Node.js实战--资源压缩与zlib模块
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Node.js实战--资源压缩与zlib模块,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3337字,纯文字阅读大概需要5分钟。
内容图文


??Blog:《NodeJS模块研究 - zlib》
??Github:https://github.com/dongyuanxin/blog
nodejs 的 zlib 模块提供了资源压缩功能。例如在 http 传输过程中常用的 gzip,能大幅度减少网络传输流量,提高速度。本文将从下面几个方面介绍 zlib 模块和相关知识点:
-
文件压缩 / 解压 -
HTTP 中的压缩/解压 -
压缩算法:RLE -
压缩算法:哈夫曼树
文件的压缩/解压
以 gzip 压缩为例,压缩代码如下:
const zlib = require("zlib");
const fs = require("fs");
const gzip = zlib.createGzip();
const rs = fs.createReadStream("./db.json");
const ws = fs.createWriteStream("./db.json.gz");
rs.pipe(gzip).pipe(ws);
如下图所示,4.7Mb 大小的文件被压缩到了 575Kb。

解压刚才压缩后的文件,代码如下:
const zlib = require("zlib");
const fs = require("fs");
const gunzip = zlib.createGunzip();
const rs = fs.createReadStream("./db.json.gz");
const ws = fs.createWriteStream("./db.json");
rs.pipe(gunzip).pipe(ws);
HTTP 中的压缩/解压
在服务器中和客户端的传输过程中,浏览器(客户端)通过 Accept-Encoding 消息头来告诉服务端接受的压缩编码,服务器通过 Content-Encoding 消息头来告诉浏览器(客户端)实际用于编码的算法。
服务器代码示例如下:
const zlib = require("zlib");
const fs = require("fs");
const http = require("http");
const server = http.createServer((req, res) => {
const rs = fs.createReadStream("./index.html");
// 防止缓存错乱
res.setHeader("Vary", "Accept-Encoding");
// 获取客户端支持的编码let acceptEncoding = req.headers["accept-encoding"];
if (!acceptEncoding) {
acceptEncoding = "";
}
// 匹配支持的压缩格式if (/\bdeflate\b/.test(acceptEncoding)) {
res.writeHead(200, { "Content-Encoding": "deflate" });
rs.pipe(zlib.createDeflate()).pipe(res);
} elseif (/\bgzip\b/.test(acceptEncoding)) {
res.writeHead(200, { "Content-Encoding": "gzip" });
rs.pipe(zlib.createGzip()).pipe(res);
} elseif (/\bbr\b/.test(acceptEncoding)) {
res.writeHead(200, { "Content-Encoding": "br" });
rs.pipe(zlib.createBrotliCompress()).pipe(res);
} else {
res.writeHead(200, {});
