首页 / 爬虫 / 不一样的获取数据方式——爬虫学习(1)
不一样的获取数据方式——爬虫学习(1)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了不一样的获取数据方式——爬虫学习(1),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4555字,纯文字阅读大概需要7分钟。
内容图文
")
目录
1 什么是爬虫
爬虫就是通过程序自动抓取互联网上的资源,简单说就是用程序模拟人通过浏览器访问网站并从中获取想要的信息这个过程。
2 用什么语言实现爬虫
想到爬虫最容易联想到的就是python,但往往会给人带来爬虫只能用python实现的误区。实际上想要实现爬虫也可以用Java、C实现,就好比吃饭可以用勺子,也可以用筷子或者直接用手抓,但是选择最舒服方便的方式则是最好的。之所以容易把爬虫和python关联起来就是因为python实现爬虫是最简单好用的,而且一些第三方库也能简化一些复杂的操作。所以接下来的学习我也是用python来实现。
3 爬虫合法吗
爬虫在法律上是没有被禁止的,但同时也是存在风险的(双刃剑)。
- 善意的爬虫:不破坏网站的资源,也就是正常访问,频率不高,不窃取隐私等
- 恶意的爬虫:会影响网站的正常运营,比如说疯狂访问网站资源导致网站崩溃
技术是无罪的,主要还是看怎么使用,安分守己做一个好的网络公民才是第一位。
4 web请求过程
4.1 渲染
