在第五节中做一个结论。
2 相关工作
中文短文本分类作为文本分类的子任务,长期以来面临两大挑战:中文分词错误和上下文信息限制。下面我们将介绍模型改进、嵌入生成、文本信息丰富等方面的相关工作。
研究者通过修改模型的结构来增强模型,以获得文本表示[15,24,46]。Zhou等人提出了一种方法,通过将BLSTM输出与二维最大池化相结合,同时获取时间步长和特征维数信息。Zhang等[38]提出了Tree LSTM,通过估计句子依赖树的生成概率来定义句子的概率。Hao等人[10]指出,对短文本特征进行加权可以有效提高分类准确率。注意机制是一种比较流行的端到端的特征加权方法,在各个领域都很流行[2,6,21,23,28,42,45]。这些模型通过简单地使用单层特征来提高性能,而没有考虑通过添加多种类型的特征来丰富文本表示。此外,由于单一层次模型存在分词错误的问题,不适合中文文本分类。
嵌入生成 Ling等人提出了一种字符-词(C2W)模型,该模型将字符级嵌入到词级中,并在五种不同的语言数据集中实现了更好的性能。Li等[33]和Zhang等[39]引入字符级嵌入来获得单词级表示。Kim等人利用字符级嵌入卷积神经网络和高速公路网络可以提高多语言预测任务的性能。Bollegala等人认为,他们提出的方法通过考虑特征之间的隐式共现,推广了单词共现图。Wieting等[12]通过字符n-gram嵌入单词和句子。Wehrmann等[32]利用卷积神经网络的字符嵌入来分析Twitter的情感。使用字符级特征生成文本表示,可以解决分词错误和词汇表外的问题。然而,仅使用字符级特征[43]很难在中文短文本分类中取得良好的性能。
文本信息丰富 Wang等人将单词和标签嵌入结合起来,通过添加标签信息来提高性能。Zhang等人将异构信息集成到模型中。Wang等人利用词嵌入聚类和卷积神经网络扩展语义。一种比较流行的方法是将词级和字符级嵌入连接起来,不仅可以补充语义信息,还可以减少分词错误造成的损害[13,29,43,44]。但这些方法忽略了单词和字符之间的内在联系。
