abbyy finereader识别图片中文本的具体步骤讲述
软件教程导读
互联网集市收集整理了【abbyy finereader识别图片中文本的具体步骤讲述】电脑软件教程,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1118字,纯文字阅读大概需要2分钟。
软件教程内容图文


由于图片中的文本分列显示,因此打开ABBYY FineReader后,选择Microsoft Excel项。
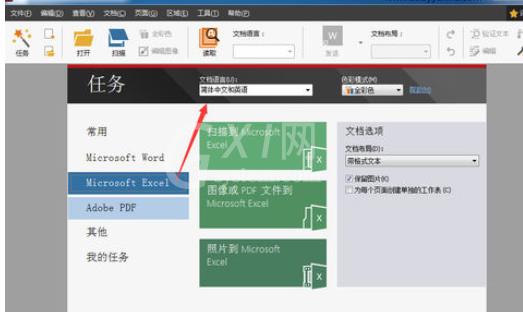
然后选择“图像或pdf文件到Microsoft Excel”,添加要识别的两张图片,打开后软件自动开始识别;也可以点击“文件”,新建一个文档,然后直接把要识别的图片拖放到软件左列,同样可以打开进行识别。
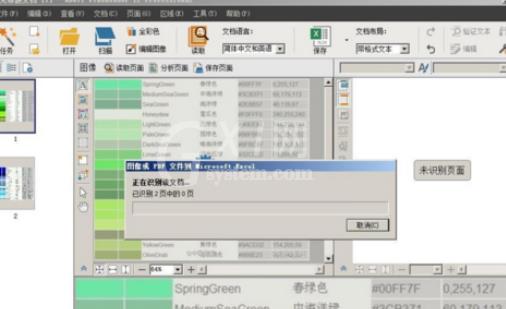
考虑到图片文字可能会出现模糊,文本歪斜和转向,因此选择取消识别,先对图片进行编辑处理,点击上面工具栏里的“编辑图像”,右侧打开编辑工具列表。
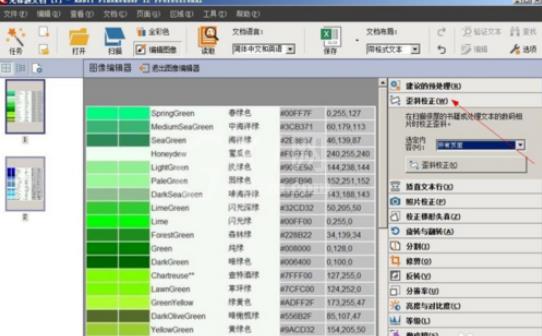
我们先要对图像进行歪斜校正,如扫描的图片不规整,在扫描后会提示对需要进行校正的图片进行歪斜校正,这里可以选定“全部页面”,然后点击“歪斜校正”;若图片是旋转90度或倒转后的图片,可在这里将其旋转或翻转处理。

接下来,也是最重要的,就是调整图片的分辨率,有些图片模糊不清,会影响软件识别效果,这里可将图片的分辨率设为扫描图像的分辨率,即300dpi,这个值基本上都可以正常识别了,也可以自定义分辨率。通过这个选项,可分别单张设置图片的分辨率,也可以选奇数页或偶数页和全部页面,为了不影响识别,这里可以选择“所有页面”。
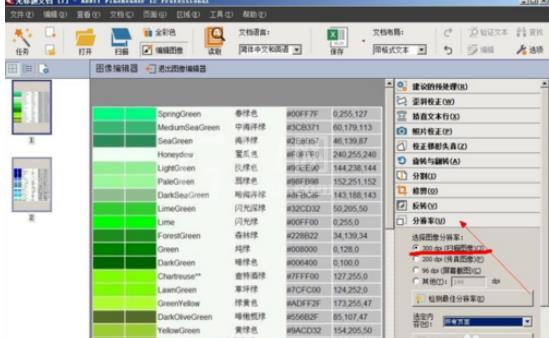
然后退出图像编辑器。由于我们只需要中英文对照的两列文本,其他无关的内容可以不进行识别,因此,可选择要识别的区域,即点击中间一栏左上角的“A”按钮,可选择两列要识别的文本。
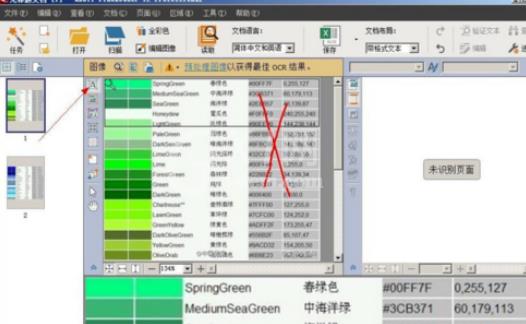
选定后的文本呈浅绿色,然后点击选中区域,在弹出的工具栏选择按钮“A”,找到里面的“表格”项,这样识别后的文本就成两列对照的文本了。

