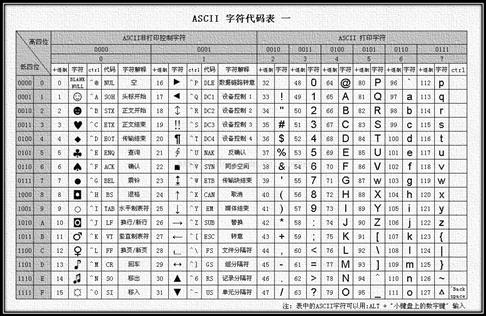
如果想理解进制与字符编码由来可参考python编程基础之字符编码 二进制与字符编码
计算机只认识0和1。ASCII表来表示符号和数字。
下面对应的时ASCII字符参照表其中,‘A‘ 使用了8个位(bit)才能表示出来,在计算机他们叫一个字节(byte)0 1 0 0 0 0 0 1
1024 byte = 1 kB ; 1024 kB = 1 MB ;1024 MB = 1 GB ; 1024 GB = 1 TB.二进制0,1 → ASCII → GB2312 → GB18...
任何一个程序想要运行,必须先有硬盘加载到内存,然后由cpu去内存取只执行。运行着的应用程序的数据,必须在内存运行。python运行文件的三步,首先把python文件解释器读取到内存上,然后应用程序代码文本文件读取到内存上,最后python解释器对程序代码进行编译成计算机识别的代码。字符编码 字符编码和文本文件有关。文字,字母,数字符号等都属于字符。常见的文本文件,记事本,word文件等。但是图片和视频不属于文本文件。 ...
一、字符编码(1)计算机基础知识 (2)python 解释器执行py文件的原理 <1>python 解释器启动 <2>python解释器相当于一个文本编辑器,打开txt.py文件,从硬盘把txt.py文件内容读到内存中 <3>python解释器解释刚刚加载到内存中的txt.py的代码(在该阶段及执行时,才会识别python的语法,执行文件内存代码,执行到name="egon",会开辟内存空间存放字符串"egon") (3)python解释器与文本编辑的异同 相同点:python解...
字符编码字符编码:字符----编码(字符编码表)---->二进制目前内存中使用的统一是unicode,编码和解码对应了相应的字符集保证不乱码的关键:1.字符当初以什么编码存放的, 就应该以什么编码解码。当存储的时候字符编码不对的时候,内存会存放错误的二进制,那么取出来的时候,无论以什么办法取,都是乱码2.在python2中解释器默认使用的编码是ASCII码,python3默认使用的是UTF-8在python文件头上插入:
#coding:utf-8
修改python解释...
出现如上错误的原因:Python默认是以ASCII作为编码方式的,如果在自己的Python源码中包含了中文(或者其他非英语系的语言),此时即使你把自己编写的Python源文件以UTF-8格式保存了,但实际上,这依然是不行的。解决办法很简单,只要在文件开头加入下面代码就行了(一定是要在文件的最开始位置):# -*- coding: UTF-8 -*- 或#coding=utf-8原文:http://www.cnblogs.com/xiaomeikugua/p/3594271.html
字符编码python解释器在加载.py文件中的代码时,会对内容进行编码(默认ASCII)二进制举例:古时候烽火台,点火和不点火只有两种状态,传递信息太少。 约定点火数1,代表1-100 点火数2,代表101-1000 点火数3,代表1001-5000 点火数4,代表5001-1000虽然有进步,但还不够精确如果引入二进制,可以精确表示任意数字符编码二进制和字母的转换ASCII(American Standard Code for Information Interchange,美国标准信息交换代...
首先简单说一下字符编码的问题。平常遇到比较多的就是ASCII码(全称:美国信息交换标准码)。ASCII码使用一个字节(8位)来表示一些常见的数字、英文字母以及一些控制字符。英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如中文汉字就无法用ASCII来表示和编码。为了对世界上的各种语言符号进行统一的编码,于是发明了Unicode。Unicode将世界上所有的文字符号都纳入其中。每一个符号都给予一个独一无二的...
一、计算机编码简介编码是指示将信息从表示方法A转变为表示方法B,解码是编码的逆过程,信息通过编解码后,信息内容不变。针对计算机而言,编码就是将信息转为计算机可以识别的二进制0、1数字,而由于各国表示信息的方式不一致(如中文:汽车;美国: bus),因此各国产生了自己的编码规则,比较常用的是ASCII码:早期计算机编码,在内存占用1个字节(8bit),因此最多能表示256个符号,表示为英文字母和特殊符号。GBK编码:随着计算...
一、文本编辑器存取文件的原理(nodepad++,pycharm,word)1、打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失2、要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。3、在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。二、python解释器执行py文件的原理 ,例如python test.py复制代码#第一阶段:pyt...
一 什么是编码?基本概念很简单。首先,我们从一段信息即消息说起,消息以人类可以理解、易懂的表示存在。我打算将这种表示称为“明文”(plain text)。对于说英语的人,纸张上打印的或屏幕上显示的英文单词都算作明文。其次,我们需要能将明文表示的消息转成另外某种表示,我们还需要能将编码文本转回成明文。从明文到编码文本的转换称为“编码”,从编码文本又转回成明文则为“解码”。编码问题是个大问题,如果不彻底解决,它就...
一、文字转二进制1、把#Alex 按照ASCII表转成二进制形式2、计算机如何分清哪段代表#,哪段是代码A二、计算机容量单位由于字符串长的长,短的短,难以分清每个字符的起止位置,既然ASCII一共是255个字符,那么最长的也不过是11111111八位,不如把所有二进制转换成8位的,不足的用0来代替。每一位0或者1所占的空间单位为bit(比特),这是计算机中最小的表示单位三、字符编码为了解决每个国家不同编码间不互通的问题,ISO标准组织出马...
由于每个国家都有自己的字符,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在局限性,即:仅涵盖本国字符,无其他国家字符的对应关系。应运而生出现了万国码,他涵盖了全球所有的文字和二进制的对应关系。Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中... 参考博文:http://www.cnblogs.com/brave1/p/8928068.html原文:http://blog.51cto.com/sdsca/2108201
字符编码的转换编码问题一直是个难以理解的问题,莫名其妙转换来转换去的,程序的结果就能正确输出,最后还是留出一点时间开始理解这个棘手的问题。python有两种字符串类型,str、unicode,这两者都是basestring的子类str是字节串,而unicode则是真正意义上的字符串str可以通过decode()函数转换成unicode;unicode可以通过encode()函数转换成str。unicode是支持所有文字的统一编码,但一般只用作文字的内部表示,文件、网页(也是文...
下面小编就为大家带来一篇老生常谈Python基础之字符编码。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧前言字符编码非常容易出问题,我们要牢记几句话:1.用什么编码保存的,就要用什么编码打开2.程序的执行,是先将文件读入内存中3.unicode是父编码,只能encode解码成其他编码格式utf-8,GBK这些是子8编码,只能decode编码成Unicode一、什么是字符编码我们知道,计算机只能识别二进制,我们平时...
下面小编就为大家带来一篇Python字符编码与函数的基本使用方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧一、Python2中的字符存在的解码编码问题如果是现在正在用Python2的人应该都知道存在字符编码问题,就举一个最简单的例子吧:Python2是无法在命令行直接打印中文的,当然他也是不会报错的,顶多是一堆你看不懂的乱码。如果想在直接显示中文,我们是可以在Python2文件头部申明字符编码的...