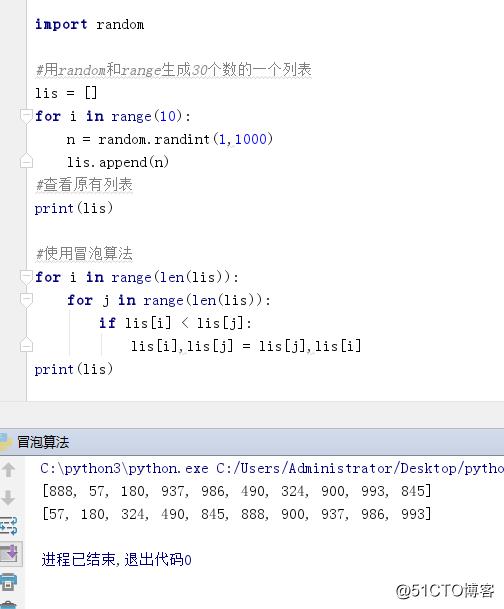
import random#用random和range生成30个数的一个列表
lis = []
for i in range(10):n = random.randint(1,1000)lis.append(n)
#查看原有列表
print(lis)#使用冒泡算法
for i in range(len(lis)):for j in range(len(lis)):if lis[i] < lis[j]:lis[i],lis[j] = lis[j],lis[i]
print(lis)
原文:http://blog.51cto.com/853056088/2171438
前言初识递归函数与算法,递归其实就是在函数内部调用自己,算法就是一个计算的方法,我们简单了解一下递归实现的二分查找算法。一、初识递归1、简单递归函数1.如果是这样子,那么就停不下来,但python为了杜绝无限调用,就做了限制。2.限制默认为:998,如下面函数所示。3.递归不合适解决次数很多,因为占内存,但递归能让代码更简单RecursionError:递归错误,是超出了递归的最大深度。# 1、简单递归函数:
n = 0
def func():glob...
算法如果用通俗易懂的语言来说,算法就是“把解决问题的步骤无一遗漏地用文字或图表示出来”。要是把这里的“用文字或图表示”替换为“用编程语言表达”,算法就变成了程序。而且请诸位注意这样一个条件,那就是“步骤必须是明确的并且步骤数必须是有限的”。
典型算法计算不能自发地思考。因此计算机所执行的由程序表示的算法必须是由机械的步骤所构成。所谓“机械的步骤”,就是不用动任何脑筋,只要按照这个步骤做就一定能完成的...
1.冒泡算法:N个数从左到右,相邻两两比较,按照顺序排列。
#冒泡排序,升序
a = [4,5,1,6,3,7,1,10]
for i in range(len(a)):for j in range(i+1,len(a)):if a[i] > a[j]:a[i], a[j] = a[j], a[i]
print(a)[1, 1, 3, 4, 5, 6, 7, 10]#冒泡排序,降序
a = [4,5,1,6,3,7,1,10]
for i in range(len(a)):for j in range(i+1,len(a)):if a[i] < a[j]:a[i], a[j] = a[j], a[i]
print(a)[10, 7, 6, 5, 4, 3, 1, 1]原文:http://blog.51ct...
摘要:本文主要介绍的是python实现归并排序算法,本文首先会介绍归并排序的原理,并以一张思维导图来加深读者对该算法过程的理解,紧接着进行代码的实现。最后介绍该算法的时间复杂度。一.原理:1.将一个序列从中间位置分成两个序列;2.在将这两个子序列按照第一步继续二分下去;3.直到所有子序列的长度都为1,也就是不可以再二分截止。这时候再两两合并成一个有序序列即可。 下面的这张图片可以很清晰的解释该原理: 二.代码如下...
一、 环境:Python 3.7.4Pycharm Community 2019.3二、 问题: 对六个样本点[1, 5], [2, 4], [4, 1], [5, 0], [7, 6], [6, 7]进行K-means聚类。三、 理论推导 此处依照我个人理解所写,错误之处欢迎指出 K-means核心操作为:聚类中心选取—分类—调整聚类中心—再次分类并调整聚类中心直到调整幅度小于阈值或程序运行轮数大于阈值选取聚类中心: 聚类中心的选取可以选择随机选取、人工选取。K-means+...