- 服务器渲染:发送请求之后,在服务器端直接把数据和html整合在一起然后再统一返回到浏览器。也就是说在HTML源代码中是可以直接找到显示出来的数据的
- 客户端渲染:第一次请求只会返回一个HTML的骨架,第二次请求才拿到具体的数据和股价进行拼接然后展示。在源代码中是看不到数据的,但不是说这种方式就获取不了数据,只需要找到第二次请求的url即可,从而也能省去了从HTML中提取数据的过程。所以为了能够轻松找到对应的url就要先熟练使用浏览器抓包工具
4.2 抓包
在浏览器中右键选择“检查”或者直接按F12打开开发调试工具可以找到有一个Network的选项,这个选项就是用来查看网络的工作状态,可以用来查看进入这个网址之后一共会发生哪些网络请求,通过查看每个请求具体的内容便可找到真正需要的内容
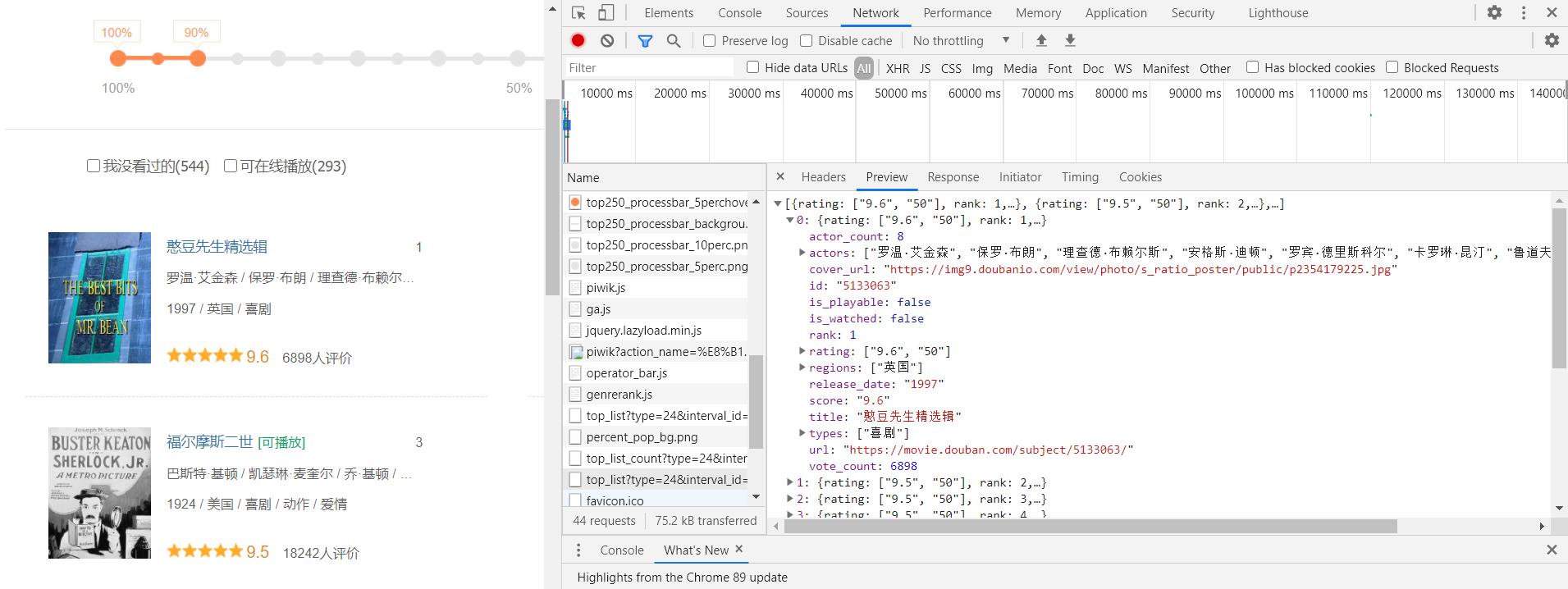
5 HTTP协议
5.1 定义
首先解释一下什么是协议:协议就是两个计算机之间为了能够正常沟通而设置的一个规定。
HTTP(hyper text transfer protocol)协议:超文本传输协议,也就是用来从服务器传输超文本到浏览器的协议。通俗说就是如果浏览器和服务器之间要传输数据就要遵守HTTP协议。
5.2 消息格式
无论是请求还是响应,HTTP协议都把一条消息分为三大部分
请求:
- 请求行:请求方式(post、get)、请求url地址 、协议
- 请求头:放服务器需要的附加信息
