爬虫基础
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了爬虫基础,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3727字,纯文字阅读大概需要6分钟。
内容图文

爬虫
首先要知道url是一个统一资源定位符,它的格式是协议名://资源名(在爬虫中常爬取的是HTTP和HTTPS协议,HTTP协议是超文本传输协议,用于在网络上传输超文本数据到本地浏览器的传送协议,而HTTPS是超文本传输安全协议,简言之就是HTTP的安全版,在HTTP下加入SSL层)。我们在向服务器发送请求的常用方法是get和post。我们在百度上搜索的内容会出现在url的wd=的后面,那么我们在登陆时提交的用户名和密码名就会暴露在url中,所以有了post请求,post请求的url不会包含参数,数据以表单的形式传输会包含在请求体中。get提交的请求数据最多只有1024个字节,但是post没有限制,所以如果文件大的话也会用post请求。一个网页包括HTML(超文本标记语言),css(层叠样式表,对网页的文字大小,颜色、元素间距排列等格式进行处理),JavaScript(脚本语言,在网页里面的交互和动画效果,如下载进度条,提示框等,通常以单独的文件形式加载后缀为.js,在HTML中通过script标签引入),HTML就相当于一个人的骨架,css就相当于皮肤,js就相当于肌肉。
这个就是爬虫的流程:
爬虫就是获取网页并提取和保存信息的自动化程序。
1、发送请求:爬虫首先要做的就是获取网页,要向服务器发送一个请求首先要构造网站的url,如果是get请求的话我们需要在url中添加参数,如果网站有反爬措施,就需要在请求头中伪造user-agent
2、获取相应内容:我们从服务器返回的数据有时候可能是网页的源代码或者是一串json字符串,不过他们都是完整的响应,里面包括请求头请求体等内容,所以要获取我们想要的数据就需要根据服务器返回的内容制定不同的爬取策略和解析方式。
3、解析内容:我们最常用的方式就是通过正则表达式提取,是一个万能的方法,不过我们在构造正则表达式的可能会出错,而且网页的结构有一定的规则,所以我们还需要根据网页节点属性、CSS选择器或XPath获取网页信息。
4、保存数据:可以简单的保存为TXT或json文本,也可以保存到数据库。
我们需要用到python库中自带的rullib库
rullib库中:
request是最基本的http请求模块,用来模拟发送请求
error是异常处理模块,如果出现错误可以捕获这些异常
parse是工具模块,有很多url处理方法,拆分解析合并等
robotparser识别网站的robot.txt文件,判断哪些网站可以爬
1、urllib.request(构造请求):提供了基本的构造HTTP请求的方法。比如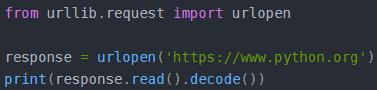
urlopen来构造HTTP请求,返回值是一个HTTPRsponse对象,用read()方法来读取网页内容,返回结果是网页的字节流,用decode()解码成unicode之后就可以得到网页源代码了。urlopen的参数信息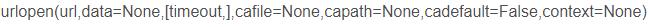
首先data参数(字节类型,用urllib.parse的urlencode()可以把参数字典转换为字符串,再用bytes()函数将其转化为字节流)是可选的,如果要添加这个参数需要将其内容编码为字节流格式即bytes类型,而且如果传递了这个参数,请求方式将使用POST请。
timeout参数用于设置超时时间,单位:秒,如果请求超时还未得到响应则应抛出异常
其他参数:
**2、urllib.request的高级类:urllib.request模块里面的BaseHandler类是所有其他Handler的父类,通俗易懂它就是一个处理器,处理登录验证、cookies、代理设置、重定向等
Handler的子类
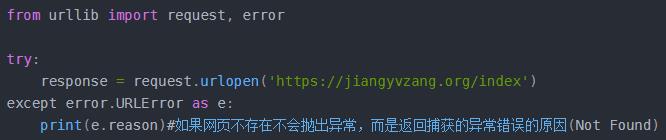
3、urllib.error(异常处理):request模块产生异常,便会抛出error模块中定义的异常,其中有两个子类URLError和HTTPError。
3.1、URLError是error异常模块的基类,由request模块产生的异常都可以通过捕获这个类来处理,只有一个reason属性,用来返回错误原因。
3.2、HTTPError:是URLError的子类,专门处理HTTP请求错误,比如认证请求失败,有三个属性:code:返回HTTP的状态码,如页面404不存在;reason:同父类,返回错误的原因;headers:返回请求头。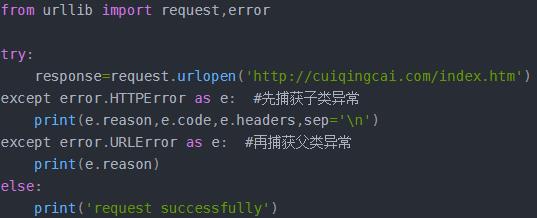
结果如下: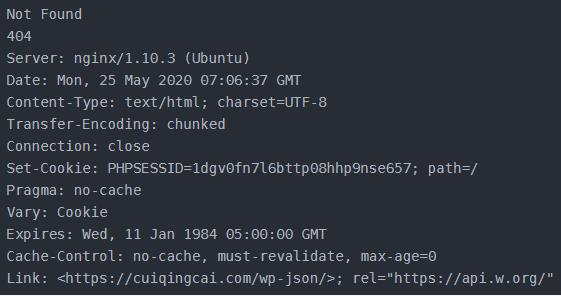
4urllib。parse(解析链接):
定义了处理URL的标准接口,如实现URl各部分的抽取,合并以及链接转换
4.1urlparse()实现URL的识别和分段

