Smooth Support Vector Clustering - Python实现
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Smooth Support Vector Clustering - Python实现,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含16329字,纯文字阅读大概需要24分钟。
内容图文

-
算法特征:
①所有点尽可能落在球内; ②极小化球半径; ③极小化包络误差. -
算法推导:
Part Ⅰ: 模型训练阶段 $\Rightarrow$ 形成聚类轮廓
SVC轮廓线方程如下:
\begin{equation}
h(x) = \|x - a\|_2 = \sqrt{x^{\mathrm{T}}x - 2a^{\mathrm{T}}x + a^{\mathrm{T}}a}
\label{eq_1}
\end{equation}
此即样本点$x$距离球心$a$的$L_2$距离.
本文拟采用$L_2$范数衡量包络误差, 则SVC原始优化问题如下:
\begin{equation}
\begin{split}
\min\quad &\frac{1}{2}R^2 + \frac{c}{2}\sum_{i}\xi_i^2 \\
\mathrm{s.t.}\quad &\|x^{(i)} - a\|_2 \leq R + \xi_i \quad\quad \forall i = 1, 2, \cdots, n
\end{split}
\label{eq_2}
\end{equation}
其中, $R$是球半径, $a$是球心, $\xi_i$是第$i$个样本的包络误差, $c$是权重参数.
根据上述优化问题(\ref{eq_2}), 包络误差$\xi_i$可采用plus function等效表示:
\begin{equation}
\xi_i = (\|x^{(i)} - a\|_2 - R)_+
\label{eq_3}
\end{equation}
由此可将该有约束最优化问题转化为如下无约束最优化问题:
\begin{equation}
\min\quad \frac{1}{2}R^2 + \frac{c}{2}\sum_{i}(\|x^{(i)} - a\|_2 - R)_+^2
\label{eq_4}
\end{equation}
同样, 根据优化问题(\ref{eq_2})KKT条件, 进行如下变数变换:
\begin{equation}
a = A\alpha
\label{eq_5}
\end{equation}
其中, $A = [x^{(1)}, x^{(2)}, \cdots, x^{(n)}]$, $\alpha = [\alpha_1, \alpha_2, \cdots, \alpha_n]^{\mathrm{T}}$. $\alpha$由原变量及对偶变量组成, 此处无需关心其具体形式. 将上式代入式(\ref{eq_4})可得:
\begin{equation}
\min\quad \frac{1}{2}R^2 + \frac{c}{2}\sum_{i}(\|x^{(i)} - A\alpha\|_2 - R)_+^2
\label{eq_6}
\end{equation}
由于权重参数$c$的存在, 上述最优化问题等效如下多目标最优化问题:
\begin{equation}
\begin{cases}
\min\quad \frac{1}{2}R^2 \\
\min\quad \frac{1}{2}\sum\limits_{i}(\|x^{(i)} - A\alpha\|_2 - R)_+^2
\end{cases}
\label{eq_7}
\end{equation}
根据光滑化手段, 有如下等效:
\begin{equation}
\min\quad \frac{1}{2}\sum_{i}(\|x^{(i)} - A\alpha\|_2 - R)_+^2 \quad\Rightarrow\quad \min\quad \frac{1}{2}\sum_i p^2(\|x^{(i)} - A\alpha\|_2 - R, \beta), \quad\text{where }\beta\rightarrow\infty
\label{eq_8}
\end{equation}
光滑化手段详见:
https://www.cnblogs.com/xxhbdk/p/12275567.html
https://www.cnblogs.com/xxhbdk/p/12425701.html
结合式(\ref{eq_7})、式(\ref{eq_8}), 优化问题(\ref{eq_6})等效如下:
\begin{equation}
\min\quad \frac{1}{2}R^2 + \frac{c}{2}\sum_i p^2(\sqrt{x^{(i)\mathrm{T}}x^{(i)} - 2x^{(i)\mathrm{T}}A\alpha + \alpha^{\mathrm{T}}A^{\mathrm{T}}A\alpha} - R, \beta), \quad\text{where }\beta\rightarrow\infty
\label{eq_9}
\end{equation}
为增强模型的聚类能力, 引入kernel trick, 得最终优化问题:
\begin{equation}
\min\quad \frac{1}{2}R^2 + \frac{c}{2}\sum_i p^2(\sqrt{K(x^{(i)\mathrm{T}}, x^{(i)}) - 2K(x^{(i)\mathrm{T}}, A)\alpha + \alpha^{\mathrm{T}}K(A^{\mathrm{T}}, A)\alpha} - R, \beta), \quad\text{where }\beta\rightarrow\infty
\label{eq_10}
\end{equation}
其中, $K$代表kernel矩阵. 内部元素$K_{ij}=k(x^{(i)}, x^{(j)})$由kernel函数决定. 常见的kernel函数如下:
