Flink 实时写入数据到 ElasticSearch 性能调优
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Flink 实时写入数据到 ElasticSearch 性能调优,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5942字,纯文字阅读大概需要9分钟。
内容图文

背景说明
线上业务反应使用Flink消费上游kafka topic里的轨迹数据出现backpressure,数据积压严重。单次bulk的写入量为:3000/50mb/30s,并行度为48。针对该问题,为了避免影响线上业务申请了一个与线上集群配置相同的ES集群。本着复现问题进行优化就能解决的思路进行调优测试。
测试环境
elasticsearch 2.3.3
flink 1.6.3
flink-connector-elasticsearch2_2.11
八台SSD,56核 :3主5从
Rally分布式压测ES集群
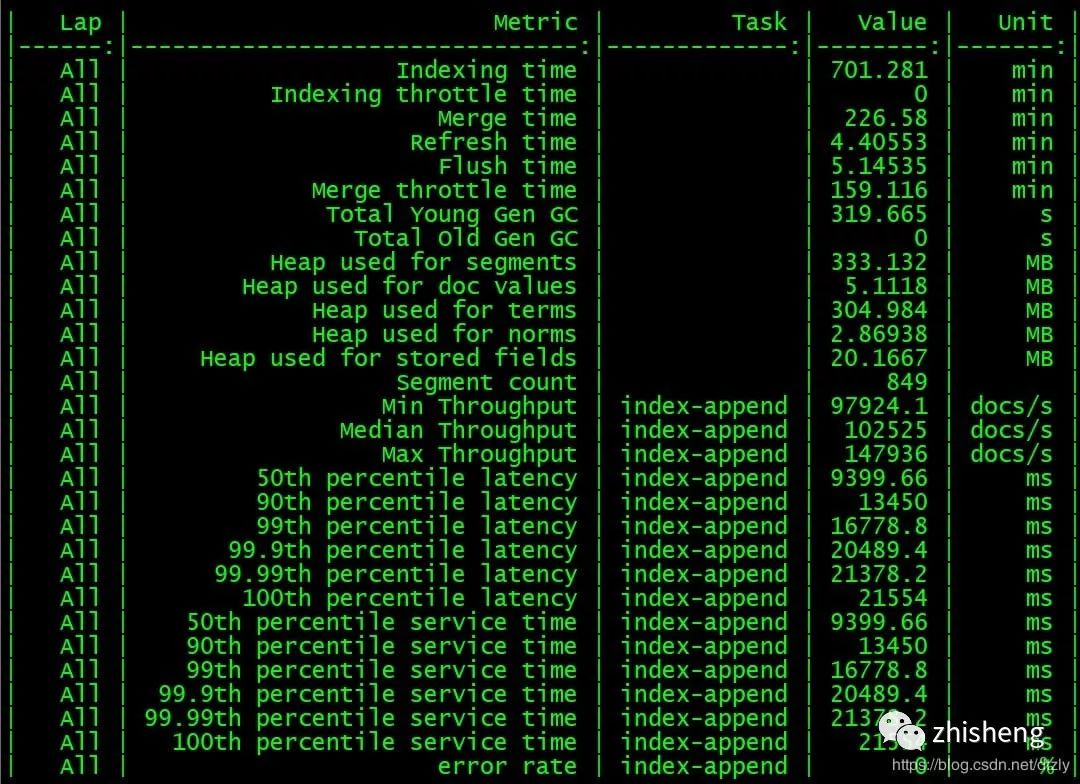
从压测结果来看,集群层面的平均写入性能大概在每秒10w+的doc。
Flink写入测试
配置文件
1config.put("cluster.name",?ConfigUtil.getString(ES_CLUSTER_NAME,?"flinktest"));
2config.put("bulk.flush.max.actions",?ConfigUtil.getString(ES_BULK_FLUSH_MAX_ACTIONS,?"3000"));
3config.put("bulk.flush.max.size.mb",?ConfigUtil.getString(ES_BULK_FLUSH_MAX_SIZE_MB,?"50"));
4config.put("bulk.flush.interval.ms",?ConfigUtil.getString(ES_BULK_FLUSH_INTERVAL,?"3000"));
执行代码片段
1final?StreamExecutionEnvironment?env?=?StreamExecutionEnvironment.getExecutionEnvironment();
2initEnv(env);
3Properties?properties?=?ConfigUtil.getProperties(CONFIG_FILE_PATH);
4//从kafka中获取轨迹数据