User-Agent:请求载体的身份标识(用哪个浏览器)
Referer:防盗链(反爬用)
cookie:本地数据信息(用户登录状态) - 请求体:请求的参数
响应:
- 状态行:协议、状态码(请求是否成功404、500)
- 响应头:放客户端需要的附加信息(cookie、密钥等等)
- 响应体:服务器返回的真正数据内容
通过浏览器的开发调试工具中的Network便能看到对应的信息
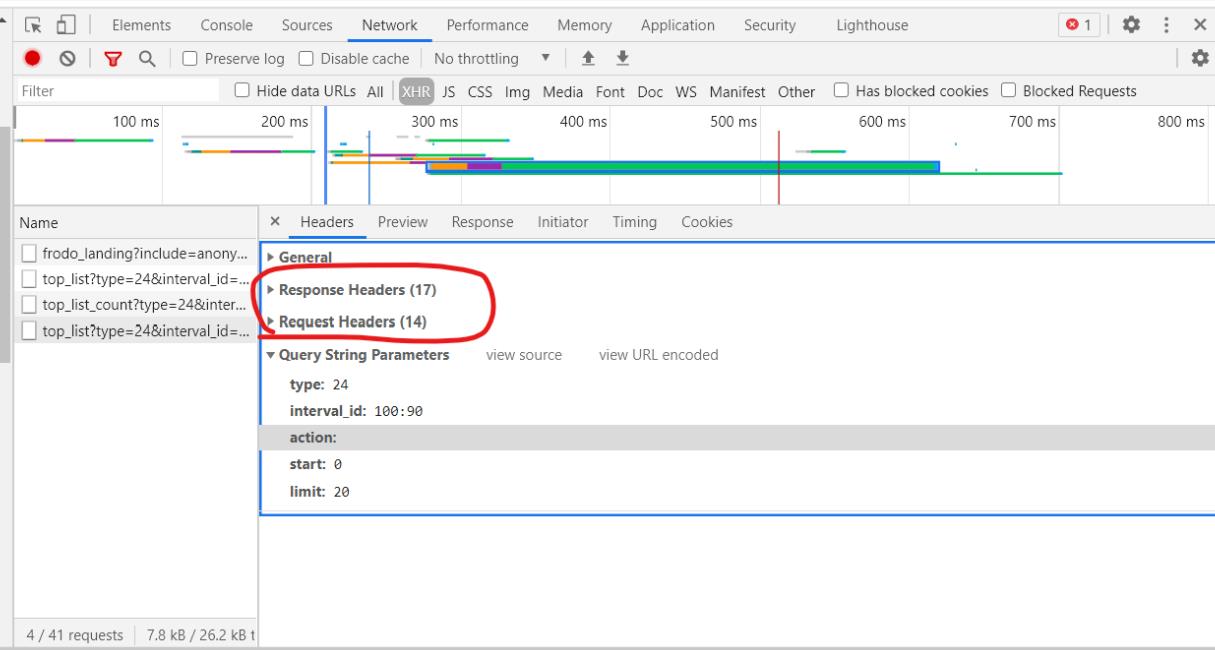
6 requests库
最简单的使用流程:
- 选择需要访问的网址:字符串形式,可直接从浏览器地址栏复制(浏览器地址栏都是用get方式访问)
- 发送请求:request.get(url)
- 查看返回结果:返回一个response对象,如果需要查看页面源代码就选择text属性
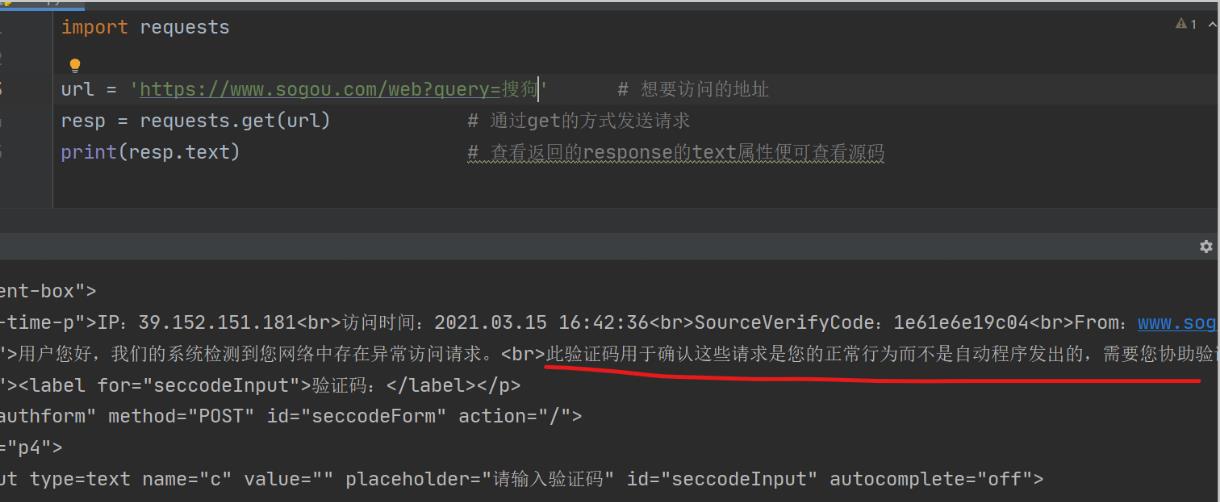
上图虽然能够正常发送请求,但是服务器可能会有反爬的机制,判断出了是一个程序自动访问网站而不是人在进行操作,所以会提示错误。为了解决这个问题,就要用到之前说的抓包来把程序伪装成一个人在用浏览器访问网站。
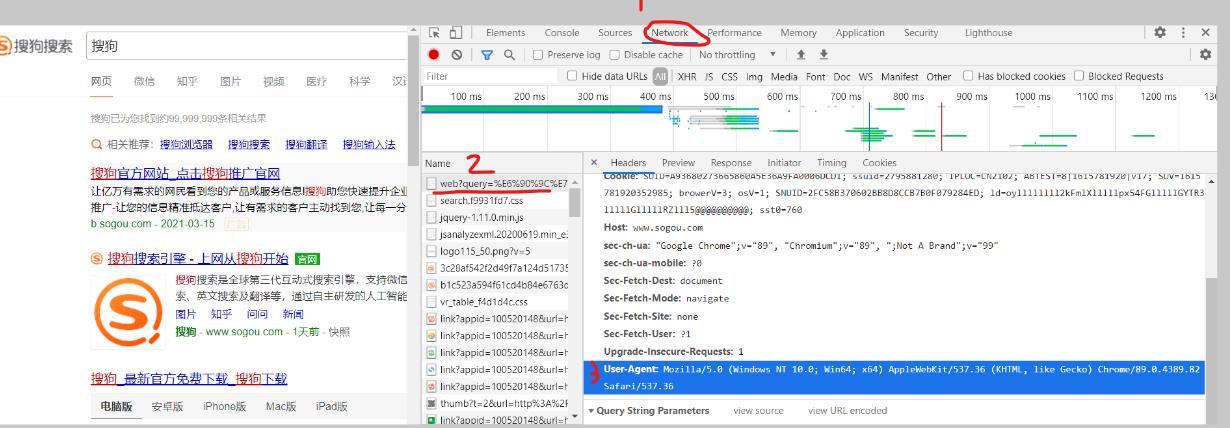
在浏览器中打开对应的网站,然后在开发调试工具中的Network里选择第一条请求,找到请求头中的User-Agent,把对应的内容放到程序中的请求头中便可伪装成浏览器。
