Hadoop,HBase集群环境搭建的问题集锦(三)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hadoop,HBase集群环境搭建的问题集锦(三),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3118字,纯文字阅读大概需要5分钟。
内容图文
")
16配置IK中文分词器。
1.下载最新的Ik中文分词器。
下载地址:http://ik-analyzer.googlecode.com/files/IK%20Analyzer%202012FF_hf1.zip
2.解压IK Analyzer 2012FF_hf1.zip,获得IK Analyzer 2012FF_hf1。将该目录下的IKAnalyzer.cfg.xml,stopword.dic放到之前安装TOMCAT_HOME/webapps/solr/WEB-INF/classes目录下(没有就创建classes文件夹。) IKAnalyzer2012FF_u1.jar放到之前安装的TOMCAT_HOME/webapps/solr/WEB-INF/lib目录下
3.修改/solr_home/collection1/conf/中的schema.xml,在type中增加如下内容:
<fieldType name="text_ik"class="solr.TextField">
<analyzer type="index" isMaxWordLength="false"class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true"class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
同时修改filed 使filed引用text_ik.这样才能使用IK分词器。 <field name="name" type="text_ik" indexed="true" stored="true"/>
17.schema.xml 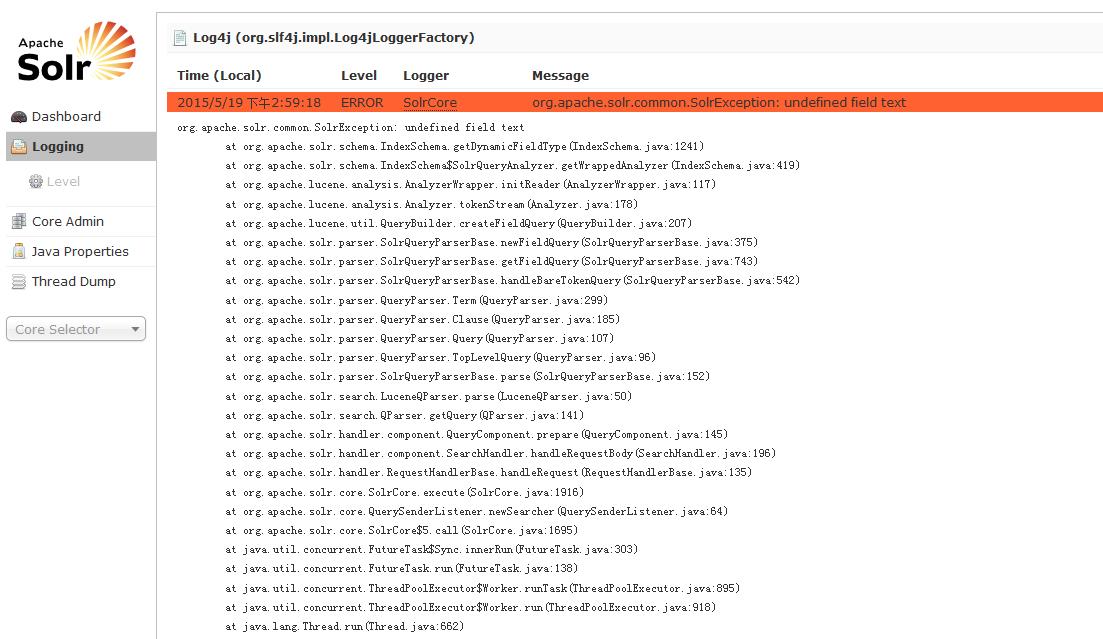
尝试解决办法: 在schema.xml中Fields中添加 <field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
结果, 
在type中添加 <fieldType name="text_general" positionIncrementGap="100">
<analyzer type="index">
<tokenizer />
<filter ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<filter />
</analyzer>
<analyzer type="query">
<tokenizer />
<filter ignoreCase="true" words="stopwords.txt" />
<filter synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter />
</analyzer>
</fieldType>
./shutdown.sh停止tomcat,再./startup.sh启动tomcat.结果见效, 不见了错误提示.不知会不会对后期的开发有影响.
18. 
随着问题17的解决而消失.
19.Solr配置MultiCore?
答:
参考资料:http://aixiangct.blog.163.com/blog/static/9152246120111128114423633/
Solr4.6的multicore配置:http://my.oschina.net/DavidTio/blog/185521
http://www.devnote.cn/article/37.html
- Solr基础–设置solr/home的三种方式?
答: 这是在开源中国的第一篇博文,希望将自己遇到的问题,搜藏的笔记跟大家共享,当然今天的内容也不是本人原创,仅仅作为一个开始。争取以后多多原创。
solr/home是solr实例化core核的依据和入口,是必不可少的配置。
在tomcat中有三种方式可以完成其配置。
1、在web.xml中设置<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>C:/example2/solr(path_to_solr_home_solr)</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
此中方式在部署时,不方便,需打包前给据部署环境修改。
2、通过tomcat的JNDI方式设置变量
在你安装tomcat的根目录下,找到或者新建路径:conf\Catalina\localhost;
根据你部署的项目名称,新建一个XML文件,如果包名叫solr,就叫solr.xml。
内容为:<Context docBase="E:/apache-tomcat6_1/webapps/solr(the_path_to solr.war)" debug="0" crossContext="true" >
<Environment name="solr/home" type="java.lang.String" value="C:/example2/solr(the_path_to_solr_home)" override="true" />
</Context>
3、tomcat启动的JAVA_OPTS参数设置方式
在你安装tomcat的根目录下,找到bin\catalina.bat 在JAVA_OPTS选项中添加,
如windows下,可在最前面加入一行set JAVA_OPTS -Dsolr.solr.home=C:/example2/solr
参考资料:
http://www.myexception.cn/open-source/745464.html
版权声明:本文为博主原创文章,未经博主允许不得转载。
原文:http://blog.csdn.net/computer30000/article/details/46758955
内容总结
以上是互联网集市为您收集整理的Hadoop,HBase集群环境搭建的问题集锦(三)全部内容,希望文章能够帮你解决Hadoop,HBase集群环境搭建的问题集锦(三)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。