①. 多项式核: $k(x^{(i)}, x^{(j)}) = (x^{(i)}\cdot x^{(j)})^n$
②. 高斯核: $k(x^{(i)}, x^{(j)}) = \mathrm{e}^{-\mu\|x^{(i)} - x^{(j)}\|_2^2}$
结合式(\ref{eq_1})、式(\ref{eq_5})及kernel trick可得最终轮廓线方程:
\begin{equation}
h(x) = \sqrt{K(x^{\mathrm{T}}, x) - 2\alpha^{\mathrm{T}}K(A^{\mathrm{T}}, x) + \alpha^{\mathrm{T}}K(A^{\mathrm{T}}, A)\alpha}
\label{eq_11}
\end{equation}
Part Ⅱ: 聚类分配阶段 $\Rightarrow$ 簇划分
根据如下规则构造邻接矩阵$G$:
\begin{equation}
G_{ij} =
\begin{cases}
1\quad \text{if $h(x) \leq R$, where $x = \lambda x^{(i)} + (1 - \lambda)x^{(j)}$, $\forall \lambda \in (0, 1)$} \\
0\quad \text{otherwise}
\end{cases}
\end{equation}
对该矩阵所定义的图进行深度优先或广度优先遍历, 所得连通分量即为簇的划分.
Part Ⅲ: 优化协助信息
拟设式(\ref{eq_10})之目标函数为$J$, 则有:
\begin{equation}
J = \frac{1}{2}R^2 + \frac{c}{2}\sum_i p^2(z_i - R, \beta)
\end{equation}
其中, $z_i = \sqrt{K(x^{(i)\mathrm{T}}, x^{(i)}) - 2K(x^{(i)\mathrm{T}}, A)\alpha + \alpha^{\mathrm{T}}K(A^{\mathrm{T}}, A)\alpha}$.
相关一阶信息如下:
\begin{gather*}
y_i = K(A^{\mathrm{T}}, A)\alpha - K^{\mathrm{T}}(x^{(i)\mathrm{T}}, A) \\
\frac{\partial J}{\partial \alpha} = c\sum_ip(z_i - R, \beta)s(z_i - R, \beta)z_i^{-1}y_i \\
\frac{\partial J}{\partial R} = R - c\sum_ip(z_i - R, \beta)s(z_i - R, \beta)
\end{gather*}
目标函数$J$之gradient如下:
\begin{gather*}
\nabla J =
\begin{bmatrix}
\frac{\partial J}{\partial \alpha} \\
\frac{\partial J}{\partial R}
\end{bmatrix}
\end{gather*}
Part Ⅳ: 聚类数据集
现以如下环状数据集为例进行算法实施, 相关数据分布如下: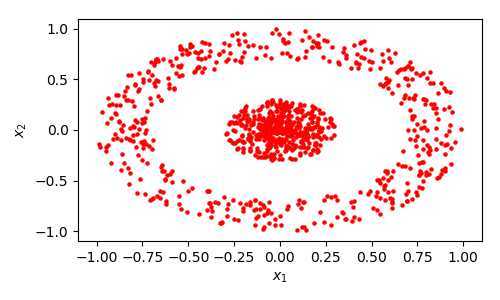
 View Code
View Code1# 生成聚类数据集 - 环状 2 3import numpy 4from matplotlib import pyplot as plt 5 6 7numpy.random.seed(0) 8 910def ring(type1Size=100, type2Size=100): 11 theta1 = numpy.random.uniform(0, 2 * numpy.pi, type1Size) 12 theta2 = numpy.random.uniform(0, 2 * numpy.pi, type2Size) 1314 R1 = numpy.random.uniform(0, 0.3, type1Size).reshape((-1, 1)) 15 R2 = numpy.random.uniform(0.7, 1, type2Size).reshape((-1, 1)) 16 X1 = R1 * numpy.hstack((numpy.cos(theta1).reshape((-1, 1)), numpy.sin(theta1).reshape((-1, 1)))) 17 X2 = R2 * numpy.hstack((numpy.cos(theta2).reshape((-1, 1)), numpy.sin(theta2).reshape((-1, 1)))) 1819 X = numpy.vstack((X1, X2)) 20return X 212223def ring_plot(): 24 X = ring(300, 300) 2526 fig = plt.figure(figsize=(5, 3)) 27 ax1 = plt.subplot() 2829 ax1.scatter(X[:, 0], X[:, 1], marker="o", color="red", s=5) 30 ax1.set(xlim=[-1.1, 1.1], ylim=[-1.1, 1.1], xlabel="$x_1$", ylabel="$x_2$") 3132 fig.tight_layout() 33 fig.savefig("ring.png", dpi=100) 34353637if__name__ == "__main__": 38 ring_plot()

-
代码实现:
View Code1 # Smooth Support Vector Clustering之实现 2 3 import copy 4 import numpy 5 from matplotlib import pyplot as plt 6 7numpy.random.seed(0) 8 9 10def ring(type1Size=100, type2Size=100): 11 theta1 = numpy.random.uniform(0, 2 * numpy.pi, type1Size) 12 theta2 = numpy.random.uniform(0, 2 * numpy.pi, type2Size) 13 14 R1 = numpy.random.uniform(0, 0.3, type1Size).reshape((-1, 1)) 15 R2 = numpy.random.uniform(0.7, 1, type2Size).reshape((-1, 1)) 16 X1 = R1 * numpy.hstack((numpy.cos(theta1).reshape((-1, 1)), numpy.sin(theta1).reshape((-1, 1)))) 17 X2 = R2 * numpy.hstack((numpy.cos(theta2).reshape((-1, 1)), numpy.sin(theta2).reshape((-1, 1)))) 18 19# R1 = numpy.random.uniform(0, 0.3, type1Size).reshape((-1, 1)) 20# X1 = R1 * numpy.hstack((numpy.cos(theta1).reshape((-1, 1)), numpy.sin(theta1).reshape((-1, 1)))) - 0.5 21# X2 = R1 * numpy.hstack((numpy.cos(theta2).reshape((-1, 1)), numpy.sin(theta2).reshape((-1, 1)))) + 0.5 22 23 X = numpy.vstack((X1, X2)) 24return X 25 26 27# 生成聚类数据 28 X = ring(300, 300) 29 30 31class SSVC(object): 32 33def__init__(self, X, c=1, mu=1, beta=300, sampleCnt=30): 34‘‘‘ 35 X: 聚类数据集, 1行代表一个样本 36‘‘‘ 37 self.__X = X # 聚类数据集 38 self.__c = c # 误差项权重系数 39 self.__mu = mu # gaussian kernel参数 40 self.__beta = beta # 光滑华参数 41 self.__sampleCnt = sampleCnt # 邻接矩阵采样数 42 43 self.__A = X.T 44 45 46def get_clusters(self, IDPs, SVs, alpha, R, KAA=None): 47‘‘‘ 48 构造邻接矩阵, 进行簇划分 49 注意, 此处仅需关注IDPs、SVs 50‘‘‘ 51if KAA is None: 52 KAA = self.get_KAA() 53 54if IDPs.shape[0] == 0 and SVs.shape[0] == 0: 55raise Exception(">>> Both IDPs and SVs are empty! <<<") 56elif IDPs.shape[0] == 0 and SVs.shape[0] != 0: 57 currX = SVs 58elif IDPs.shape[0] != 0 and SVs.shape[0] == 0: 59 currX = IDPs 60else: 61 currX = numpy.vstack((IDPs, SVs)) 62 adjMat = self.__build_adjMat(currX, alpha, R, KAA) 63 64 idxList = list(range(currX.shape[0])) 65 clusters = self.__get_clusters(idxList, adjMat) 66 67 clustersOri = list() 68for idx, cluster in enumerate(clusters): 69print(‘Size of cluster {} is about {}‘.format(idx, len(cluster))) 70 clusterOri = list(currX[idx, :] for idx in cluster) 71 clustersOri.append(numpy.array(clusterOri)) 72return clustersOri 73 74 75def get_IDPs_SVs_BSVs(self, alpha, R): 76‘‘‘ 77 获取IDPs: Interior Data Points 78 获取SVs: Support Vectors 79 获取BSVs: Bounded Support Vectors 80‘‘‘ 81 X = self.__X 82 KAA = self.get_KAA() 83 84 epsilon = 3.e-3 * R 85 IDPs, SVs, BSVs = list(), list(), list() 86 87for x in X: 88 hVal = self.get_hVal(x, alpha, KAA) 89if hVal >= R + epsilon: 90 BSVs.append(x) 91elif numpy.abs(hVal - R) < epsilon: 92 SVs.append(x) 93else: 94 IDPs.append(x) 95return numpy.array(IDPs), numpy.array(SVs), numpy.array(BSVs) 96 97 98def get_hVal(self, x, alpha, KAA=None): 99‘‘‘100 计算x与超球球心在特征空间中的距离 101‘‘‘102 A = self.__A103 mu = self.__mu104105 x = numpy.array(x).reshape((-1, 1)) 106 KAx = self.