Hadoop 格式化format namenode 后,ambari端启动datanode节点无法正常启动处理
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hadoop 格式化format namenode 后,ambari端启动datanode节点无法正常启动处理,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2834字,纯文字阅读大概需要5分钟。
内容图文

问题描述:
hadoop namenode -format hdfs重新格式化之后,重新启动后,一直无法启动。
(有问题就查,不要一直格式化,干哈呢,万一脑裂了,咋弄,虽然有办法恢复)
在datanode上的报错日志如下,可以看出id不一致
| 2021-01-09 16:34:09,920 ERROR namenode.NameNode (NameNode.java:main(1759)) - Failed to start namenode. org.apache.hadoop.hdfs.server.common.IncorrectVersionException: Unexpected version of storage directory /data01/hadoop/hdfs/namenode. Reported: -64. Expecting = -63. at org.apache.hadoop.hdfs.server.common.storageinfo.setlayoutversion(storageinfo.java:178) at org.apache.hadoop.hdfs.server.common.storageinfo.setfieldsfromproperties(storageinfo.java:131) at org.apache.hadoop.hdfs.server.namenode.NNStorage.setFieldsFromProperties(NNStorage.java:626) at org.apache.hadoop.hdfs.server.namenode.NNStorage.readProperties(NNStorage.java:655) at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:339) at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:215) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1015) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:690) at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:688) at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:752) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:992) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:976)
........................................ ERROR datanode.DataNode (BPServiceActor.java:run(752)) - Initialization failed for Block pool <registering> (Datanode Uuid 0850e5b3-d7bd-422b-963a-5517039ceb99) service to x.x.x.x/x.x.x.x:8020. Exiting. org.apache.hadoop.util.DiskChecker$DiskErrorException: Too many failed volumes - current valid volumes: 2 volumes configured: 14 volumes failed: 12 volume failures tolerated: 0 at org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.FsDatasetImpl.<init>(FsDatasetImpl.java:293) |
原因分析:
因未对数据盘进行清除,导致直接格式后,datanode的 节点的clusterID不一致。
解决方案:
(1)首先我们,停止全部的服务
(2) 删除namenode和所有datanode节点上文件夹:分别删除core-site.xml和hdfs-site.xml的hadoop.tmp.dir、dfs.name.dir、dfs.datanode.dir的对应目录,使用ambari的用户,可以直接在config页面直接搜索
core-site.xml
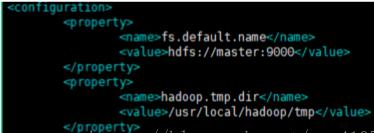
hdfs-site.xml
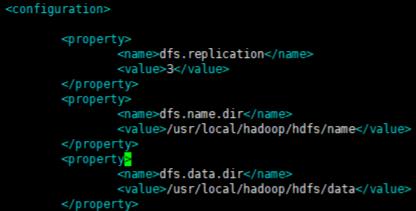
这是我的集群对应的name和data目录
rm -rf /hadoop/hdfs/namenode
rm -rf /data01/hadoop/hdfs/namenode
rm -rf /var/hadoop/hdfs/namenode
rm -rf /hadoop/hdfs/data
rm -rf /data01/hadoop/hdfs/data
rm -rf /var/hadoop/hdfs/data
3、确保已删除全部name和data目录后,重新格式
hadoop namenode -format (在你的namenode上执行)
4、启动服务,查看是否服务正常运行,之前删除的data和name的目录是否都重建了。
内容总结
以上是互联网集市为您收集整理的Hadoop 格式化format namenode 后,ambari端启动datanode节点无法正常启动处理全部内容,希望文章能够帮你解决Hadoop 格式化format namenode 后,ambari端启动datanode节点无法正常启动处理所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。