python爬取豆瓣250存入mongodb全纪录
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python爬取豆瓣250存入mongodb全纪录,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3822字,纯文字阅读大概需要6分钟。
内容图文

用了一周的时间总算搞定了,跨过了各种坑,总算调试成功了,记录如下:
1、首先在cmd中用命令行建立douban爬虫项目
scrapy startproject douban
2、我用的是pycharm,导入项目后,
1)在items.py中定义爬取的字段
items.py代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# -*- coding: utf-8 -*-
import scrapyclass DoubanBookItem(scrapy.Item):
name
= scrapy.Field() # 书名
price
= scrapy.Field() # 价格
edition_year
= scrapy.Field() # 出版年份
publisher
= scrapy.Field() # 出版社
ratings
= scrapy.Field() # 评分
author
= scrapy.Field() # 作者
content
= scrapy.Field() |
2)在spiders文件夹下建立一个新的爬虫bookspider.py,爬取网页的代码都在这里写。
以下是爬虫bookspider.py代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
# -*- coding:utf-8 -*-
import scrapyfrom douban.items import DoubanBookItemclass BookSpider(scrapy.Spider):
name
= ‘douban-book‘
allowed_domains
= [‘douban.com‘]
start_urls
= [
‘https://book.douban.com/top250‘
]
def parse(self, response):
# 请求第一页
yield scrapy.Request(response.url, callback=self.parse_next)
# 请求其它页
for page in response.xpath(‘//div[@]/a‘):
link
= page.xpath(‘@href‘).extract()[0]
yield scrapy.Request(link, callback=self.parse_next)
def parse_next(self, response):
for item in response.xpath(‘//tr[@]‘):
book
= DoubanBookItem()
book[
‘name‘
]
= item.xpath(‘td[2]/div[1]/a/@title‘).extract()[0]
book[
‘content‘
]
= item.xpath(‘td[2]/p/text()‘).extract()[0]
# book_info = item.xpath("td[2]/p[1]/text()").extract()[0]
# book_info_content = book_info.strip().split(" / ")
# book["author"] = book_info_content[0]
# book["publisher"] = book_info_content[-3]
# book["edition_year"] = book_info_content[-2]
# book["price"] = book_info_content[-1]
book[
‘ratings‘
]
= item.xpath(‘td[2]/div[2]/span[2]/text()‘).extract()[0]
yield book |
3)在settings.py文件中配置请求头及mongodb信息
from faker import Factoryf = Factory.create()USER_AGENT = f.user_agent()
DEFAULT_REQUEST_HEADERS = { ‘Host‘: ‘book.douban.com‘,‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘,‘Accept-Language‘: ‘zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3‘,‘Accept-Encoding‘: ‘gzip, deflate, br‘,‘Connection‘: ‘keep-alive‘,}
|
1
2
3
4
|
<br data
-
filtered
=
"filtered"
>MONGODB_HOST
= "127.0.0.1" //在本机调试就这个地址MONGODB_PORT
= 27017 //默认端口号MONGODB_DBNAME
= "jkxy" //数据库名字MONGODB_DOCNAME
= "Book" //集合名字,相当于表名 |
4)在pipelines.py中编写处理代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# -*- coding: utf-8 -*-
# form scrapy.conf import settings 已经过时不用了,采用下面的方法引入settings
from scrapy.utils.project import get_project_settings //因mongodb的host地址,端口号等都在settings中配置的,所以要把该文件导入进来。settings
= get_project_settings()import pymongo //导入mongodb连接模块class DoubanBookPipeline(object):
def __init__(self):
host
= settings["MONGODB_HOST"] //从settings中取出host地址
port
= settings["MONGODB_PORT"]
dbname
= settings["MONGODB_DBNAME"]
client
= pymongo.MongoClient(host=host,port=port) // 创建一个MongoClient实例
tdb
= client[dbname] //创建jkxy数据库,dbname=“jkxy”
self
.post
= tdb[settings["MONGODB_DOCNAME"]] //创建数据库集合Book,相当于创建表
def process_item(self, item, spider):
info
= item[‘content‘].split(‘ / ‘) # [法] 圣埃克苏佩里 / 马振聘 / 人民文学出版社 / 2003-8 / 22.00元
item[
‘name‘
]
= item[‘name‘]
item[
‘price‘
]
= info[-1]
item[
‘edition_year‘
]
= info[-2]
item[
‘publisher‘
]
= info[-3]
bookinfo
= dict(item) //将爬取的数据变为字典
self
.post.insert(bookinfo)
/
/
将爬取的数据插入mongodb数据库
return item |
3、在cmd中进入douban项目spiders目录,输入scrapy runspiders bookspider.py,运行编写的爬虫

至此大功告成!
