首页 / 爬虫 / Web爬虫|入门实战之糗事百科(附源码)
Web爬虫|入门实战之糗事百科(附源码)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Web爬虫|入门实战之糗事百科(附源码),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4153字,纯文字阅读大概需要6分钟。
内容图文
")
coding by real mind writing by genuine heart

解析
任务背景:https://www.qiushibaike.com/hot/
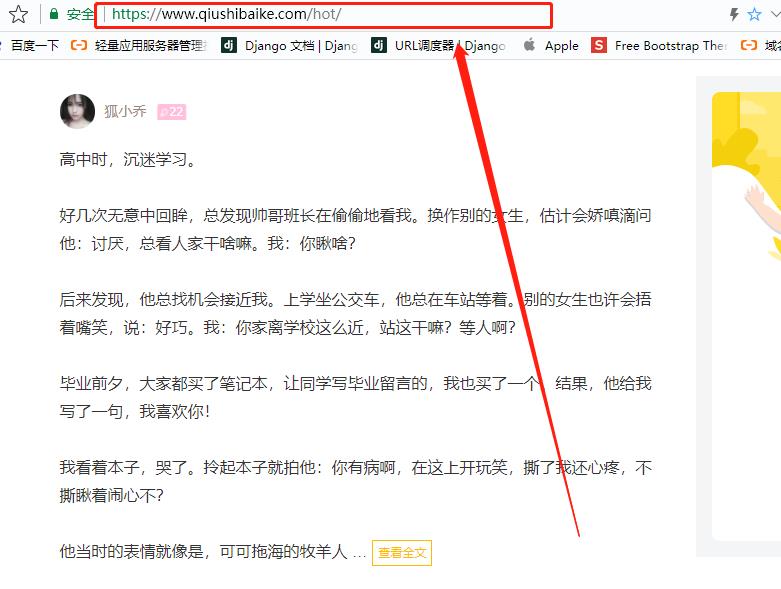
窥探网页细节:观察每一页URL的变化
第一页
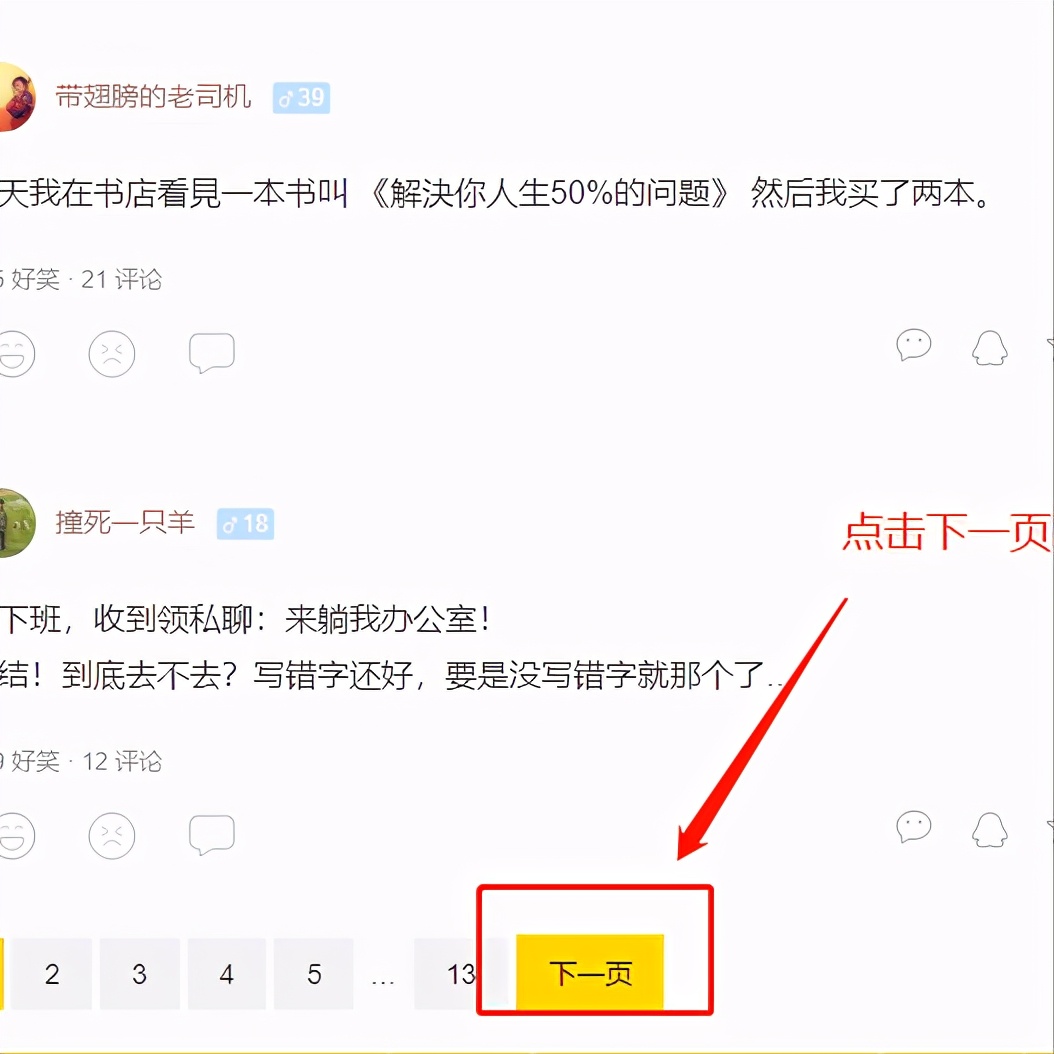
进入第二页
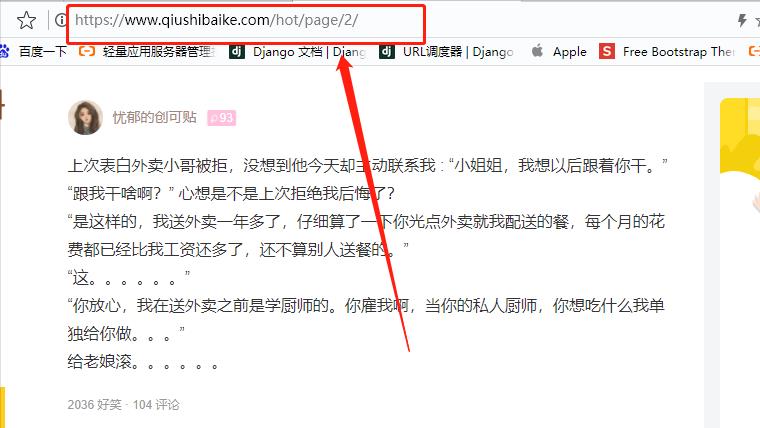
再看看第三页
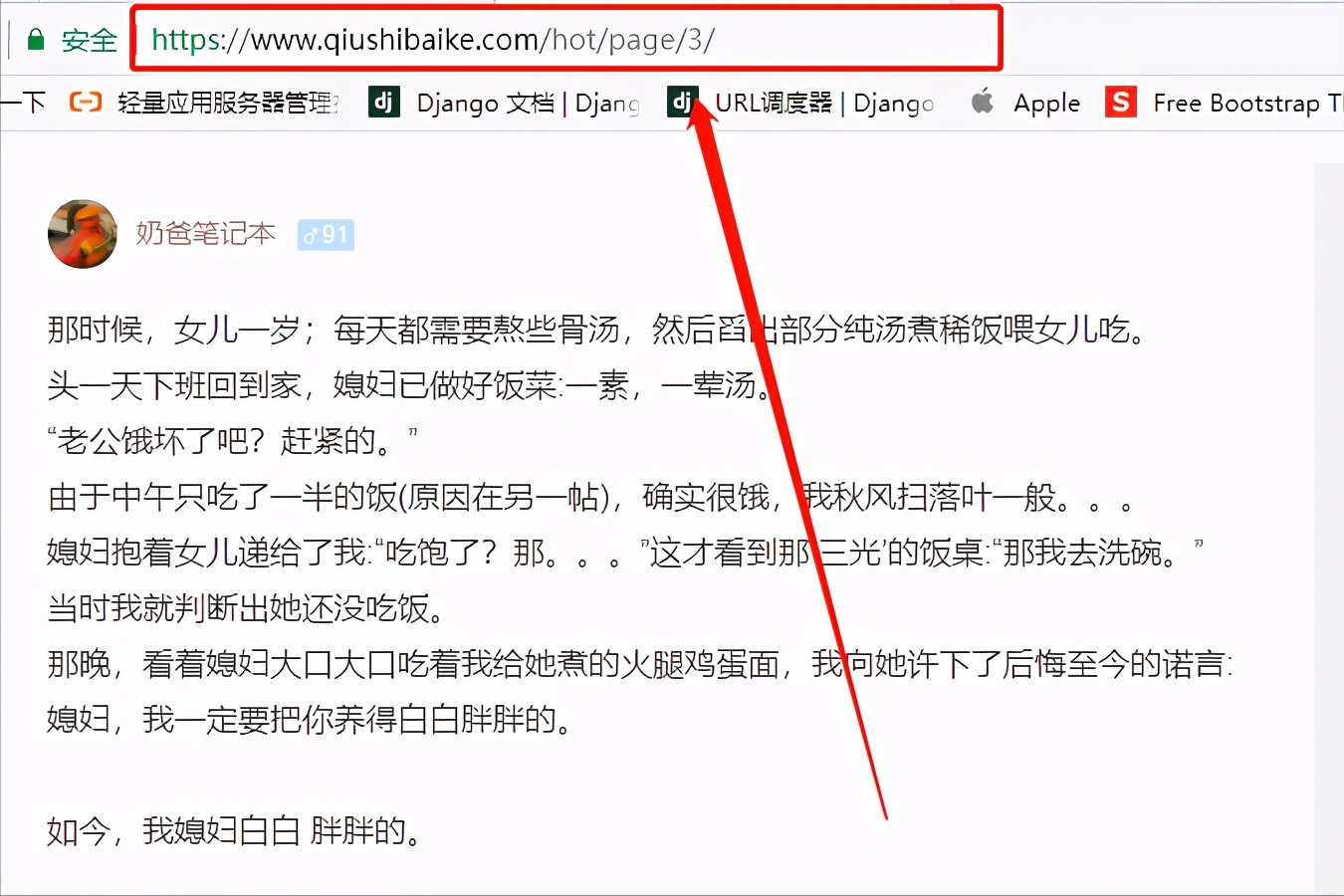
把这些URL放在一起,观察规律
1 https://www.qiushibaike.com/hot/page/1/
2 https://www.qiushibaike.com/hot/page/2/
3 https://www.qiushibaike.com/hot/page/3/
从图片可以看出,该URL其他地方不变,只有最后的数字会改变,代表页数
推荐使用浏览器Chrome
插件丰富,原生功能设计对爬虫开发者非常友好
分析网页源代码
通过在原来的页面上点击,选择“检查”,观察规律,这里建议当你用elements定位元素之后,就切换到network查看相应的元素,因为elements里面的网页源代码很可能是经过JS加工过的
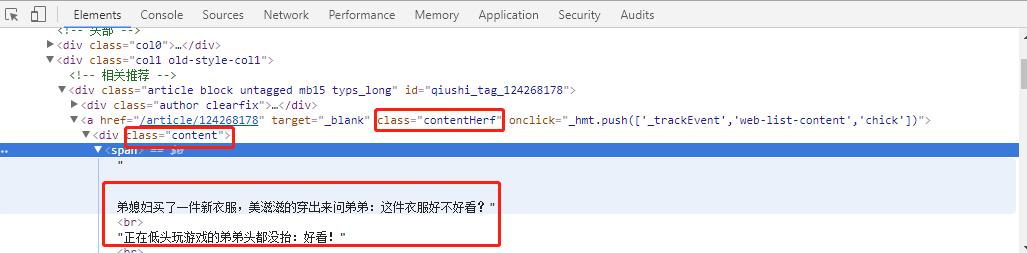
通过图片,我们发现:每一个笑话内容,都包含在一个<a...class="contentHerf"
...class="content">里面,当然这里的属性不止一个,这里我们选择contentHerf这个属性
思考工具:什么工具最适合解析此种规律?BeautifulSoup
编码
根据第一步的分析,建立初步的代码
1
import
requests
2
from bs4 import BeautifulSoup
3import time
4import re
5 6 headers = {
7‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36‘,
