首页 / HADOOP / Hadoop综合大作业
Hadoop综合大作业
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hadoop综合大作业,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2078字,纯文字阅读大概需要3分钟。
内容图文

一、用Hive对爬虫大作业产生的文本文件词频统计。
①启动hadoop:

②将文章(godfather.txt)放在了wc文件中:

③文件上传至hdfs
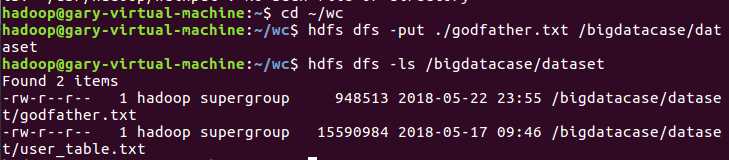
④启动hive
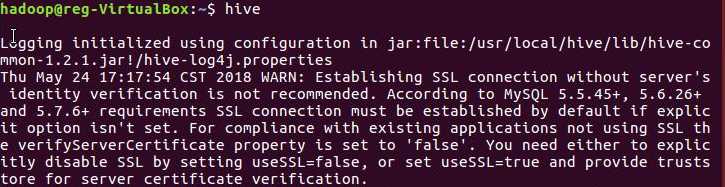
⑤导入文件内容到表novel

⑥查看统计结果
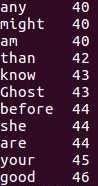
补交作业:
启动hadoop
cd /home/local/hadoop ./sbin/start-dfs.sh cd /home/local/hive/lib service mysql start start-all.sh
Hdfs上创建文件夹
hdfs dfs -mkdir demo hdfs dfs -ls /home/hadoop
上传文件至hdfs
hdfs dfs -put ./zzh.txt demo hdfs dfs -ls /home/hadoop/demo
启动Hive
创建原始文档表
create table docs(line string)
导入文件内容到表docs并查看
load data inpath ‘/user/hadoop/tese1/zzh.txt‘ overwrite into table docs select * from docs
用HQL进行词频统计,结果放在表word_count里
create table word_count as select word,count(1) as count from (select explode(split(line," ")) as word from docs) word group by word order by word;
补交作业二:
网络爬虫基础练习
0.可以新建一个用于练习的html文件,在浏览器中打开。
1.利用requests.get(url)获取网页页面的html文件
import requests
newsurl=‘http://news.gzcc.cn/html/xiaoyuanxinwen/‘
res = requests.get(newsurl) #返回response对象
res.encoding=‘utf-8‘
2.利用BeautifulSoup的HTML解析器,生成结构树
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,‘html.parser‘)
3.找出特定标签的html元素
soup.p #标签名,返回第一个
soup.head
soup.p.name #字符串
soup.p. attrs #字典,标签的所有属性
soup.p. contents # 列表,所有子标签
soup.p.text #字符串
soup.p.string
soup.select(‘li‘)
4.取得含有特定CSS属性的元素
soup.select(‘#p1Node‘)
soup.select(‘.news-list-title‘)
5.练习:
取出h1标签的文本
取出a标签的链接
取出所有li标签的所有内容
取出第2个li标签的a标签的第3个div标签的属性
取出一条新闻的标题、链接、发布时间、来源
import requests
from bs4 import BeautifulSoup
res = requests.get(‘http://www.people.com.cn/‘)
res.encoding = ‘UTF-8‘
soup = BeautifulSoup(res.text, ‘html.parser‘)
# 取出h1标签的文本
for h1 in soup.find_all(‘h1‘):
print(h1.text)
# 取出a标签的链接
for a in soup.find_all(‘a‘):
print(a.attrs.get(‘href‘))
# 取出所有li标签的所有内容
for li in soup.find_all(‘li‘):
print(li.contents)
# 取出第2个li标签的a标签的第3个div标签的属性
print(soup.find_all(‘li‘)[1].a.find_all(‘div‘)[2].attrs)
# 取出一条新闻的标题、链接、发布时间、来源
print(soup.select(‘div .news-list-title‘)[0].text)
print(soup.select(‘div .news-list-thumb‘)[0].parent.attrs.get(‘href‘))
print(soup.select(‘div .news-list-info > span‘)[0].text)
print(soup.select(‘div .news-list-info > span‘)[1].text)
原文:https://www.cnblogs.com/lk666/p/9090433.html
内容总结
以上是互联网集市为您收集整理的Hadoop综合大作业全部内容,希望文章能够帮你解决Hadoop综合大作业所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。