以下是在mongodb中爬取的数据图
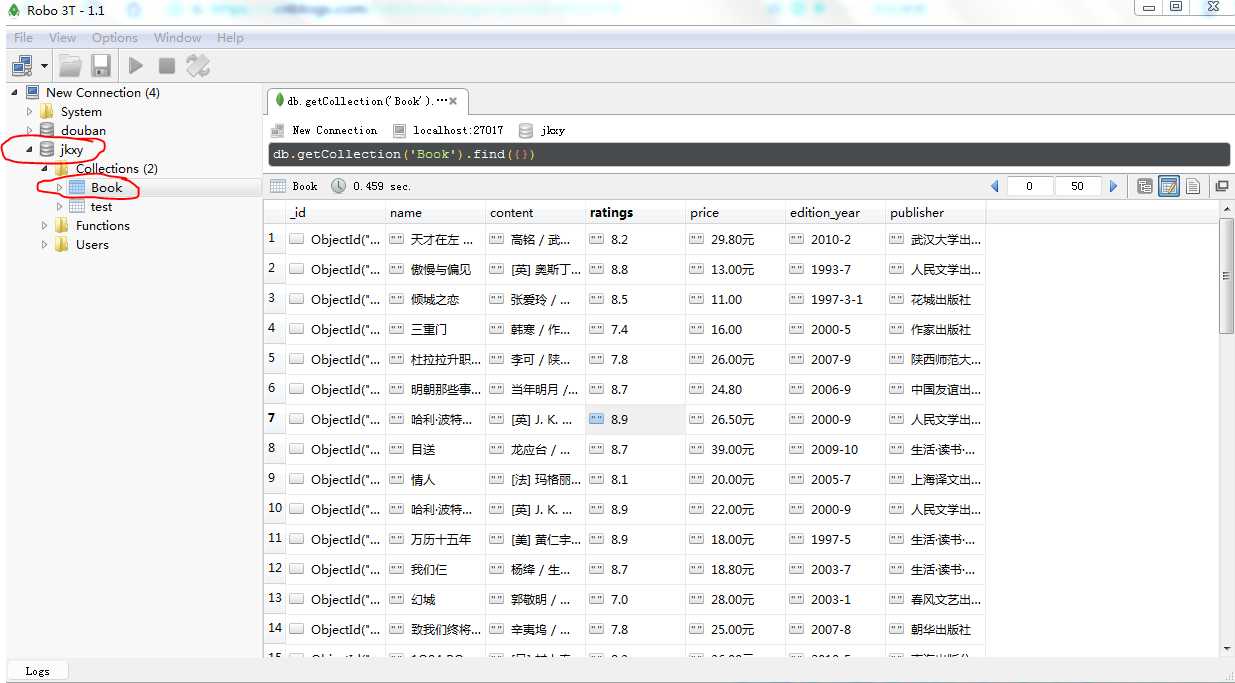
感想:
1、pycharm不能直接建立scrapy项目,需要在cmd中用命令scrapy startproject douban建立,
2、同样,在pycharm中如果不配置的话,直接点运行也没有用(一开始不知道怎么回事,点了运行,提示成功了,但是数据库里啥东西也没有,后来上网查了才发现要在cmd中用scrapy命令才行),但也有文章说在pycharm中设置一下就可以运行了,但我没试成功。
3、网上查到的在cmd下先进入项目目录,用命令scrapy crawl 项目名,我就在cmd目录下用scrapy crawl douban,但我试了多次都不行。
以为是不是crawl命令不对,就在cmd下输入scrapy -h查看一下都有啥命令,里面没有crawl命令,但是有一个runspiders 命令,就尝试进入spiders目录,直接运行bookspider.py,至此终于成功。
原文:https://www.cnblogs.com/menghome/p/8322328.html
内容总结
以上是互联网集市为您收集整理的python爬取豆瓣250存入mongodb全纪录全部内容,希望文章能够帮你解决python爬取豆瓣250存入mongodb全纪录所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。