5FlinkKafkaConsumer010<String>?flinkKafkaConsumer010?=
6????new?FlinkKafkaConsumer010<>(properties.getProperty("topic.name"),?new?SimpleStringSchema(),?properties);
7//从checkpoint最新处消费
8flinkKafkaConsumer010.setStartFromLatest();
9DataStreamSource<String>?streamSource?=?env.addSource(flinkKafkaConsumer010);
10//Sink2ES
11streamSource.map(s?->?JSONObject.parseObject(s,?Trajectory.class))
12????.addSink(EsSinkFactory.createSinkFunction(new?TrajectoryDetailEsSinkFunction())).name("esSink");
13env.execute("flinktest");
运行时配置
任务容器数为24个container,一共48个并发。savepoint为15分钟
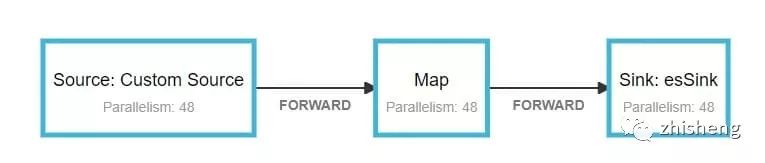
运行现象
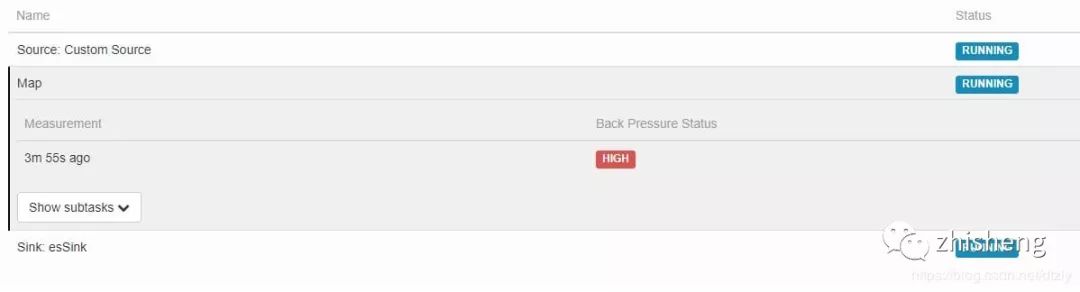
source和Map算子均出现较高的反压
ES集群层面,目标索引写入速度写入陡降
平均QPS为:12k左右
对比取消sink算子后的QPS
1streamSource.map(s?->?JSONObject.parseObject(s,?FurionContext.class)).name("withnosink");
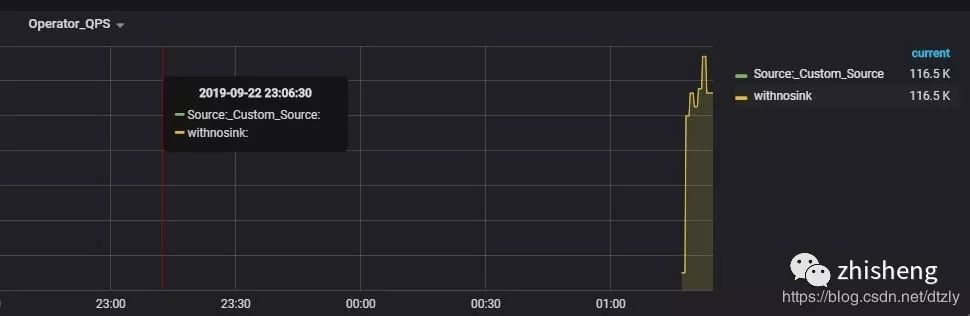
平均QPS为:116k左右
有无sink参照实验的结论
取消sink2ES的操作后,QPS达到110k,是之前QPS的十倍。由此可以基本判定: ES集群写性能导致的上游反压
优化方向
索引字段类型调整
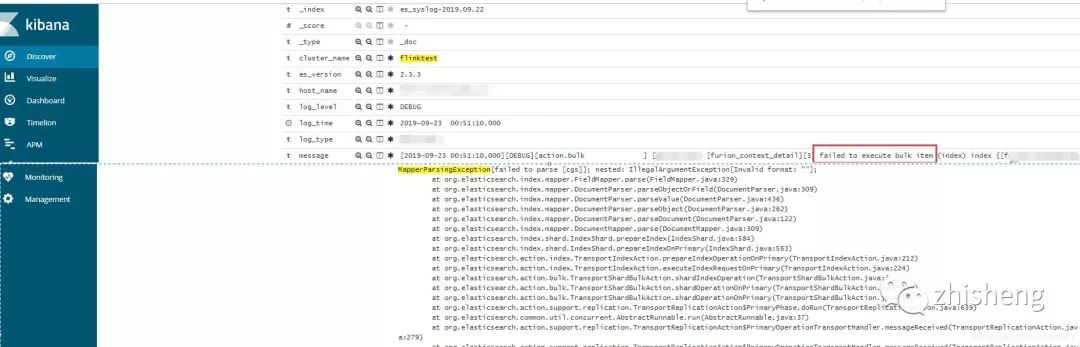
bulk失败的原因是由于集群dynamic mapping自动监测,部分字段格式被识别为日期格式而遇到空字符串无法解析报错。
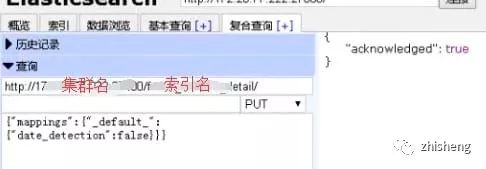
解决方案:关闭索引自动检测
