分享一个简单的python+mysql网络数据抓取
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了分享一个简单的python+mysql网络数据抓取,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2976字,纯文字阅读大概需要5分钟。
内容图文

最近学习python网络爬虫,所以自己写了一个简单的程序练练手(呵呵。。)。我使用的环境是python3.6和mysql8.0,抓取目标网站为百度热点(http://top.baidu.com/)。我只抓取了实时热点内容,其他栏目应该类似。代码中有两个变量SECONDS_PER_CRAWL和CRAWL_PER_UPDATE_TO_DB,前者为抓取频率,后者为抓取多少次写一次数据库,可自由设置。我抓取的数据内容是热点信息,链接,关注人数和时间。其在内存中存放的结构为dict{tuple(热点信息,链接):list[tuple(关注人数,时间)...]...},数据库存储是将热点信息和链接放到hotnews表中,关注人数和对应时间放到直接以热点信息为表名的表内(因为热点信息可能长时间存在但是随时间变化关注度会有变化)。下面可以看下数据库存放样例
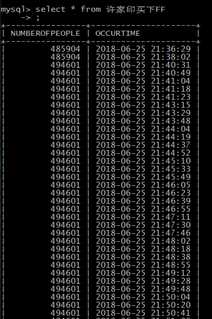
代码比较简单我就暂时没有上传github直接贴到下面供大家参考:
1
#
-*- coding: UTF-8 -*-
2
3
from bs4 import BeautifulSoup
4import threading
5import requests
6import pymysql
7import string
8import time
9import sys
10import re
111213#爬取频率,单位:秒14 SECONDS_PER_CRAWL = 10
1516#更新到数据库频率,单位:爬取次数17 CRAWL_PER_UPDATE_TO_DB = 1
1819#爬取目标网站url20 CRAWL_TARGET_URL = ‘http://top.baidu.com/‘2122class DataProducer(threading.Thread):
2324#临时存放爬取结果25 NewsDict = {}
2627def__init__(self):
28 threading.Thread.__init__(self)
29 db = pymysql.connect(host="localhost", user="root", port=3306, passwd=None, db="crawler", charset="utf8")
30 cursor = db.cursor()
31 sql = """CREATE TABLE IF NOT EXISTS HOTNEWS (
32 INFORMATION VARCHAR(64) NOT NULL,
33 HYPERLINK VARCHAR(256),
34 PRIMARY KEY (INFORMATION) );"""35 cursor.execute(sql)
36 db.close()
3738def run(self):
39print("DataProducer Thread start!")
40 crawl_data(self.NewsDict)
41print("DataProducer Thread exit!")
424344def crawl_data(nd):
45 count = 0;
46while 1:
47 req = requests.get(url=CRAWL_TARGET_URL)
48 req.encoding = req.apparent_encoding
49 bf = BeautifulSoup(req.text, "html.parser")
50 texts = bf.find_all(‘ul‘, id="hot-list", class_="list")
51 bfs = BeautifulSoup(str(texts), "html.parser")
52 spans = bfs.find_all(‘span‘, class_ = re.compile("icon-fall|icon-rise|icon-fair"))
53 lis = bfs.find_all(‘a‘, class_ = "list-title")
54for i in range(10):
55 vtup = (spans[i].get_text(), time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
56 ktup = (lis[i].get(‘title‘), lis[i].get(‘href‘))
57if ktup in nd.keys():
58 nd[ktup].append(vtup)
59else:
60 nd[ktup] = [vtup]
61 count = count+1
62if count%CRAWL_PER_UPDATE_TO_DB == 0:
63 update_to_db(nd)
64 nd.clear()
65 time.sleep(SECONDS_PER_CRAWL)
6667def update_to_db(nd):
68 db = pymysql.connect(host="localhost", user="root", port=3306, passwd=None, db="crawler", charset="utf8")
69 cursor = db.cursor()
70for k in nd.keys():
71#将热点插入至主表72 sql1 = "REPLACE INTO HOTNEWS (INFORMATION, HYPERLINK) VALUES ( ‘%s‘, ‘%s‘);"73#热点创建其分表74 sql2 = "CREATE TABLE IF NOT EXISTS `%s`( NUMBEROFPEOPLE INT NOT NULL, OCCURTIME DATETIME, PRIMARY KEY (OCCURTIME) );"75try:
76 cursor.execute(sql1%(k[0], k[1]))
77 cursor.execute(sql2%(k[0]))
78 db.commit()
79except:
80 db.rollback()
81#将每个热点数据插入到对应热点分表82for e in nd[k]:
83 insert_sql = "INSERT INTO %s (NUMBEROFPEOPLE, OCCURTIME) VALUES (%d, ‘%s‘);"84try:
85 cursor.execute(insert_sql%(k[0], int(e[0]), e[1]))
86except:
87 db.rollback()
88 db.close()
8990if__name__ == ‘__main__‘:
91 t = DataProducer()
92 t.start()
93 t.join()
原文:https://www.cnblogs.com/prophet-ss/p/9231827.html
内容总结
以上是互联网集市为您收集整理的分享一个简单的python+mysql网络数据抓取全部内容,希望文章能够帮你解决分享一个简单的python+mysql网络数据抓取所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。