比较排序:各元素的次序依赖于它们之间的比较{插入排序O(n**2) 归并排序O(nlgn) 堆排序O(nlgn)快速排序O(n**2)平均O(nlgn)}本章主要介绍几个线性时间排序:(运算排序非比较排序)计数排序O(k+n)基数排序O()第一节:用决策树分析比较排序的下界决策树:倒数第二层满,第一层可能满的二叉树,它用来表示所有元素的比较操作{于此来分析下界},忽略控制,移动操作1:2 #A[1]和A[2]比 <= 走左边 >走右边<3,1,2> 最后的结果 下标对应排序...
摘要:Classification And Regression Tree(CART)是一种很重要的机器学习算法,既可以用于创建分类树(Classification Tree),也可以用于创建回归树(Regression Tree),本文介绍了CART用于离散标签分类决策和连续特征回归时的原理。决策树创建过程分析了信息混乱度度量Gini指数、连续和离散特征的特殊处理、连续和离散特征共存时函数的特殊处理和后剪枝;用于回归时则介绍了回归树和模型树的原理、适用场景和创建过程。个人认为...
#快排 1def q_sort(l):2 left = 03 right = len(l)-14return q(l,left,right)5 6def quick_sort(l,left,right):7if left >= right:8return l9 low = left
10 high = right
11while right>left:
12while right>left and l[right] >= l[left]:
13 right -=1
14 l[right],l[left] = l[left],l[right]
15while right>left and l[right] >= l[left]:
16 left += 1
17 l[right...
本篇主要实现九(八)大排序算法,分别是冒泡排序,插入排序,选择排序,希尔排序,归并排序,快速排序,堆排序,计数排序。希望大家回顾知识的时候也能从我的这篇文章得到帮助。原文:https://www.cnblogs.com/huang-yc/p/9774287.html概述十种常见排序算法可以分为两大类:非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。线性时间非比较类排序:不通过比...
国密商用算法是指国密SM系列算法,包括基于椭圆曲线的非对称公钥密码SM2算法、密码杂凑SM3算法、分组密码SM4算法,还有只以IP核形式提供的非公开算法流程的对称密码SM1算法等。第1节 SM2非对称密码算法原理国密SM2算法是商用的ECC椭圆曲线公钥密码算法,其具有公钥加密、密钥交换以及数字签名的功能。椭圆曲线参数并没有给出推荐的曲线,曲线参数的产生需要利用一定的算法产生。但在实际使用中,国密局推荐使用素数域256 位椭圆曲线...
引言定义:算法就是按照一定步骤解决问题的办法属性:正确:就是可以正确的求解问题快速:就是时间复杂度要尽量小有穷性:要在有限个步骤解决问题渐进分析法为什么可以做到与算法运行硬件环境无关?算法分析时往往假设输入规模n足够大,甚至趋近于无穷大。这样的假设,意味着我们关注的是算法运算时间的增长率,也就是,随着输入规模n的增长,T(n)的增长率。当n趋向于无穷大时,决定T(n)增长率的便是T(n)中的高次项,从而可以忽略T(n)中的...
python内置模块之(os,sys,hashlib,re)os模块 1 os.path.dirname() # 获取文件的上一层目录名,其实就是os.path.split(path)的第一个元素 2 os.path.abspath() # 获取文件的绝对路径,包括文件名 3os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径4 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd5 os.curdir 返回当前目录: (‘.‘)6 os.pardir ...
算法定义时间复杂度空间复杂度常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间...
一、聚类的概念聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结构信息,对数据进行分簇(分类)。聚类算法的目标是,簇内相似度高,簇间相似度低二、基本的聚类分析算法 1. K均值(K-Means): 基于原型的、划分的距离技术,它试图发现用户指定个数(K)的簇。 2. 凝聚的层次距...