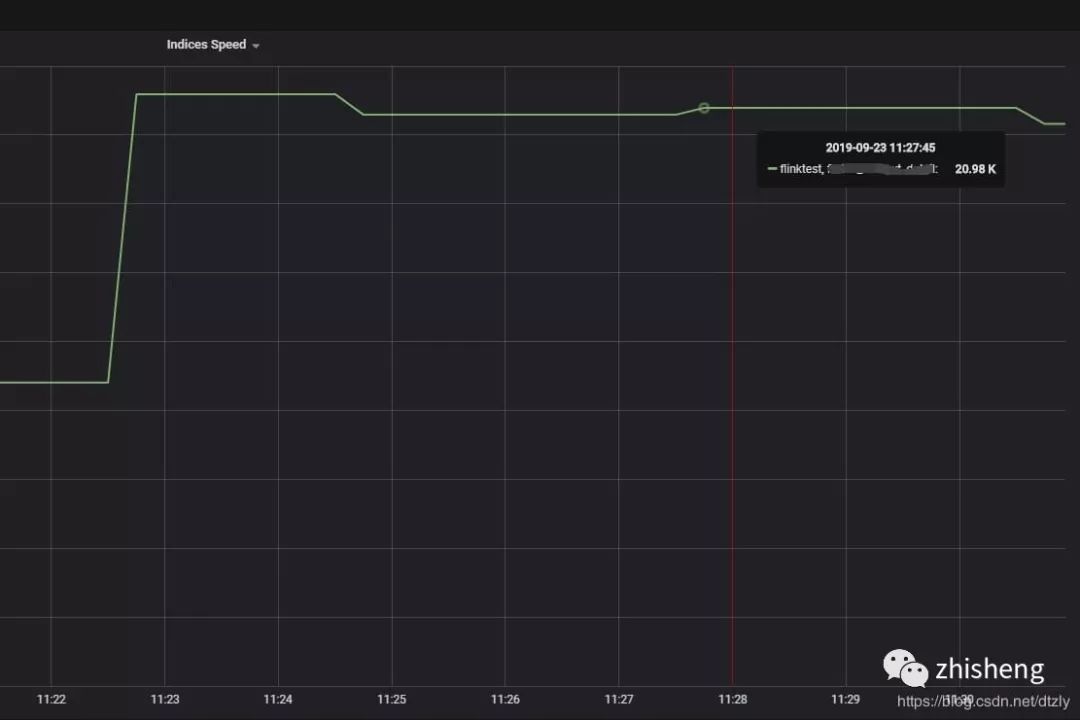
效果: ES集群写入性能明显提高但flink operator 依然存在反压:
降低副本数
1curl?-XPUT{集群地址}/{索引名称}/_settings?timeout=3m?-H?"Content-Type:?application/json"?-d'{"number_of_replicas":"0"}'
提高refresh_interval
针对这种ToB、日志型、实时性要求不高的场景,我们不需要查询的实时性,通过加大甚至关闭refresh_interval的参数提高写入性能。
1curl?-XPUT{集群地址}/{索引名称}/_settings?timeout=3m?-H?"Content-Type:?application/json"?-d?'{?"settings":?{??"index":?{"refresh_interval"?:?-1???}???}??}'
检查集群各个节点CPU核数
在flink执行时,通过Grafana观测各个节点CPU 使用率以及通过linux命令查看各个节点CPU核数。发现CPU使用率高的节点CPU核数比其余节点少。为了排除这个短板效应,我们将在这个节点中的索引shard移动到CPU核数多的节点。
1curl?-XPOST?{集群地址}/_cluster/reroute??-d'{"commands":[{"move":{"index":"{索引名称}","shard":5,"from_node":"源node名称","to_node":"目标node名称"}}]}'?-H?"Content-Type:application/json"
以上优化的效果:
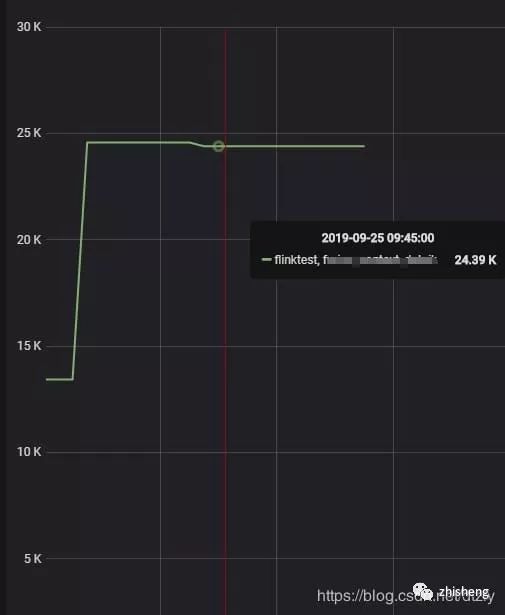
经过以上的优化,我们发现写入性能提升有限。因此,需要深入查看写入的瓶颈点
在CPU使用率高的节点使用Arthas观察线程:
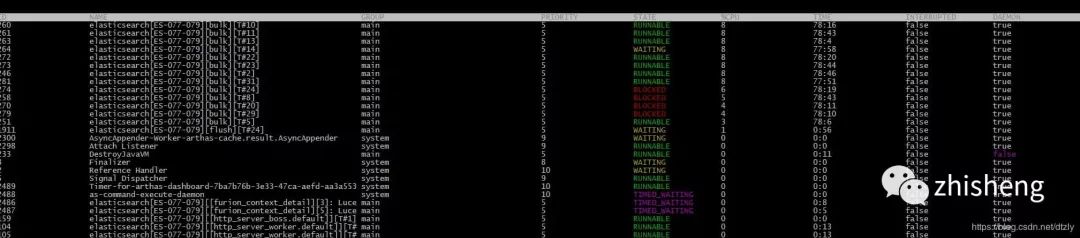
打印阻塞的线程堆栈
1"elasticsearch[ES-077-079][bulk][T#3]"?Id=247?WAITING?on?java.util.concurrent.LinkedTransferQueue@369223fa
2????at?sun.misc.Unsafe.park(Native?Method)
3????-??waiting?on?java.util.concurrent.LinkedTransferQueue@369223fa
