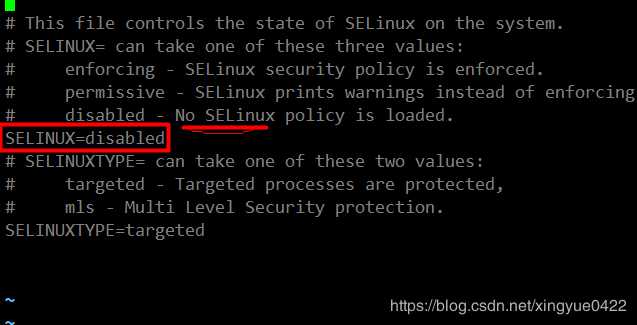
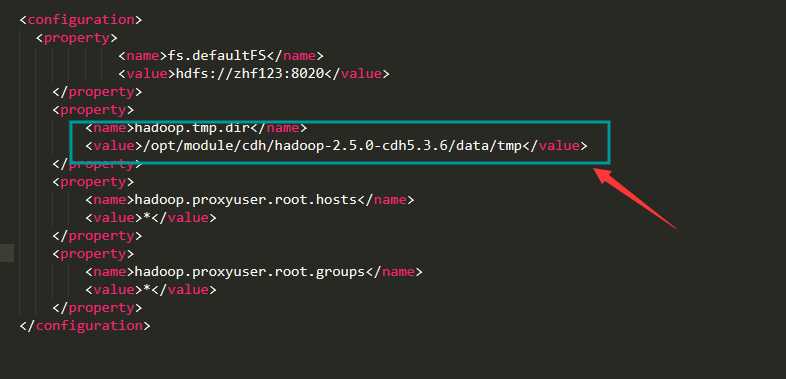
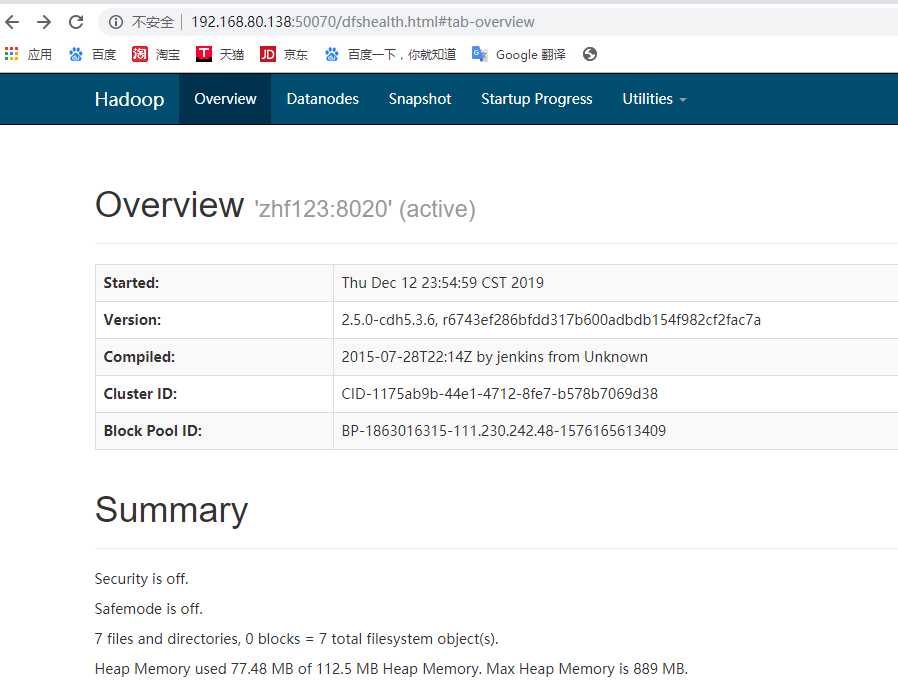
前文:如果格式化完之后,使用jps命令发现进程都已经启动,但是使用web页面打不开hadoop的网页,可能原因就是防火墙没关或者是哪个配置过程配错了。1.关闭防火墙一般最好是关闭防火墙比较关闭。 systemctl stop firewalld.service 关闭防火墙; 禁止自动启动就用 systemctl disable firewalld.service . 就可以了。 还有个防火墙是selinux: 要设置为 vi /etc/selinux.config 关闭再重新访问网页还是不行,需要检查...
InputSplit 有三个方法1.getLengh(),为了获取字节长度2.getLocations(),获取地址,在哪个节点3.该方法返回空,返回类型是可支持在内存中存储,或者磁盘存储。可以看出未来mapreduce有希望支持内存存储数据。@Evolving public SplitLocationInfo[] getLocationInfo() throws IOException { return null; } --------------------------------分割线--------------------------------FileSplit1.属性如下:private Path file; p...
