首页 / HADOOP / Docker和hadoop
Docker和hadoop
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Docker和hadoop,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1967字,纯文字阅读大概需要3分钟。
内容图文

Docker很热,怎么形容?感觉开源除了spark技术,就是docker了,甚至把Go语言也带火了,把Go在TIOBE的排名从百名外带入主流语言的行列。
Docker快成救世主了,这么牛逼的技术,docker和hadoop碰撞出什么火花来呢,是不是得赶紧用上呢?
就不介绍具体什么是docker了,不是一门全新的技术,是基于LXC的高级容器引擎,从linux内核发展出来的轻量隔离技术。相比单纯的隔离,核心是标准化了镜像打包,部署和发布这个过程,相当于标准化了开发过程。就运行态来说,相比VM,核心优势就是轻量,劣势也明显,安全性不足,容易攻破。下图是一个VM和容器的对比:
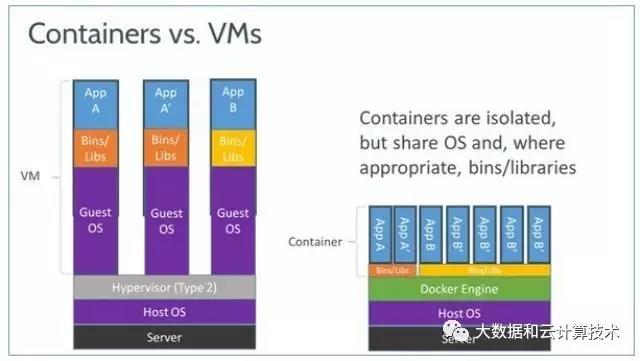
关于LXC,google的大规模集群管理工具borg号称十年前就使用上了,使用场景就是大数据场景,而且批量/实时场景号称都支持的很好,集群资源利用率也非常高,所以照这个说起来,大数据和docker渊源很深。
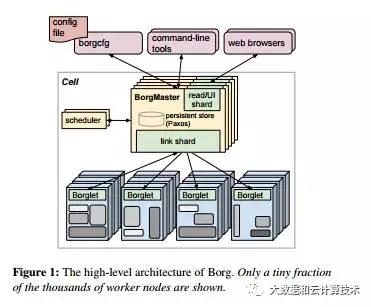
但是现实的情况是,docker在hadoop领域用的并不是很好。目前主流两种用法:
第一种方法是用Docker来直接运行Hadoop。例如hortonworks,收购了一家叫SequenceIQ的公司,通过叫Cloudbreak的技术,将Hortonworks Data Platform(HDP)打包成Docker镜像,好处是可以在微软Azure、亚马逊AWS、谷歌云平台等任何主流云平台上启动HDP。这种解决的是在多云平台部署的问题。但是这个公司被收购之后也没有更多的消息了。Github上的最后一次更新也在5个月之前。
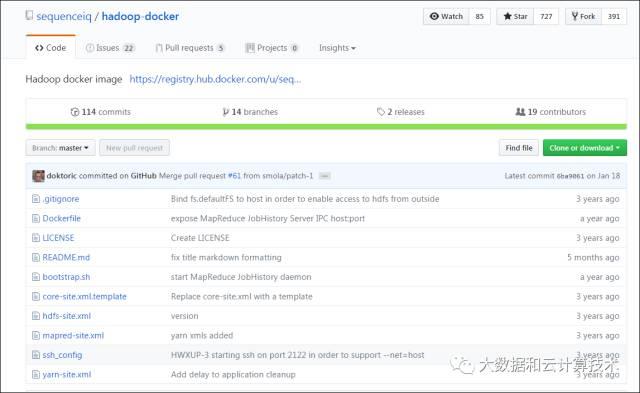
这个至多只是解决开发环境的问题,hadoop很难在不同的环境下,不调优而跑出一致的表现,天生的使用场景受限,价值有限。
第二种方法是通过YARN来使用Docker容器进行应用部署,yarn是支持docker的,具体可以看看:
http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/DockerContainerExecutor.html
yarn作为资源管理,由于其扩展能力,一直被压缩在了大数据领域,如果为了任务级别更高资源利用,通过FAIR调度算法足于,更强的隔离反而限制了资源的弹性使用。
当前资源调度更火是k8s(google主推,号称从borg发展而来)和mesos(伯克利大学主推)。瞄准的场景也更多的是应用级别,yarn支持docker处在一个很尴尬的地步。
综合来说,hadoop体系有自己的一套资源管理系统,要解决的问题是多个服务器并行调度起来当一个服务器使用的问题。而docker技术本质上和VM一样,是将一个服务器拆成多份给更多的应用使用。Docker和hadoop体系在云下物理机的场景非常有限,未来在云上替代VM解决弹性伸缩问题应该有发展。
内容总结
以上是互联网集市为您收集整理的Docker和hadoop全部内容,希望文章能够帮你解决Docker和hadoop所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。