一、Hadoop计数器1.1 什么是Hadoop计数器 Haoop是处理大数据的,不适合处理小数据,有些大数据问题是小数据程序是处理不了的,他是一个高延迟的任务,有时处理一个大数据需要花费好几个小时这都是正常的。下面我们说一下Hadoop计数器,Hadoop计数器就相当于我们的日志,而日志可以让我们查看程序运行时的很多状态,而计数器也有这方面的作用。那么就研究一下Hadoop自身的计数器。计数器的程序如代码1.1所示,下面代码还是以内容...
修改陆喜恒. Hadoop实战(第2版)5.3排序的代码时遇到IO异常。环境:Mac OS X 10.9.5, IntelliJ IDEA 13.1.5, Hadoop 1.2.1异常具体信息如下 1 14/10/06 03:08:51 INFO mapred.JobClient: Task Id : attempt_201410021756_0043_m_000000_0, Status : FAILED2 java.io.IOException: Type mismatch in value from map: expected org.apache.hadoop.io.IntWritable, recieved org.apache.hadoop.io.Text3 at org.apache.hadoop.ma...
hadooop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map 的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map的个数,还取决于其他的因素。 为了方便介绍,先来看几个名词:block_size : hdfs的文件块大小,默认为64M,可以通过参数dfs.block.size设置total_size : 输入文件整体的大小input_file_num : 输入文件的个数(1)默...
使用MultipleInputs.addInputPath 对多个路径输入现在假设有三个目录,并使用了三个mapper去处理,经过map处理后,输出的结果会根据key 进行join,如果使用TextPair,会根据第一个字段jion,第二个字段排序然后在作为reduce的输入,进行计算原文:http://blog.csdn.net/smile0198/article/details/34534241
这样的操作在map端或者reduce端均可。下面以一个实际业务场景中的例子来简要说明。问题简要描述:假如reduce输入的key是Text(String),value是BytesWritable(byte[]),不同key的种类为100万个,value的大小平均为30k左右,每个key大概对应 100个value,要求对每一个key建立两个文件,一个用来不断添加value中的二进制数据,一个用来记录各个value在文件中的位置索引。(大量的小文件会影响HDFS的性能,所以最好对这些小文件进行拼接)当...
有这么个需求:一个目录下的数据只能由一个map来处理。如果多个map处理了同一个目录下的数据会导致数据错乱。 刚开始google了下,以为网上都有现成的InputFormat,找到的答案类似我之前写的 mapreduce job让一个文件只由一个map来处理。 或者是把目录写在文有这么个需求:一个目录下的数据只能由一个map来处理。如果多个map处理了同一个目录下的数据会导致数据错乱。
刚开始google了下,以为网上都有现成的InputFormat,找到的答案...
Hadoop中连接(join)操作很常见,Hadoop“连接”的概念本身,和SQL的“连接”是一致的。SQL的连接,在维基百科中已经说得非常清楚。比如dataset A是关于用户个人信息的,key是用户id,value是用户姓名等等个人信息;dataset B是关于用户交易记录的,key是用
Hadoop中连接(join)操作很常见,Hadoop“连接”的概念本身,和SQL的“连接”是一致的。SQL的连接,在维基百科中已经说得非常清楚。比如dataset A是关于用户个人信息的,k...
转载自:如何在hadoop中控制map的个数hadoop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是每次都有效的。原因是mapred.map.tasks只是一个hadoop的参考数值,最终map的个数,还转载自:如何在hadoop中控制map的个数
hadoop提供了一个设置map个数的参数mapred.map.tasks,我们可以通过这个参数来控制map的个数。但是通过这种方式设置map的个数,并不是...
本文演示如何在Eclipse中开发一个Map/Reduce项目: 1、环境说明 Hadoop2.2.0 Eclipse?Juno SR2 Hadoop2.x-eclipse-plugin 插件的编译安装配置的过程参考:http://www.micmiu.com/bigdata/hadoop/hadoop2-x-eclipse-plugin-build-install/ 2、新建MR工程 依次本文演示如何在Eclipse中开发一个Map/Reduce项目:
1、环境说明
Hadoop2.2.0Eclipse?Juno SR2Hadoop2.x-eclipse-plugin 插件的编译安装配置的过程参考:http://www.micmiu.c...