8#User-Agent可以伪装浏览器,键值为浏览器的引擎信息及版本 9‘Host‘:‘www.qiushibaike.com‘,
10‘Cookie‘:‘_ga=GA1.2.2026142502.1558849033; gr_user_id=5d0a35ad-3eb6-4037-9b4d-bbc5e22c9b9f; grwng_uid=9bd612b3-7d0b-4a08-a4e1-1707e33f6995; _qqq_uuid_="2|1:0|10:1617119039|10:_qqq_uuid_|56:NjUxYWRiNDFhZTYxMjk4ZGM3MTgwYjkxMGJjNjViY2ZmZGUyNDdjMw==|fdce75d742741575ef41cd8f540465fb97b5d18891a9abb0849b3a09c530f7ee"; _xsrf=2|6d1ed4a0|7de9818067dac3b8a4e624fdd75fc972|1618129183; Hm_lvt_2670efbdd59c7e3ed3749b458cafaa37=1617119039,1617956477,1618129185; Hm_lpvt_2670efbdd59c7e3ed3749b458cafaa37=1618129185; ff2672c245bd193c6261e9ab2cd35865_gr_session_id=fd4b35b4-86d1-4e79-96f4-45bcbcbb6524; ff2672c245bd193c6261e9ab2cd35865_gr_session_id_fd4b35b4-86d1-4e79-96f4-45bcbcbb6524=true‘11#Cookie里面保存了你的身份验证信息,可用于cookies反爬12 }
1314for page in range(10):
15 url = f‘https://www.qiushibaike.com/hot/page/{page}/‘#f-string函数,{}中填的是变化的内容,也可以使用format函数16 req = requests.get(url,headers=headers)
17 html = req.text
1819 soup = BeautifulSoup(html,‘lxml‘)
20for joke in soup.select(‘.contentHerf .content span‘):
21if joke.string isnot None:
22 joke_data = f‘笑话一则:{joke.string.strip()}\n\n‘23 with open(‘../txt_file/joke.txt‘,‘ab‘) as f: #以追加二进制的形式写入到文本文件中,这样就不会替换掉原先的内容24 pattern = re.compile(‘查看全文‘,re.S)
25 jok = re.sub(pattern,‘这里被替换了,嘻嘻!‘,joke_data)
26 f.write(jok.encode(‘utf-8‘))
27 time.sleep(1) #延迟爬取时间
查看爬取内容

上面这张图片被框起来的地方被我用正则表达式替换掉了,这里原来的内容是“查看全文”
代码优化
1
import
requests
2
from bs4 import BeautifulSoup
3import re
4import time
5from requests.exceptions import RequestException
6 7 8def get_url_html():
9 headers = {
10‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36‘,
11‘Host‘:‘www.qiushibaike.com‘,
12‘Cookie‘:‘_ga=GA1.2.2026142502.1558849033; gr_user_id=5d0a35ad-3eb6-4037-9b4d-bbc5e22c9b9f; grwng_uid=9bd612b3-7d0b-4a08-a4e1-1707e33f6995; _qqq_uuid_="2|1:0|10:1617119039|10:_qqq_uuid_|56:NjUxYWRiNDFhZTYxMjk4ZGM3MTgwYjkxMGJjNjViY2ZmZGUyNDdjMw==|fdce75d742741575ef41cd8f540465fb97b5d18891a9abb0849b3a09c530f7ee"; _xsrf=2|6d1ed4a0|7de9818067dac3b8a4e624fdd75fc972|1618129183; Hm_lvt_2670efbdd59c7e3ed3749b458cafaa37=1617119039,1617956477,1618129185; Hm_lpvt_2670efbdd59c7e3ed3749b458cafaa37=1618129185; ff2672c245bd193c6261e9ab2cd35865_gr_session_id=fd4b35b4-86d1-4e79-96f4-45bcbcbb6524; ff2672c245bd193c6261e9ab2cd35865_gr_session_id_fd4b35b4-86d1-4e79-96f4-45bcbcbb6524=true‘1314 }