__get_KAx(A, x, mu) 107if KAA is None: 108 KAA = self.__get_KAA(A, mu) 109 term1 = self.__calc_gaussian(x, x, mu) 110 term2 = -2 * numpy.matmul(alpha.T, KAx)[0, 0] 111 term3 = numpy.matmul(numpy.matmul(alpha.T, KAA), alpha)[0, 0] 112 hVal = numpy.sqrt(term1 + term2 + term3) 113return hVal 114115116def get_KAA(self): 117 A = self.__A118 mu = self.__mu119120 KAA = self.__get_KAA(A, mu) 121return KAA 122123124def optimize(self, maxIter=3000, epsilon=1.e-9): 125‘‘‘126 maxIter: 最大迭代次数 127 epsilon: 收敛判据, 梯度趋于0则收敛 128‘‘‘129 A = self.__A130 c = self.__c131 mu = self.__mu132 beta = self.__beta133134 alpha, R = self.__init_alpha_R((A.shape[1], 1)) 135 KAA = self.__get_KAA(A, mu) 136 JVal = self.__calc_JVal(KAA, c, beta, alpha, R) 137 grad = self.__calc_grad(KAA, c, beta, alpha, R) 138 D = self.__init_D(KAA.shape[0] + 1) 139140for i in range(maxIter): 141print("iterCnt: {:3d}, JVal: {}".format(i, JVal)) 142if self.__converged1(grad, epsilon): 143return alpha, R, True 144145 dCurr = -numpy.matmul(D, grad) 146 ALPHA = self.__calc_ALPHA_by_ArmijoRule(alpha, R, JVal, grad, dCurr, KAA, c, beta) 147148 delta = ALPHA * dCurr 149 alphaNew = alpha + delta[:-1, :] 150 RNew = R + delta[-1, -1] 151 JValNew = self.__calc_JVal(KAA, c, beta, alphaNew, RNew) 152if self.__converged2(delta, JValNew - JVal, epsilon ** 2): 153return alpha, R, True 154155 gradNew = self.__calc_grad(KAA, c, beta, alphaNew, RNew) 156 DNew = self.__update_D_by_BFGS(delta, gradNew - grad, D) 157158 alpha, R, JVal, grad, D = alphaNew, RNew, JValNew, gradNew, DNew 159else: 160if self.__converged1(grad, epsilon): 161return alpha, R, True 162return alpha, R, False 163164165def__update_D_by_BFGS(self, sk, yk, D): 166 rk = 1 / numpy.matmul(yk.T, sk)[0, 0] 167168 term1 = rk * numpy.matmul(sk, yk.T) 169 term2 = rk * numpy.matmul(yk, sk.T) 170 I = numpy.identity(term1.shape[0]) 171 term3 = numpy.matmul(I - term1, D) 172 term4 = numpy.matmul(term3, I - term2) 173 term5 = rk * numpy.matmul(sk, sk.T) 174175 DNew = term4 + term5 176return DNew 177178179def__calc_ALPHA_by_ArmijoRule(self, alphaCurr, RCurr, JCurr, gCurr, dCurr, KAA, c, beta, C=1.e-4, v=0.5): 180 i = 0 181 ALPHA = v ** i 182 delta = ALPHA * dCurr 183 alphaNext = alphaCurr + delta[:-1, :] 184 RNext = RCurr + delta[-1, -1] 185 JNext = self.__calc_JVal(KAA, c, beta, alphaNext, RNext) 186while True: 187if JNext <= JCurr + C * ALPHA * numpy.matmul(dCurr.T, gCurr)[0, 0]: break188 i += 1 189 ALPHA = v ** i 190 delta = ALPHA * dCurr 191 alphaNext = alphaCurr + delta[:-1, :] 192 RNext = RCurr + delta[-1, -1] 193 JNext = self.