引言 引用《Hadoop权威指南》原文如下: Hadoop works better with a small number of large files than a large number of small files. One reason for this is that FileInputFormat generates splits in such a way that each split is all or part of a single file. If the file is very small (“small” means significantly smaller than an HDFS block) and there are a lot of them, each map task will process very l...
在Hadoop中,常用的TextInputFormat是以换行符作为Record分隔符的。 在实际应用中,我们经常会出现一条Record中包含多行的情况,例如: doc..../doc 此时,需要拓展TextInputFormat以完成这个功能。 先来看一下原始实现: public class TextInputFormat exte在Hadoop中,常用的TextInputFormat是以换行符作为Record分隔符的。
在实际应用中,我们经常会出现一条Record中包含多行的情况,例如:....
此时,需要拓展TextInputFormat以...
在http://blog.csdn.net/sunflower_cao/article/details/28266939 写过可以通过继承 Writable, DBWritable实现在reduce过程中讲结果写入到mysql数据库里边,但是一直有一个问题就是只能实现insert 没法去更新已经存在的数据,这就导致不同的mapreduce程序获得的数据只能插入到不同的数据库中 在使用的时候需要建立view或者使用复杂的sql语句去查询,今天调查了下,发现可以通过重写DBOutputFormat 上代码:TblsWritable.javaimpo...
1、注意,需要声明为静态内部类,否则会报java.lang.NoSuchMethodException...<init>的错误public static class MySqlWritable implements Writable, DBWritable {2、如果输出目录存在,需要先删除3、由于需要从mysql数据取值,则需要有mysql数据库驱动包,hadoop classpath查看hadoop类加载路径,将驱动包拷贝到其中一个目录下即可;4、解决mysql"Access denied for user‘root‘@‘IP地址‘"问题a、登录mysqlmysql -u username -...
create table student(id INTEGER NOT NULL PRIMARY KEY,name VARCHAR(32) NOT NULL); (3):插入数据
[java] view plain copy
insert into student values(1,"lavimer");
(4)编写MapReduce程序,我这里使用的版本是hadoop1.2.1,相关知识点都写在注释中了,如下:
[java] view plain copy
/**
* 使用DBInputFormat和DBOutputFormat
* 要把数据库的jdbc驱动放到各个TaskTracker节点的lib目录下
* 重启集群
* @...
create table user(id INTEGER NOT NULL PRIMARY KEY,name VARCHAR(32) NOT NULL); 数据准备:在数据文件上传到HDFS中,数据如下图:
我这里使用的hadoop版本为hadoop1.X,具体的代码和相关的知识点我们写在注释里了,代码如下:
[java] view plain copy
public class MyDBOutputFormat {
// 定义输出路径
private static final String INPUT_PATH = "hdfs://liaozhongmin:9000/user";
pu...
问题描述:
hadoop namenode -format hdfs重新格式化之后,重新启动后,一直无法启动。
(有问题就查,不要一直格式化,干哈呢,万一脑裂了,咋弄,虽然有办法恢复)
在datanode上的报错日志如下,可以看出id不一致2021-01-09 16:34:09,920 ERROR namenode.NameNode (NameNode.java:main(1759)) - Failed to start namenode. org.apache.hadoop.hdfs.server.common.IncorrectVersionException: Unexpected version of storage dire...
缘由:搭建impala配置hdfs-site.xml后需要 ,重新启动整个集群(确保集群使用状况);重启后出现master无法启动java.io.IOException: NameNode is not formatted.at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:212)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1061)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNames...
我有一个hbase表,其密钥是一个带有一个字节随机前缀的时间戳,用于分发密钥,因此扫描不会热点.我正在尝试扩展TableInputFormat,以便我可以在带有范围的表上运行单个MapReduce,为所有256个可能的前缀添加前缀,以便扫描具有指定时间戳范围的所有范围.我的解决方案不起作用,因为它似乎总是扫描最后一个前缀(127)256次.必须在所有扫描中共享某些内容.
我的代码如下.有任何想法吗?public class PrefixedTableInputFormat extends TableI...
00:53:47,977 WARN namenode.NameNode: Encountered exception during format:
java.io.IOException: Cannot remove current directory: /home/hadoop/tmp/dfs/name/currentat org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:433)at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:579)at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNSt...
文章目录
一、切片与MapTask并行度决定机制二、Job提交流程三、切片执行流程解析四、FileInputFormat切片机制五、TextInputFormat六、CombineTextInputFormat切片机制一、切片与MapTask并行度决定机制
MapTask的并行度决定Map阶段的任务处理并发读,进而影响到整个Job的处理速度,引入两个概念:
数据块:Block是HDFS物理上把数据分成一块一块,数据块是HDFS存储数据单位数据切片: 只是在逻辑上对输入进行分片,并不会在磁盘上将其...