第1天|12天搞定Python网络爬虫,吃里爬外?
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了第1天|12天搞定Python网络爬虫,吃里爬外?,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1618字,纯文字阅读大概需要3分钟。
内容图文

人力资源部漂亮的小MM,跑来问我:老陈,数据分析和爬虫究竟是关系呀?说实在的,我真不想理她,因为我一直认为这个跟她的工作关系不大,可一想到她负责我负责部门的招聘工作,我只好勉为其难地跟她说:数据分析,吃里,爬虫,爬外,合在一起就是吃里爬外。
大数据时代,要想进行数据分析,首先要有数据来源,单靠公司那几条毛毛雨(数据),分析个寂寞都不够,唯有通过学习爬虫,从外部(网站)爬取一些相关、有用的数据,才能让老板进行商业决策时的有据可依,而你,亦是老板。
一提到老板,漂亮的小MM,兴奋得不得了,马上大声问:你们IT界,最帅的是不是就是那个搞搜索引擎的李老板?
我尽管有点不服气,有点不开心,但我能怎么得,毕竟在网络爬虫方面,他(李老板)的技术比确实强。他懂得用爬虫技术,每天在海量互联网信息中进行爬取,爬取优质的信息并收录在他设定的数据库中。当用户在搜索引擎中,输入关键字时,引擎系统将对关键词进行数据分析处理,从收录的网页中找出相关网页,按照一定的排名规则排序并将结果展现给用户。
一想到排名赚到的money,李老板一分都不给我,我就跟人力MM说:好了,不跟你扯犊子了,我要跟我的老铁说网络爬虫的原理了,你个吃里爬外的家伙,见你的老板去吧。
1. 爬虫是什么
网络爬虫又称网络蜘蛛、网络蚂蚁、网络机器等,它按照我们制定的规则,在网络上爬取数据。爬到的结果中会有HTML代码、JSON数据、图片、音频或视频。程序员根据实际要求,对数据进行过滤,提取其中有用的,进行存储。
说白点,就是用Python编程语言模拟浏览器,访问指定网站,对其返回结果,按规则进行筛选并提取自己需要的数据,存放起来使用,以供使用。
看过我《第10天 | 12天搞定Python,文件操作 》和《第11天 | 12天搞定Python,数据库操作》的老铁,应该知道,数据常存在文件或数据库中。
2. 爬取流程
用户通过浏览器访问网络数据的方式:打开浏览器->输入网址->浏览器提交请求->下载网页代码->解析成页面。
爬虫编程,指定网址,模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于文件或数据库中。
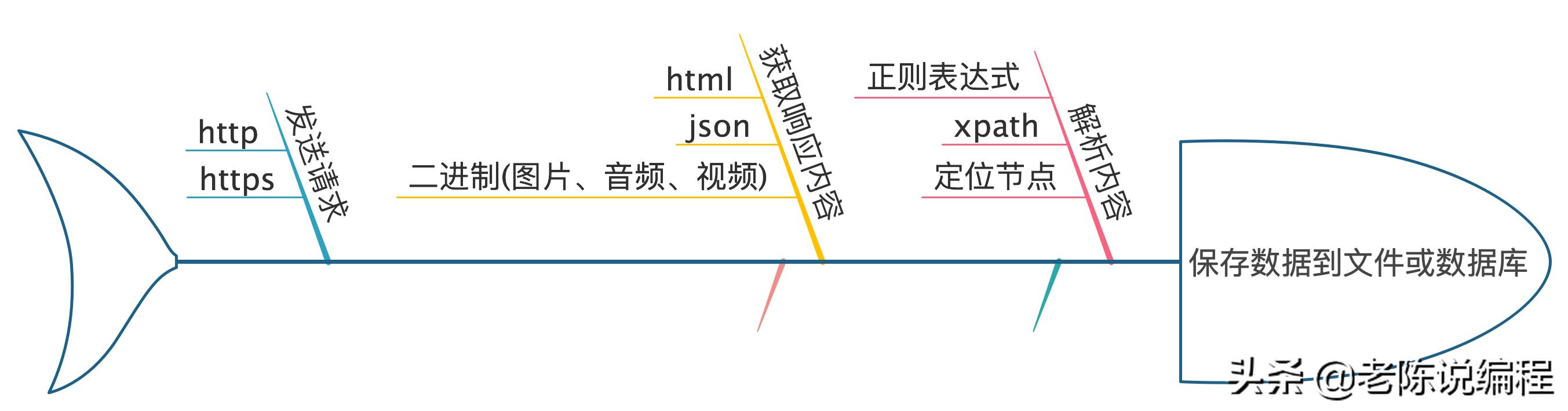
爬虫编程,推荐用Python,是因为Python爬虫库简单易用,在Python内置环境中的,就可以满足大多数功能。它可以:
(1) 用http库向目标站点发起请求,即发送一个Request(包含请求头和请求体等);
(2) 对服务器返回的Response,用内置的库(html、json、正则表达式)就进行解析
(3) 将所需数据存储到文件或数据库当中。
如果Python内置的库不够用的话,可以用pip install 库名,快速下载第3方库并进行使用。
3. 爬点定位
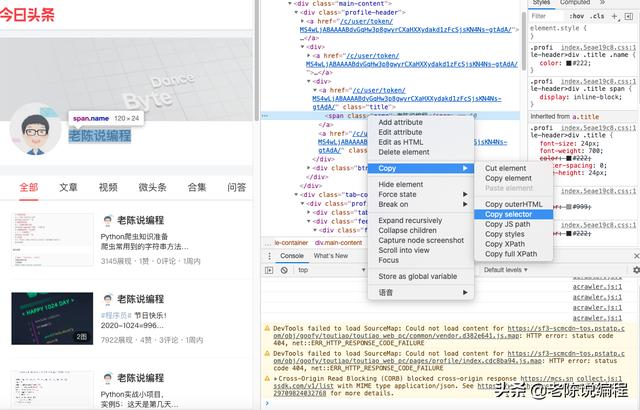
在编写爬虫代码的过程中,经常需要指定爬取的节点或路径。如果我告诉你,Chrome浏览器,就可以快速获取节点或路径的话,你会不会马上看一下电脑是否安装了?
会的话,那就对了,不会的,赶紧去安装吧。
在页面中,按下键盘F2键,可显示源代码。鼠标选中你要获取的节点,右键【检查】就可定位到代码中,右键代码,选择【Copy】-【Copy Selector 】或【Copy XPath】便可复制节点或路径的内容。
好了,有关爬虫原理的内容,老陈讲完了,如果觉得对你有所帮助,希望老铁能转发点赞,让更多的人看到这篇文章。你的转发和点赞,就是对老陈继续创作和分享最大的鼓励。
一个当了10年技术总监的老家伙,分享多年的编程经验。想学编程的朋友,可关注今日头条:老陈说编程。我将分享Python,前端(小程序)和App方面的干货。关注我,没错的。
原文:https://www.cnblogs.com/halfcode/p/13877795.html
内容总结
以上是互联网集市为您收集整理的第1天|12天搞定Python网络爬虫,吃里爬外?全部内容,希望文章能够帮你解决第1天|12天搞定Python网络爬虫,吃里爬外?所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。