__calc_JVal(KAA, c, beta, alphaNext, RNext) 194return ALPHA 195196197def__converged1(self, grad, epsilon): 198if numpy.linalg.norm(grad, ord=numpy.inf) <= epsilon: 199return True 200return False 201202203def__converged2(self, delta, JValDelta, epsilon): 204 val1 = numpy.linalg.norm(delta, ord=numpy.inf) 205 val2 = numpy.abs(JValDelta) 206if val1 <= epsilon or val2 <= epsilon: 207return True 208return False 209210211def__init_D(self, n): 212 D = numpy.identity(n) 213return D 214215216def__init_alpha_R(self, shape): 217‘‘‘218 alpha、R之初始化 219‘‘‘220 alpha, R = numpy.zeros(shape), 0 221return alpha, R 222223224def__calc_grad(self, KAA, c, beta, alpha, R): 225 grad_alpha = numpy.zeros((KAA.shape[0], 1)) 226 grad_R = 0 227228 term = numpy.matmul(numpy.matmul(alpha.T, KAA), alpha)[0, 0] 229 z = list(numpy.sqrt(KAA[idx, idx] - 2 * numpy.matmul(KAA[idx:idx+1, :], alpha)[0, 0] + term) for idx in range(KAA.shape[0])) 230 term1 = numpy.matmul(KAA, alpha) 231 y = list(term1 - KAA[:, idx:idx+1] for idx in range(KAA.shape[0])) 232233for i in range(KAA.shape[0]): 234 term2 = self.__p(z[i] - R, beta) * self.__s(z[i] - R, beta) 235 grad_alpha += term2 * y[i] / z[i] 236 grad_R += term2 237 grad_alpha *= c 238 grad_R = R - c * grad_R 239240 grad = numpy.vstack((grad_alpha, [[grad_R]])) 241return grad 242243244def__calc_JVal(self, KAA, c, beta, alpha, R): 245 term = numpy.matmul(numpy.matmul(alpha.T, KAA), alpha)[0, 0] 246 z = list(numpy.sqrt(KAA[idx, idx] - 2 * numpy.matmul(KAA[idx:idx+1, :], alpha)[0, 0] + term) for idx in range(KAA.shape[0])) 247248 term1 = R ** 2 / 2 249 term2 = sum(self.__p(zi - R, beta) ** 2 for zi in z) * c / 2 250 JVal = term1 + term2 251return JVal 252253254def__p(self, x, beta): 255 term = x * beta 256if term > 10: 257 val = x + numpy.log(1 + numpy.exp(-term)) / beta 258else: 259 val = numpy.log(numpy.exp(term) + 1) / beta 260return val 261262263def__s(self, x, beta): 264 term = x * beta 265if term > 10: 266 val = 1 / (numpy.exp(-beta * x) + 1) 267else: 268 term1 = numpy.exp(term) 269 val = term1 / (1 + term1) 270return val 271272273def__d(self, x, beta): 274 term = x * beta 275if term > 10: 276 term1 = numpy.exp(-term) 277 val = beta * term1 / (1 + term1) ** 2 278else: 279 term1 = numpy.exp(term) 280 val = beta * term1 / (term1 + 1) ** 2 281return val 282283284def__calc_gaussian(self, x1, x2, mu): 285 val = numpy.exp(-mu * numpy.linalg.norm(x1 - x2) ** 2) 286# val = numpy.sum(x1 * x2)287return val 288289290def__get_KAA(self, A, mu): 291 KAA = numpy.zeros((A.shape[1], A.shape[1])) 292for rowIdx in range(KAA.shape[0]): 293for colIdx in range(rowIdx + 1): 294 x1 = A[:, rowIdx:rowIdx+1] 295 x2 = A[:, colIdx:colIdx+1] 296 val = self.