4????at?java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
5????at?java.util.concurrent.LinkedTransferQueue.awaitMatch(LinkedTransferQueue.java:737)
6????at?java.util.concurrent.LinkedTransferQueue.xfer(LinkedTransferQueue.java:647)
7????at?java.util.concurrent.LinkedTransferQueue.take(LinkedTransferQueue.java:1269)
8????at?org.elasticsearch.common.util.concurrent.SizeBlockingQueue.take(SizeBlockingQueue.java:161)
9????at?java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
10????at?java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
11????at?java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
12????at?java.lang.Thread.run(Thread.java:745)
从上面的线程堆栈我们可以看出线程处于等待状态。
关于这个问题的讨论详情查看https://discuss.elastic.co/t/thread-selection-and-locking/26051/3,这个issue讨论大致意思是:节点数不够,需要增加节点。于是我们又增加节点并通过设置索引级别的total_shards_per_node参数将索引shard的写入平均到各个节点上)
线程队列优化
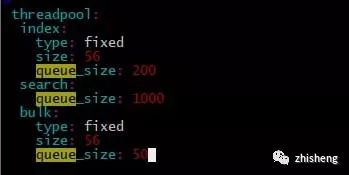
ES是将不同种类的操作(index、search…)交由不同的线程池执行,主要的线程池有三:index、search和bulk thread_pool。线程池队列长度配置按照官网默认值,我觉得增加队列长度而集群本身没有很高的处理能力线程还是会await(事实上实验结果也是如此在此不必赘述),因为实验节点机器是56核,对照官网,:

因此修改size数值为56。
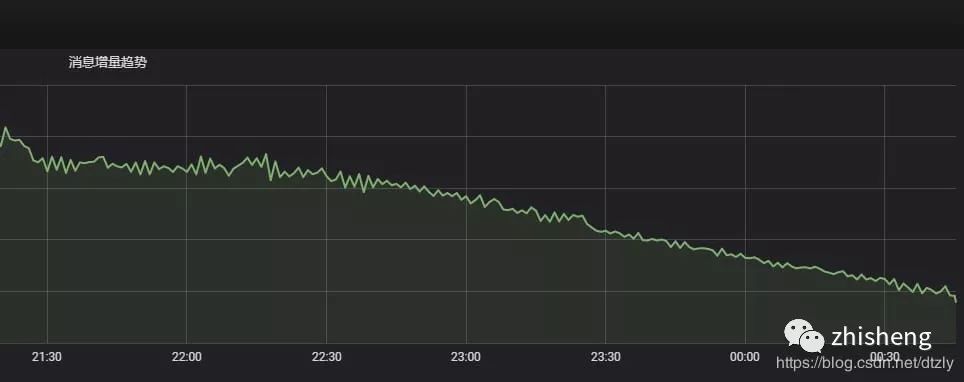