Wang et al.[31]等人提出了一种通过组合句子组成词的意义来表示句子意义的有效方法。一些作品[5,34]研究了句子对的关系。基于暹罗结构的基本卷积神经网络(BCNN)解决了句子对[5]之间的相互关系问题。在BCNN的基础上,基于注意力的卷积神经网络(ABCNN)通过增加三种额外的注意方案[34]中的一种来优化句子对建模的性能。我们的灵感就来自这些模型。我们将两级特征视为两个不同的句子表示,利用相互注意捕获它们之间的关系,并利用三维卷积神经网络对它们进行整合。
3 所提方法
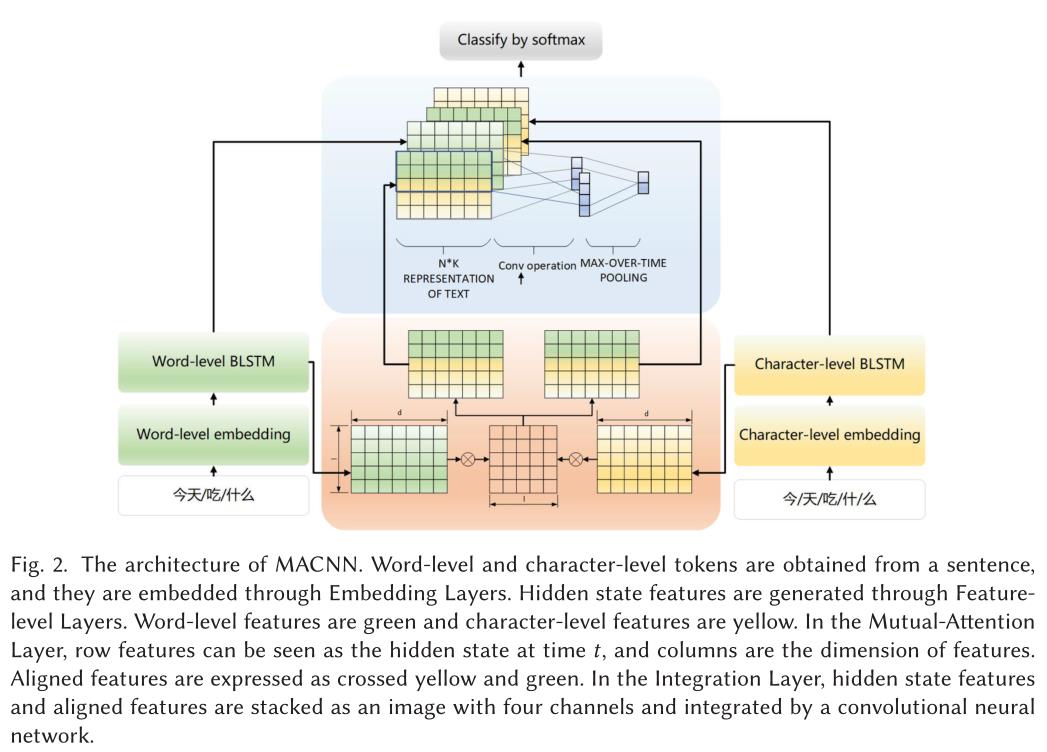
图2显示了我们模型的体系结构。该模型由嵌入层、特性层、相互关注层和集成层组成。嵌入层通过两个预先训练的嵌入字典将分段标记映射为两级嵌入。特征层由两个独立的BLSTM组成,每个BLSTM都可以获得单词级或字符级嵌入的特征。相互关注层是一个可训练矩阵,它可以生成单词级和字符级特征的两个对齐矩阵。集成层是一个具有四个独立通道的卷积神经网络,可以将所有的特征叠加成一个三维张量。我们将在下面的部分中介绍它们。
3.1 嵌入层
3.2 特征层
用BILSTM进行特征提取
3.3 交互注意力层
由于分词粒度的不同,词级和字符级特征中的语义信息不同,如果直接将它们与时间步长维度连接,会出现错位问题。使用最大或和池化是解决这一问题的简单方法,但它将丢失很大一部分特征信息。(注:C-CNNs就是这么干的)
注意机制被用于特征对齐,因为注意机制的本质是句子对的软对齐.
3.3 集成层
但是,特征向量维数上的特征不是相互独立的,简单地对时间步长维数进行1D池化操作可能会破坏特征表示[41]的结构。卷积神经网络[13]利用多个卷积滤波器进行特征映射,比一维最大池能保留更多的特征信息。因此,我们选择CNN而不是Feature-level Layer来整合它们。
本文的创新之处在于:将两级特征和单元叠加成三维张量,然后将其输入卷积神经网络。与一幅有三个通道的图像相似,我们可以把堆叠的特征看作是一幅有四个通道的图像。利用具有强大特征提取能力的3D卷积神经网络,可以将特征整合到固定大小的向量中,同时比一维池化操作保留更多的特征信息。
4 实验
4.1 验证单词和字符级嵌入的相关性
在不同的语料库上进行的词级嵌入和字符级嵌入是不同的。然而,我们不知道单词嵌入和字符嵌入之间的区别有多大。本文采用Baike语料库[19]和搜狗语料库[19]进行预训练。我们首先嵌入可以作为单词和字符使用的标记,然后使用t-SNE[22]在2D地图上可视化它们(如图1所示)。很明显,在2D地图中,单词级和字符级特征的位置有很大的分离。这意味着它们在高维空间中距离更远。因此,词级和字符级的嵌入在向量空间中没有相关性。