1516try:
17for page in range(2,5):
18 url = f‘https://www.qiushibaike.com/hot/page/{page}/‘19 req = requests.get(url,headers=headers)
20if req innot None:
21return req.text
22else:
23return None
24except RequestException:
25return None
2627def main():
28 html = get_url_html()
29 soup = BeautifulSoup(html,‘lxml‘)
30for joke in soup.select(‘.contentHerf .content span‘):
31if joke.string isnot None:
32 joke_data = f‘笑话一则:{joke.string.strip()}\n\n‘33 with open(‘../txt_file/joke.txt‘,‘ab‘) as f:
34 pattern = re.compile(‘查看全文‘,re.S)
35 jok = re.sub(pattern,‘这里被替换了,嘻嘻!‘,joke_data)
36 f.write(joke.encode(‘utf-8‘))
37383940if__name__ == ‘__main__‘:
41 main()
42 time.sleep(1)
总结
请求库requests及exceptions模块
解析库BeautifulSoup
标准库re
time模块
文本存储
定期分享爬虫实战文章 扫码关注个人公众号, 带你成为 “爬虫大神” or “爬虫工程师”
—— —— —— —— — END —— —— —— —— ————
欢迎扫码关注我的公众号
爬神养成记

原文:https://www.cnblogs.com/makerchen/p/14716994.html
内容总结
以上是互联网集市为您收集整理的Web爬虫|入门实战之糗事百科(附源码)全部内容,希望文章能够帮你解决Web爬虫|入门实战之糗事百科(附源码)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。