这时点击上面工具栏里的“读取”选项,开始识别。
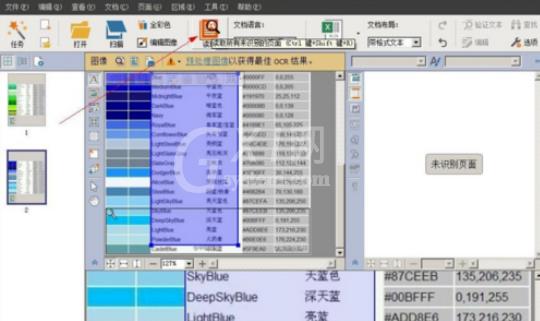
下图为识别后的效果图,最右侧一栏是识别的文本内容,在该栏头部,可对识别的文本格式进行设置,如设置字体,字号、倾斜、加粗等。
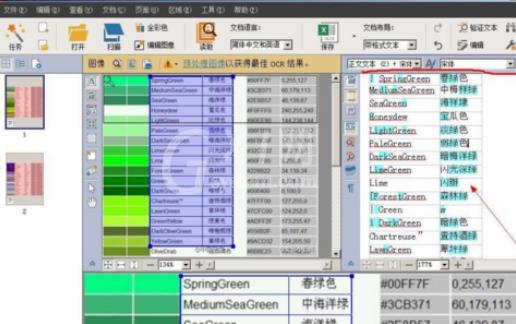
识别后的文本中,绿色显示的是可能存在拼写或识别错误或置信度较低的字符,如果未做处理直接导出,可能会影响以后使用。这时,可选择工具栏里的“验证文本”,对绿色标记部分进行编辑确认。

操作过程中,会发现标记为绿色的文本有些并没有拼写错误,可能只是字体设置不当,这种情况下只需要忽略跳过即可,存在识别错误的文字,进行更改替换,FineReader自带的字典会提示可能正确的识别变量,选择正确的文字,点击“替换”或“全部替换”,然后“确认”即可。
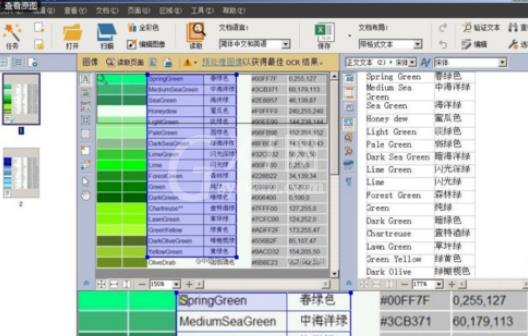
然后输出文本,点击工具栏内的“保存”,即保存为Excel格式的文件,默认状态下,保存好的文件会自动打开。
根据上文为你们讲述的abbyy finereader识别图片中文本的具体步骤讲述,你们是不是都明白了呀!
软件教程总结
以上是互联网集市为您收集整理的【abbyy finereader识别图片中文本的具体步骤讲述】电脑软件教程的全部内容,希望文章能够帮你了解电脑软件教程abbyy finereader识别图片中文本的具体步骤讲述。 如果觉得互联网集市电脑软件教程内容还不错,欢迎将互联网集市网站推荐给好友。
软件教程备注
版权声明:本文内容由互联网用户贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
软件教程手机端
扫描二维码推送至手机访问。