rs.pipe(res);
}
});
server.listen(4000);
客户端代码就很简单了,识别 Accept-Encoding 字段,并进行解压:
const zlib = require("zlib");
const http = require("http");
const fs = require("fs");
const request = http.get({
host: "localhost",
path: "/index.html",
port: 4000,
headers: { "Accept-Encoding": "br,gzip,deflate" }
});
request.on("response", response => {
const output = fs.createWriteStream("example.com_index.html");
switch (response.headers["content-encoding"]) {
case"br":
response.pipe(zlib.createBrotliDecompress()).pipe(output);
break;
// 或者, 只是使用 zlib.createUnzip() 方法去处理这两种情况:case"gzip":
response.pipe(zlib.createGunzip()).pipe(output);
break;
case"deflate":
response.pipe(zlib.createInflate()).pipe(output);
break;
default:
response.pipe(output);
break;
}
});
从上面的例子可以看出来,3 种对应的解压/压缩 API:
-
zlib.createInflate()和zlib.createDeflate() -
zlib.createGunzip()和zlib.createGzip() -
zlib.createBrotliDecompress()和zlib.createBrotliCompress()
压缩算法:RLE
RLE 全称是 Run Length Encoding, 行程长度编码,也称为游程编码。它的原理是:记录连续重复数据的出现次数。它的公式是:字符 * 出现次数。
例如原数据是 AAAAACCPPPPPPPPERRPPP,一共 18 个字节。按照 RLE 的规则,压缩后的结果是:A5C2P8E1R2P3,一共 12 个字节。压缩比例是:12 / 17 = 70.6%
RLE 的优点是压缩和解压非常快,针对连续出现的多个字符的数据压缩率更高。但对于ABCDE类似的数据,压缩后数据会更大。
压缩算法:哈夫曼树
哈夫曼树的原理是:出现频率越高的字符,用尽量更少的编码来表示。按照这个原理,以数据ABBCCCDDDD为例:
| 字符 | 编码(二进制) |
|---|---|
| D | 0 |
| C | 1 |
| B | 10 |
| A | 11 |
原来的数据是 10 个字节。那么编码后的数据是:1110101110000,一共 13bit,在计算机中需要 2 个字节来存储。这样的压缩率是:2 / 10 = 20%。
但是仅仅按照这个原理编码后的数据,无法正确还原。以前 4bit 为例,1110可以理解成:
-
11 + 10 -
1 + 1 + 1 + 0 -
1 + 1 + 10 -
...
而哈夫曼树的设计就很巧妙,能正确还原。哈夫曼树的构造过程如下:
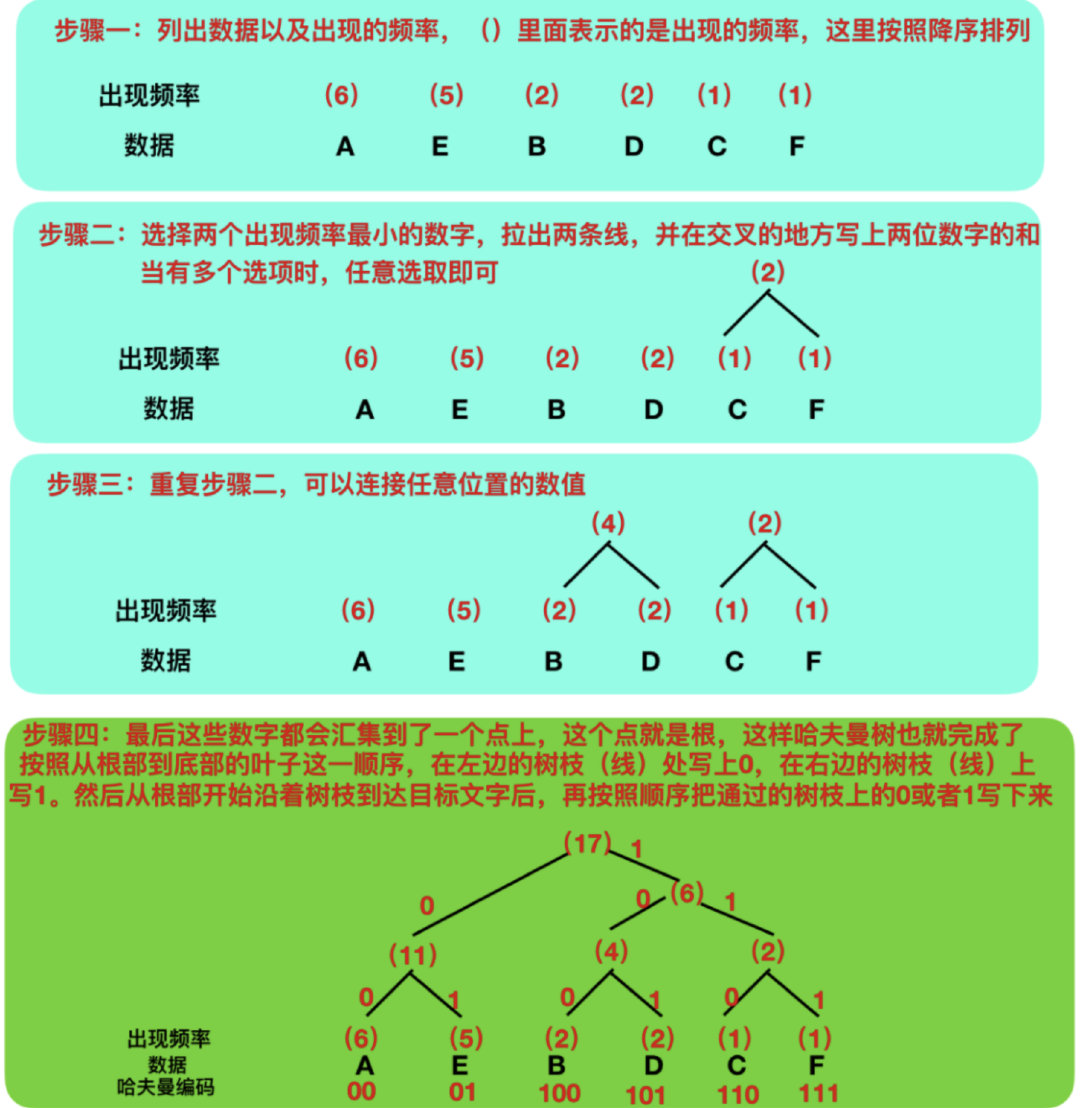
无论哪种数据类型(文本文件、图像文件、EXE 文件),都可以采用哈夫曼树进行压缩。
参考链接
??扫码关注「心谭博客」,查看「前端图谱」&「算法题解」,坚持分享,共同成长??

原文:https://www.cnblogs.com/geyouneihan/p/12296740.html
内容总结
以上是互联网集市为您收集整理的Node.js实战--资源压缩与zlib模块全部内容,希望文章能够帮你解决Node.js实战--资源压缩与zlib模块所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。