经过以上的优化,我们发现在kafka中的topic积压有明显变少的趋势:
index buffer size的优化
参照官网:

1indices.memory.index_buffer_size?:?10%
translog优化:
索引写入ES的基本流程是:1.数据写入buffer缓冲和translog 2.每秒buffer的数据生成segment并进入内存,此时segment被打开并供search使用查询 3.buffer清空并重复上述步骤 4.buffer不断
添加、清空translog不断累加,当达到某些条件触发commit操作,刷到磁盘。es默认的刷盘操作为request但容易部分操作比较耗时,在日志型集群、允许数据在刷盘过程中少量丢失可以改成异步async
另外一次commit操作是在translog达到某个阈值执行的,可以把大小(flush_threshold_size )调大,刷新间隔调大。
1index.translog.durability?:?async
2index.translog.flush_threshold_size?:?1gb
3index.translog.sync_interval?:?30s
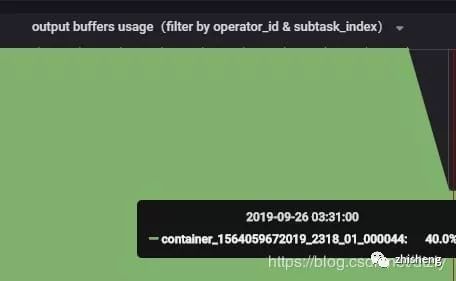
效果:
flink反压从打满100%降到40%(output buffer usage):
kafka 消费组里的积压明显减少:
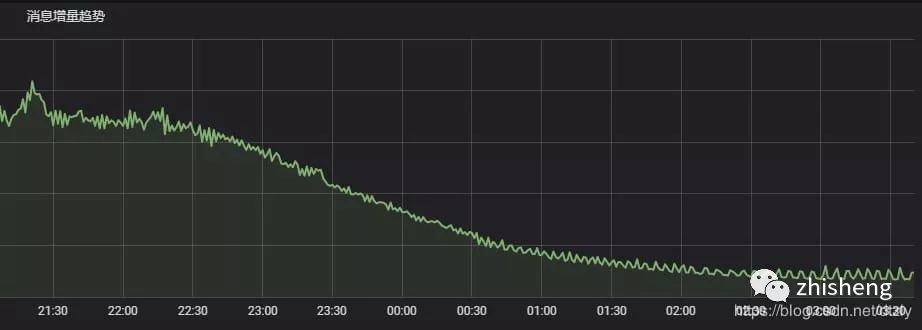
总结
当ES写入性能遇到瓶颈时,我总结的思路应该是这样:
看日志,是否有字段类型不匹配,是否有脏数据。
看CPU使用情况,集群是否异构
客户端是怎样的配置?使用的bulk 还是单条插入
查看线程堆栈,查看耗时最久的方法调用
确定集群类型:ToB还是ToC,是否允许有少量数据丢失?
针对ToB等实时性不高的集群减少副本增加刷新时间
index buffer优化 translog优化,滚动重启集群
作者:张刘毅
原文链接:https://blog.csdn.net/dtzly/article/details/101006064
END
关注我

内容总结
以上是互联网集市为您收集整理的Flink 实时写入数据到 ElasticSearch 性能调优全部内容,希望文章能够帮你解决Flink 实时写入数据到 ElasticSearch 性能调优所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。