Hadoop文件合并——Hadoop In Action上的一个示例
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hadoop文件合并——Hadoop In Action上的一个示例,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2729字,纯文字阅读大概需要4分钟。
内容图文

上一篇文章已经详细的说明了如何在Eclipse下面远程连接Hadoop集群,进行Hadoop程序开发。这里说明一个Hadoop In Action书上的一个示例,可能是由于Hadoop版本更新的问题,导致树上的一些个示例程序没有办法正常执行。
整个代码的工作就是把本地目录下个若干个小文件,合并成一个较大的文件,写入到HDFS中。话不多说,代码如下:
package com.hadoop.examples;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
/**
* @Package
* @ClassName: PutMerge
* @Description: 读取本地目录下的文件,写入到HDFS,在写入的过程中,
* 把这三个文件合成一个文件
* @author lxy
* @date 2015年3月25日 上午9:59:38
* @version V1.0
*/
public class PutMerge {
public static void main(String[] args) throws IOException {
// 输入目录,目录下有三个txt,文章最后面会儿给出文件内容
String localPathStr = "E:\\test";
// 输出目录,HDFS路径,文章最后面会给出合并之后的文件内容
String serverPath =
"hdfs://192.168.3.57:8020/user/lxy/mergeresult/merge.txt";
//输入目录,是一个本地目录
Path inputDir = new Path(localPathStr);
//输出目录,是一个HDFS路径
Path hdfsFile = new Path(serverPath);
Configuration conf = new Configuration();
/**
* Hadoop in Action的原代码如下
* FileSystem hdfs = FileSystem.get(conf);
* 但是这样的话,在执行下面的语句是就会报异常,可能是由于版本更新的问题
* FSDataOutputStream out = hdfs.create(hdfsFile);
*/
// 根据上面的serverPath,获取到的是一个org.apache.hadoop.hdfs.DistributedFileSystem对象
FileSystem hdfs = FileSystem.get(URI.create(serverPath), conf);
FileSystem local = FileSystem.getLocal(conf);
try {
//获取输入目录下的文件以及文件夹列表
FileStatus[] inputFiles = local.listStatus(inputDir);
//在hdfs上创建一个文件
FSDataOutputStream out = hdfs.create(hdfsFile);
for (int i = 0; i < inputFiles.length; i++) {
System.out.println(inputFiles[i].getPath().getName());
//打开本地输入流
FSDataInputStream in = local.open(inputFiles[i].getPath());
byte buffer[] = new byte[256];
int bytesRead = 0;
while ((bytesRead = in.read(buffer)) > 0) {
//往hdfs上的文件写数据
out.write(buffer, 0, bytesRead);
}
//释放资源
in.close();
}
//释放资源
out.close();
}
catch (IOException e) {
e.printStackTrace();
}
}
}
我的测试目录下有三个txt文件
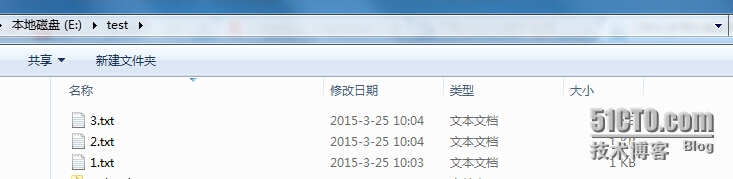 650) this.width=650;" src="/upload/getfiles/default/2022/11/14/20221114105318234.jpg" title="输入数据" />
650) this.width=650;" src="/upload/getfiles/default/2022/11/14/20221114105318234.jpg" title="输入数据" /> 1.txt
1 hello Hadoop 2 hello Hadoop 3 hello Hadoop 4 hello Hadoop 5 hello Hadoop 6 hello Hadoop 7 hello Hadoop
2.txt
8 hello Hadoop 9 hello Hadoop 10 hello Hadoop 11 hello Hadoop 12 hello Hadoop 13 hello Hadoop 14 hello Hadoop
3.txt
15 hello Hadoop 16 hello Hadoop 17 hello Hadoop 18 hello Hadoop 19 hello Hadoop 20 hello Hadoop 21 hello Hadoop
合并之后的文件如下所示:
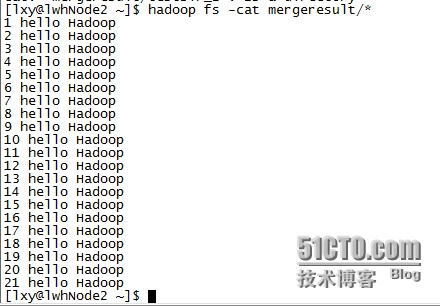 650) this.width=650;" src="/upload/getfiles/default/2022/11/14/20221114105318530.jpg" title="合并之后的文件" />
650) this.width=650;" src="/upload/getfiles/default/2022/11/14/20221114105318530.jpg" title="合并之后的文件" />本文出自 “艾斯的梦想” 博客,请务必保留此出处http://acesdream.blog.51cto.com/10029622/1625442
原文:http://acesdream.blog.51cto.com/10029622/1625442
内容总结
以上是互联网集市为您收集整理的Hadoop文件合并——Hadoop In Action上的一个示例全部内容,希望文章能够帮你解决Hadoop文件合并——Hadoop In Action上的一个示例所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。