…
import requests
url = 'https://www.sogou.com/web?query=搜狗' # 想要访问的地址
myHeaders = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"
} # 请求头,伪装成浏览器访问
resp = requests.get(url, headers=myHeaders) # 通过get的方式发送请求
print(resp.text) # 查看返回的response的text属性便可查看源码
7 简单爬虫例子
-
爬虫一定需要一个url,一般来说都是带有参数的,但是很长的一串字符串非常难看,所以可以把地址和参数分开(问号之前是地址,之后是参数)。参数单独放在一个字典里,在发送请求的时候再单独作为一个整体的参数放进去即可。
具体用到了哪些参数可以直接从开发调试工具中的Network找到具体的请求,其中的Query String Parameters里就是所有的参数,复制到程序中就好了。
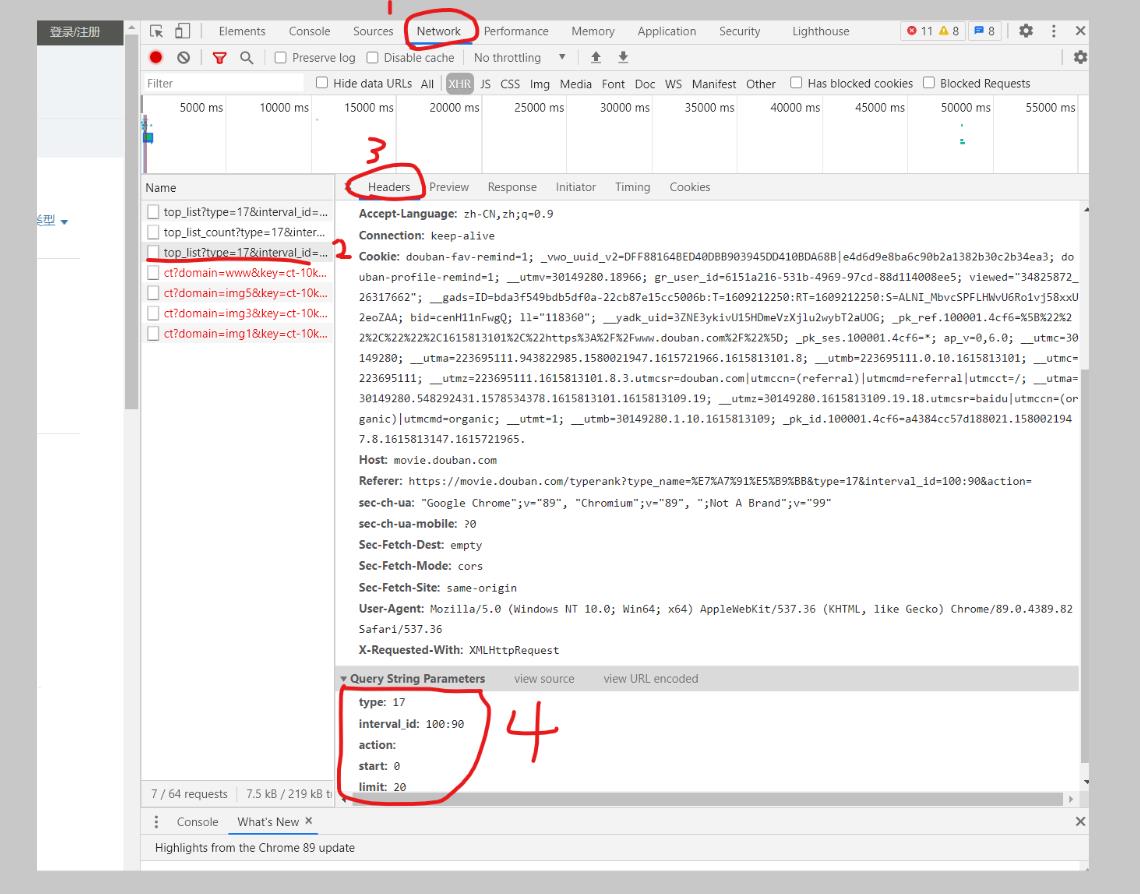
-
直接爬取下来的数据可能会是乱码,可以对response.text执行encode()方法修改编码方式,需要改成什么编码可以从开发调试工具对应的请求的Response Headers中找到;第二种方法是使用response.json()把数据转换成json格式
