快速排序
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了快速排序,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4386字,纯文字阅读大概需要7分钟。
内容图文

快速排序是对冒泡排序的一种改进,它的基本思想是:通过一趟排序将待排序序列分割成独立的两部分,其中一部分的关键字均比另一部分的关键字要小,对这两部分继续分别进行排序,以达到整个序列的有序。本质上,快速排序是对二叉树的前序遍历。
基本思想如下:
-
从当前序列
base中选择一个基准数pivot,可以选择第一个元素,最后一个元素或者随机选择; -
将序列
base拆解为序列A和序列B,序列A中的元素小于pivot,序列B中的元素大于pivot,最终组成一个新的序列[A, pivot, B]; -
再分别对序列
A和序列B重复第二步,直到序列base只有一个数。
执行过程
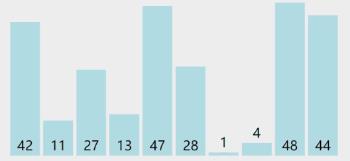
对一组序列42,11,27,13,47,28,1,4,48,44执行快速排序算法,每次的基准均为当前序列的第一个元素,其排序过程如下图所示:
代码
方案一
上图中描述的过程使用C++的实现见如下代码:
class Solution {
public:
// 排序接口
vector<int> sortArray(vector<int>& nums) {
QuickSort(0, nums.size() - 1, nums);
return nums;
}
// 快速排序
void QuickSort(const int &start, const int &end, vector<int> &nums) {
if (start <= end) {
// 一次划分,返回基准索引
int pivot_pos = Partition(start, end, nums);
// 排序序列A
QuickSort(start, pivot_pos - 1, nums);
// 排序序列B
QuickSort(pivot_pos + 1, end, nums);
}
}
// 一次划分
int Partition(int start, int end, vector<int> &nums) {
// 记录当前访问位置
int i = start + 1;
// 小于基准的元素数
int low_num = 0;
// 大于基准的元素数
int high_num = 0;
// 每次循环都会得到两个相邻的序列,序列A的元素都比基准元素小,序列B的元素都比基准元素大
while (i <= end) {
if(nums[i] <= nums[start]) {
// 当前元素小于基准,则应该被划分到序列A,因此和序列B的第一个元素交换,序列A的长度加1,序列B整体后移一个元素
swap(nums[i], nums[start + low_num + 1]);
low_num++;
} else {
// 当前元素大于基准,已经在序列B中,因此序列B的长度加1
high_num++;
}
i++;
}
// 由于基准在nums[start]中,应该将其放在序列A和序列B的交界处,因此交换基准索引和start的元素
swap(nums[start], nums[start + low_num]);
// 返回基准索引
return start + low_num;
}
};
这一代码在912. 排序数组中执行耗时28 ms。方案一在划分时每趟循环最多交换一个元素,循环n次。
实现时需要注意:
- 在循环中序列
B的第一个元素位于nums[start + low_num + 1]; - 循环结束后,基准元素的索引应该在
nums[start + low_num]。
方案二
快速排序的划分过程还有另一种实现方式,其代码如下:
class Solution {
public:
// 排序接口
vector<int> sortArray(vector<int>& nums) {
QuickSort(0, nums.size() - 1, nums);
return nums;
}
// 快速排序
void QuickSort(const int &start, const int &end, vector<int> &nums) {
if (start <= end) {
int mid = Partition(start, end, nums);
QuickSort(start, mid - 1, nums);
QuickSort(mid + 1, end, nums);
}
}
// 一次划分,划分结束后会得到两个相邻的序列,序列A的元素都比基准元素小,序列B的元素都比基准元素大
int Partition(int start, int end, vector<int> &nums) {
//取基准元素,这里取序列第一个元素为基准
int pivot_key = nums[start];
// 开始遍历,将序列A固定在nums的低地址,将序列B固定在nums的高地址
while (start < end) {
// **tips:这里一定要先处理与基准相反的方向,比如基准在低地址,那么要先处理高地址的元素
// 找到数组高地址处下一个比基准小的元素
while (start < end && nums[end] >= pivot_key) {end--;}
// 找到后将这一元素移动到低地址处
nums[start] = nums[end];
// 找到数组低地址处下一个比基准大的元素
while (start < end && nums[start] <= pivot_key) {start++;}
// 找到后将这一元素移动到高地址处
nums[end] = nums[start];
}
nums[start] = pivot_key;
// 返回基准索引
return start;
}
};
这一代码在912. 排序数组中执行耗时28 ms。方案二在划分元素时每趟循环最多交换两个元素,循环约等于n/2次。
实现时需要注意:
- 一定要先处理与基准相反的方向,比如基准在低地址,那么要先处理高地址的元素;
nums[end] >= pivot_key和nums[start] <= pivot_key一定要带上等于,否则会导致循环不结束;
序列A和B在生成时,方案一和方案二的区别在于,方案一中将序列B逐渐从nums的低地址处移动到高地址处,而方案二始终将序列A和序列B固定在nums两端。
空间复杂度分析
快速排序需要一个栈空间来实现递归,假定我们的目标序列为升序序列时:
- 当序列顺序为降序时,需要n-1次递归调用,栈的深度达到最深,空间复杂度为
O(n); - 当每趟划分能够将序列划分为长度相近的两个子序列时,栈的深度最最小,空间复杂度为
O(logn)。
时间复杂度分析
快速排序使用递归实现的,因此其时间复杂度,取决于递归树的深度:
平均情况下:快速排序平均时间复杂度为O(nlogn),在所有同数量级的排序方法中,就平均时间而言,快速排序是目前被认为最好的一种内部排序方法;
最坏情况下:如果初始序列基本有序时,快速排序将退化为冒泡排序,其时间复杂度为O(n^2)。
稳定性分析
由于其关键字的比较和交换是跳跃进行的,排序后相同元素的相对位置可能发生改变,因此快速排序是一种不稳定的排序算法。
总结
| 算法名称 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 最好空间复杂度 | 最坏空间复杂度 | 平均空间复杂度 | 是否稳定 |
|---|---|---|---|---|---|---|---|
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) | O(n) | O(logn) | 否 |
内容总结
以上是互联网集市为您收集整理的快速排序全部内容,希望文章能够帮你解决快速排序所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。