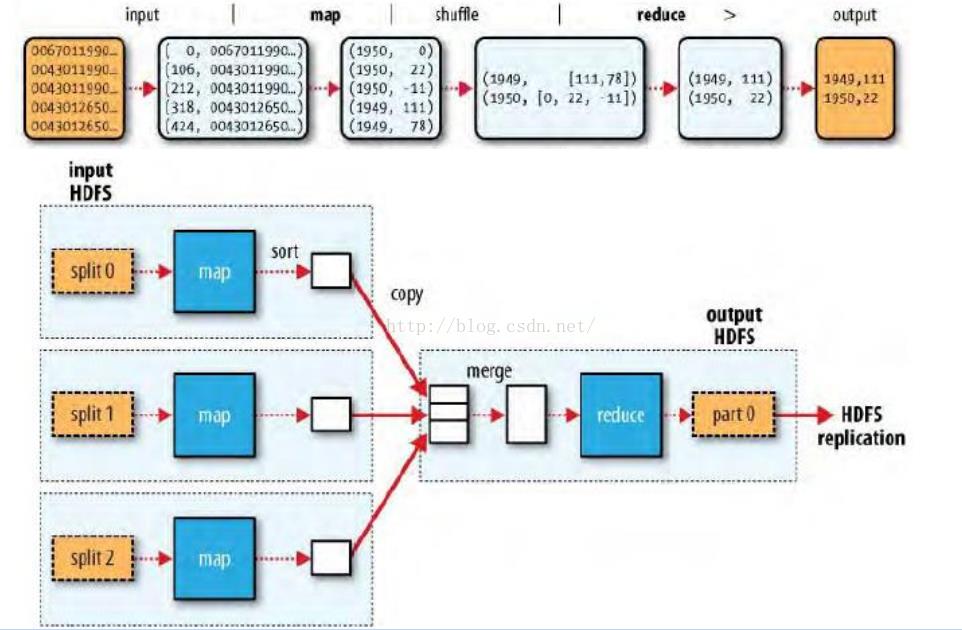
纯干活:通过WourdCount程序示例:详细讲解MapReduce之BlockSplitShuffleMapReduce的区别及数据处理流程。 Shuffle过程是MapReduce的核心,集中了MR过程最关键的部分。要想了解MR,Shuffle是必须要理解的。了解Shuffle的过程,更有利于我们在对MapReduce job纯干活:通过WourdCount程序示例:详细讲解MapReduce之Block+Split+Shuffle+Map+Reduce的区别及数据处理流程。Shuffle过程是MapReduce的核心,集中了MR过程最关键的部分。要...
如题回复内容:
hadoop map阶段所做的事 类比于 python maphadoop reduce阶段所做的事 类比于 python groupby但只是类比,hadoop map阶段和reduce阶段有更具体细节的不同步骤,两者牛头无法对上马嘴。MapReduce是一种Google第一次提出的,在并行集群里对大数据进行计算的的一种编程模型。它包括map与reduce。map与reduce来源于函数式编程的两个方法。Hadoop的MapReduce是对Google MapReduce的一个开源实现。它提供Map与Reduce两个接...
我终于能够在Hadoop上启动map-reduce工作(在单个debian机器上运行).但是,map reduce作业始终失败,并显示以下错误:hadoopmachine@debian:~$./hadoop-1.0.1/bin/hadoop jar hadooptest/main.jar nl.mydomain.hadoop.debian.test.Main /user/hadoopmachine/input /user/hadoopmachine/output
Warning: $HADOOP_HOME is deprecated.12/04/03 07:29:35 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Ap...
我发现Windows上的Hadoop有点令人沮丧:我想知道对于Win32用户,是否有Hadoop的替代品.我最看重的功能是:
>易于初始设置和在较小的网络上进行部署(如果我们为该项目分配了20台以上的PC,我会感到惊讶)>易于管理-理想的框架应该具有基于Web / GUI的管理系统,这样我就不必自己写书了.>流行的东西稳定.奖金取决于我们能否及时交付该项目.
背景:
我工作的公司希望建立一个新的网格系统来运行一些财务计算.
我一直在评估的第一个框架是H...
我试图在本地文件系统(独立模式)上测试我的计算机(MacOS 10.7)上的一个非常简单的hadoop map-reduce作业.该作业采用.csv文件(data-01)并计算某些字段的出现次数.
我下载了CDH4 hadoop,运行该作业,它似乎正常启动但是在处理完所有拆分后我得到以下错误:13/03/12 12:11:18 INFO mapred.MapTask: Processing split: file:/path/in/data-01:9999220736+33554432
13/03/12 12:11:18 INFO mapred.MapTask: Map output collector class =...
这是我的地图public static class MapClass extends Mapper<LongWritable, Text, Text, Text> {public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{String[] fields = value.toString().split(",", -20);String country = fields[4];String numClaims = fields[8];if (numClaims.length() > 0 && !numClaims.startsWith("\"")) {context.write(new Text(country), new Tex...