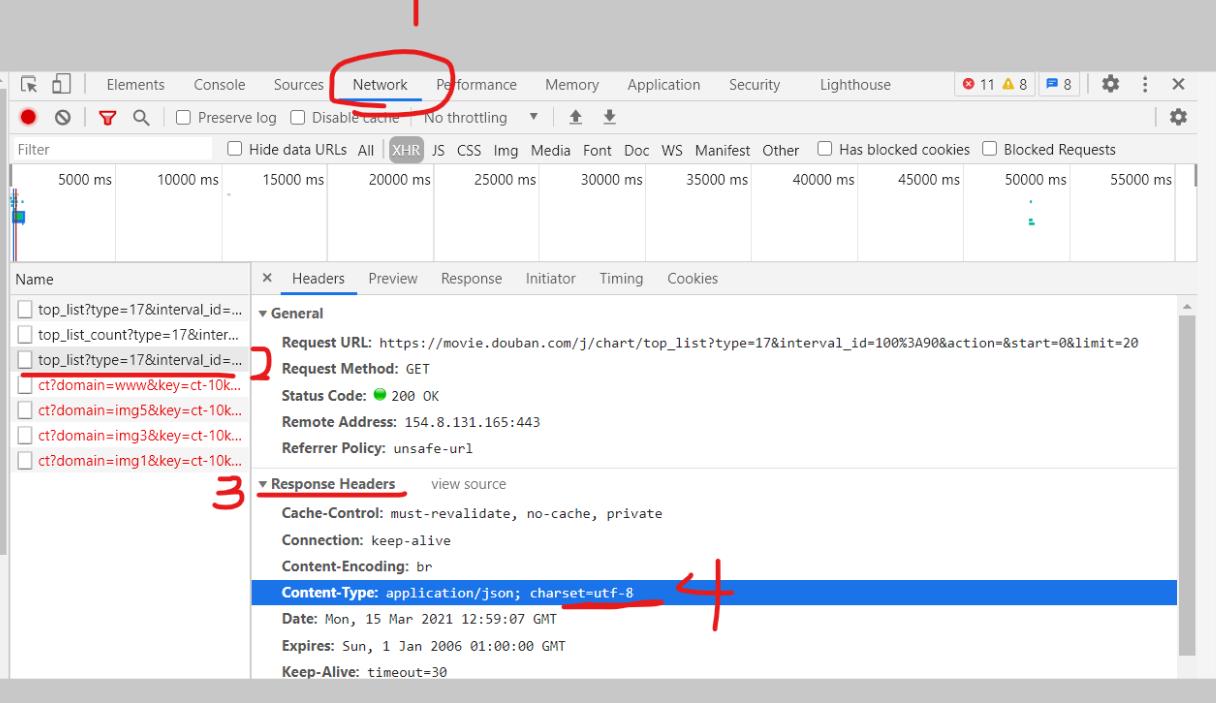
-
直接爬取可能会遭到反爬,所以最好还是加上请求头的User-Agent
-
爬取结束后一定要关掉response对象,否则时间久了可能会被服务器拉到黑名单就爬不了了
import requests
url = 'https://movie.douban.com/j/chart/top_list' # 需要访问的地址
# 请求的参数
params = {
'type': '17',
'interval_id': '100:90',
'action': '',
'start': 0,
'limit': 100,
}
# 请求头,模拟浏览器访问
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
resp = requests.get(url=url, params=params, headers=headers) # 发送请求
# 把爬下来的数据以json格式输出
for data in resp.json():
print(data)
resp.close() # 关闭response
内容总结
以上是互联网集市为您收集整理的不一样的获取数据方式——爬虫学习(1)全部内容,希望文章能够帮你解决不一样的获取数据方式——爬虫学习(1)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。