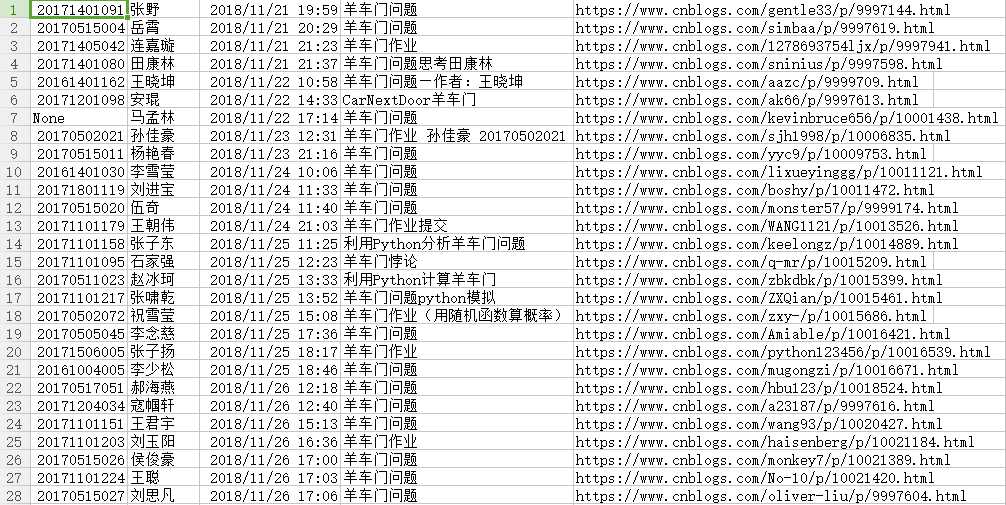
第一部分: 请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:hwlist.csv 。 文件内容范例如下形式: 学号,姓名,作业标题,作业提交时间,作业URL20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,http://www.cnblogs.com/sninius/p/12345678.html20194010102,李四,羊车门,2018-11-14 9:38:27.03,http://www.cnblogs.com/sninius/p/87654321.html *注1:如制作定期爬去作业爬虫...
人力资源部漂亮的小MM,跑来问我:老陈,数据分析和爬虫究竟是关系呀?说实在的,我真不想理她,因为我一直认为这个跟她的工作关系不大,可一想到她负责我负责部门的招聘工作,我只好勉为其难地跟她说:数据分析,吃里,爬虫,爬外,合在一起就是吃里爬外。大数据时代,要想进行数据分析,首先要有数据来源,单靠公司那几条毛毛雨(数据),分析个寂寞都不够,唯有通过学习爬虫,从外部(网站)爬取一些相关、有用的数据,才能让老板进...
爬虫简介requests模块数据解析三大方法seleniumscrapy框架 爬虫简介- 什么是爬虫: 爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程。 - 爬虫的分类:"""
- 通用爬虫:通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 简单来讲就是尽可能的;把互联网上的所有的网页下载下来,放到本地服务器里形成备...
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8922826一、网络爬虫的定义网络爬虫,即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。 网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为...
是什么?网络爬虫就是自动从互联网中定向或不定向地采集信息的一种程序
网络爬虫有很多种类型,常用的有通用网络爬虫、聚焦网络爬虫等。做什么?通用网络爬虫可以应用在搜索引擎中,聚焦网络爬虫可以从互联网中自动采集信息并代替我们筛选出相关的数据出来。网络爬虫经常应用在以下方面:1、 搜索引擎
2、 采集金融数据
3、 采集商品数据
4、 自动过滤广告
5、 采集竞争对手的客户数据
6、 采集行业相关数据,进行数据分析原文:ht...
一. 安装:1. 安装py3,使用Homebrew: ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" brew install python32. 安装请求库,Pip 是安装python包的工具,提供了安装包,列出已经安装的包,升级包以及卸载包的功能。pip3区别py3和py2。 pip3 install requests二、python创建简单的web方法1.使用eclipse创建工程1)Django 是用 Python 开发的一个免费开源的 Web 框架;D...
1.项目准备:网站地址:http://quanzhou.tianqi.com/ 2.创建编辑Scrapy爬虫:scrapy startproject weatherscrapy genspider HQUSpider quanzhou.tianqi.com项目文件结构如图: 3.修改Items.py: 4.修改Spider文件HQUSpider.py:(1)先使用命令:scrapy shell http://quanzhou.tianqi.com/ 测试和获取选择器: (2)试验选择器:打开chrome浏览器,查看网页源代码:(3)执行命令查看response结果: (4)编写HQUSpider.py文件:...
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据。我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕。所以这次我们的目标就是,爬取B站视频的评论数据,分析其为何会深受大家喜爱。首先去调研一下,B站评论数量最多的视频是哪一个。。。好在已经有大佬已经统计过了,我们来看一哈!?【B站大数据可视化】B站评论数最多的视频究竟是?来自 <https://www.bilibili.com/...
在Python中通过导入urllib2组件,来完成网页的抓取工作。在python3.x中被改为urllib.request。爬取具体的过程类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端, 然后读取服务器端的响应资源。 实现过程:1import urllib2
23 response=urllib2.urlopen(‘http://gs.ccnu.edu.cn/‘)
4 html=response.read()
5print html将返回的html信息打印出来,这和在网站上右键,查看源码看到的内容是一样的。浏览器通...
一、网络爬虫的定义网络爬虫,即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互...
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地。跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两个参数,其实爬取歌曲也是同样的道理,也需要传入这两个参数,只不过网易云歌曲的URL一般人找不到。不过也不要慌,有小编在,分分钟扫除您的烦恼。网易云歌曲一般会有一个外链,专门用于下载音乐音频的,以赵雷的歌曲《成都》为例,...
一、前言
本文是《Python开发实战案例之网络爬虫》的第四部分:7000本电子书下载网络爬虫-源码框架剖析。配套视频课程详见:51CTO学院。二、章节目录3.1 requests-html文件结构3.2 requests-html源码框架3.3 导入依赖库3.4 HTMLSession请求类3.5 HTMLResponse请求响应类3.6 HTML页面结构类三、正文3.1 requests-html 文件结构3.2 requests-html源码框架3.3 导入依赖库3.4 HTMLSession请求类3.5 HTMLResponse请求响应类3.6 HTML页面...
参考:http://www.cnblogs.com/xin-xin/p/4297852.html一、简介 爬虫即网络爬虫,如果将互联网比做成一张大网,那么蜘蛛就是爬虫。如果它遇到资源,将会抓取下来。二、过程 在我们浏览网页时,我们经常会看到一些形形色色的页面,其实这个过程就是我们输入url,经DNS解析成对应的ip找到对应的服务器主机,向服务器发出一个请求,服务器经过解析之后将html,js等发回浏览器显示。 其实爬虫和这个过程差不多,只不过我们在抓...
import urllib2源地址在python3.3里面,用urllib.request代替urllib2import urllib.request as urllib2
import cookielib源地址Python3中,import cookielib改成 import http.cookiejarimport http.cookiejar as cookielib
原文:https://www.cnblogs.com/bai2018/p/10963571.html
先来说一说HTTP的异常处理问题。当urlopen不能够处理一个response时,产生urlError。不过通常的Python APIs异常如ValueError,TypeError等也会同时产生。HTTPError是urlError的子类,通常在特定HTTP URLs中产生。 1.URLError通常,URLError在没有网络连接(没有路由到特定服务器),或者服务器不存在的情况下产生。<spanMicrosoft YaHei; font-size:18px">这种情况下,异常同样会带有"reason"属性,它是一个tuple(可以理解为不可变的...