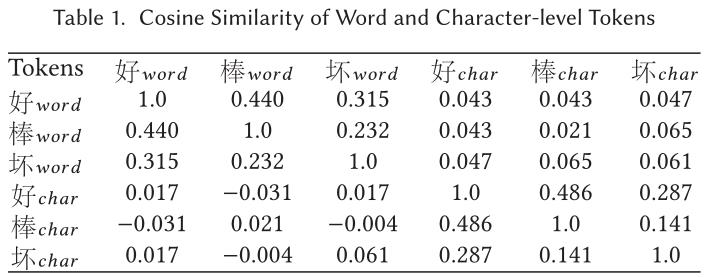
然后,为了验证词级和字符级嵌入的语义相关性,我们选择了三个中文标记:“好”、“坏”、“棒”,其中{好,棒}是同义词,{好,坏}和{棒,坏}是反义词。我们用余弦相似性来计算它们的相似度。
结果如表1所示。从表中可以看出,如果特征来自于相同的嵌入,则具有较强的语义相关性,例如{好,棒}在词级嵌入中相似度为0.440,在字符级嵌入中相似度为0.486。但是,如果一个标记来自单词级,而另一个标记来自字符级,那么{好,棒}的相似性与{好,坏}没有区别。这一结果证明了在不同语料库上训练的词级嵌入和字符级嵌入之间的相关性较弱。
4.2 中文短文本分类
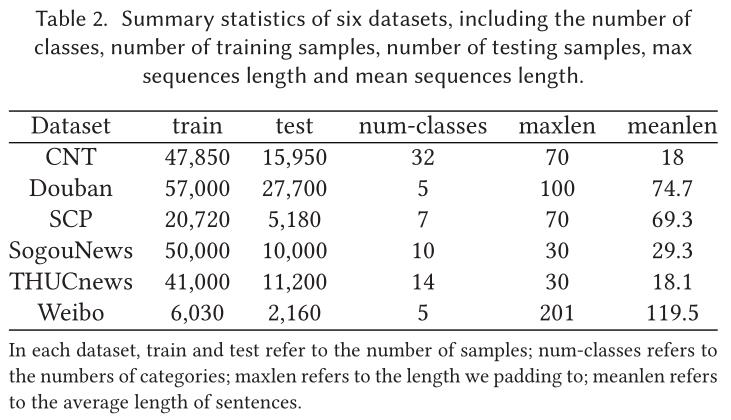
4.2.1 数据集
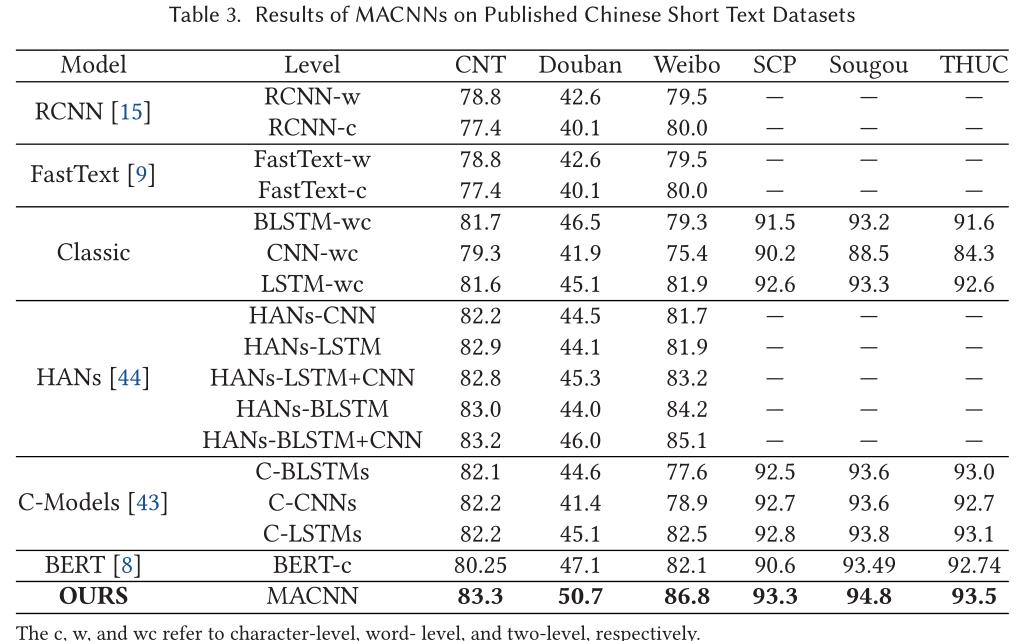
4.2.2实验结果
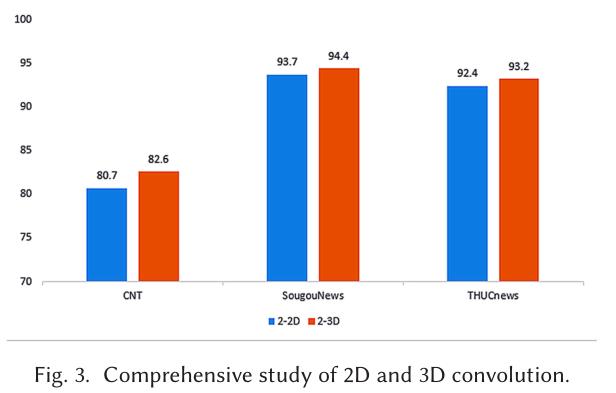
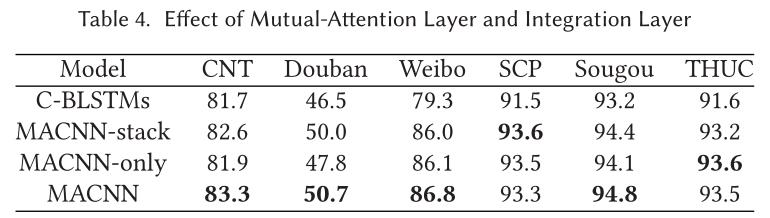
4.3 消融实验
5 结论和未来工作
现有的许多方法使用和或最大池化来整合单词和字符级的特征,这可能会导致特征信息的丢失。这是因为连接两级特性直接忽略了语义对齐。为了解决这些问题,在本文中,我们提出了一个新的框架,称为互注意卷积神经网络(MACNN)。在该算法中,我们通过设置一个可训练矩阵,将两级隐藏状态特征相乘,得到两个对齐的特征。同时,通过卷积神经网络对这些特征进行叠加和整合。实验结果表明,该方法在6个中文短文本数据集上均取得了较好的性能。我们注意到三维卷积神经网络在我们的框架中起着重要的作用;我们将在未来的工作中研究三维卷积对多层次特征的集成。
内容总结
以上是互联网集市为您收集整理的【2020】基于交互注意力卷积神经网络的中文短文本分类全部内容,希望文章能够帮你解决【2020】基于交互注意力卷积神经网络的中文短文本分类所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。