输出结果ParseResult类型对象,分别是scheme(协议),netico(域名)、path(访问路径)、params(参数),query(条件),fragment(锚点),所以有一个标准的链接格式

4.2urlunparse:它接受一个可迭代对象,长度为6

4.3urljoin:可以完成链接的合并
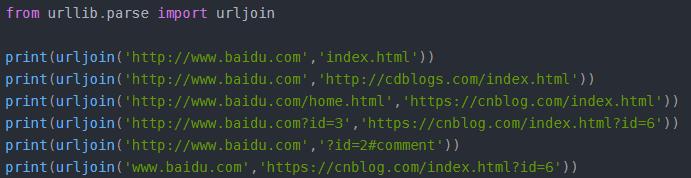
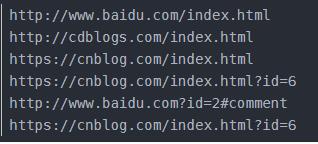
4.4urlencode():将字典转化为get请求参数
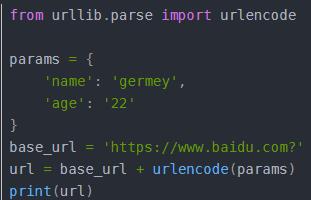

4.5parse_qs():和上见面那个相反是来分反序列化的,将get参数转换会字典格式
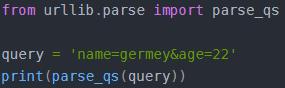

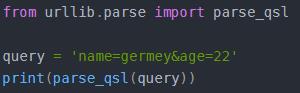
4.6parse.qsl():将参数转化为元组组成的列表
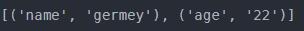
5、robots协议
也称为爬虫协议或者机器人协议,来告诉爬虫和搜索引擎哪些可以爬哪些不能爬,通常是一个robots.txt的文本文件,一般放在网站的根目录下。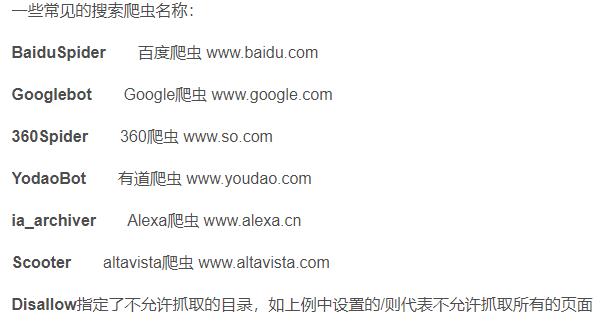
5.2robotparser用来解析robots.txt
常用的方法

内容总结
以上是互联网集市为您收集整理的爬虫基础全部内容,希望文章能够帮你解决爬虫基础所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。