__calc_gaussian(x1, x2, mu) 297 KAA[rowIdx, colIdx] = KAA[colIdx, rowIdx] = val 298return KAA 299300301def__get_KAx(self, A, x, mu): 302 KAx = numpy.zeros((A.shape[1], 1)) 303for rowIdx in range(KAx.shape[0]): 304 x1 = A[:, rowIdx:rowIdx+1] 305 val = self.__calc_gaussian(x1, x, mu) 306 KAx[rowIdx, 0] = val 307return KAx 308309310def__get_segment(self, xi, xj, sampleCnt): 311 lamdaList = numpy.linspace(0, 1, sampleCnt + 2) 312 segmentList = list(lamda * xi + (1 - lamda) * xj for lamda in lamdaList[1:-1]) 313return segmentList 314315316def__build_adjMat(self, X, alpha, R, KAA): 317 sampleCnt = self.__sampleCnt318319 adjMat = numpy.zeros((X.shape[0], X.shape[0])) 320for i in range(adjMat.shape[0]): 321for j in range(i+1, adjMat.shape[1]): 322 xi = X[i, :] 323 xj = X[j, :] 324 xs = self.__get_segment(xi, xj, sampleCnt) 325for x in xs: 326 dist = self.get_hVal(x, alpha, KAA) 327if dist > R: 328 adjMat[i, j] = adjMat[j, i] = 0 329break330else: 331 adjMat[i, j] = adjMat[j, i] = 1 332333 numpy.savetxt("adjMat.txt", adjMat, fmt="%d") 334return adjMat 335336337def__get_clusters(self, idxList, adjMat): 338 clusters = list() 339while idxList: 340 idxCurr = idxList.pop(0) 341 queue = [idxCurr] 342 cluster = list() 343while queue: 344 idxPop = queue.pop(0) 345 cluster.append(idxPop) 346for idx in copy.deepcopy(idxList): 347if adjMat[idxPop, idx] == 1: 348 idxList.remove(idx) 349 queue.append(idx) 350 clusters.append(cluster) 351352return clusters 353354355class SSVCPlot(object): 356357def profile_plot(self, X, ssvcObj, alpha, R): 358 surfX1 = numpy.linspace(-1.1, 1.1, 100) 359 surfX2 = numpy.linspace(-1.1, 1.1, 100) 360 surfX1, surfX2 = numpy.meshgrid(surfX1, surfX2) 361362 KAA = ssvcObj.get_KAA() 363 surfY = numpy.zeros(surfX1.shape) 364for rowIdx in range(surfY.shape[0]): 365for colIdx in range(surfY.shape[1]): 366 surfY[rowIdx, colIdx] = ssvcObj.get_hVal((surfX1[rowIdx, colIdx], surfX2[rowIdx, colIdx]), alpha, KAA) 367368 IDPs, SVs, BSVs = ssvcObj.get_IDPs_SVs_BSVs(alpha, R) 369 clusters = ssvcObj.get_clusters(IDPs, SVs, alpha, R, KAA) 370371 fig = plt.figure(figsize=(10, 3)) 372 ax1 = plt.subplot(1, 2, 1) 373 ax2 = plt.subplot(1, 2, 2) 374375 ax1.contour(surfX1, surfX2, surfY, levels=36) 376 ax1.scatter(X[:, 0], X[:, 1], marker="o", color="red", s=5) 377 ax1.set(xlim=[-1.1, 1.1], ylim=[-1.1, 1.1], xlabel="$x_1$", ylabel="$x_2$") 378379if BSVs.shape[0] != 0: 380 ax2.scatter(BSVs[:, 0], BSVs[:, 1], color="k", s=5, label="$BSVs$") 381for idx, cluster in enumerate(clusters): 382 ax2.scatter(cluster[:, 0], cluster[:, 1], s=3, label="$cluster\ {}$".format(idx)) 383 ax2.set(xlim=[-1.1, 1.1], ylim=[-1.1, 1.1], xlabel="$x_1$", ylabel="$x_2$") 384 ax2.legend() 385386 fig.tight_layout() 387 fig.savefig("profile.png", dpi=100) 388389390391if__name__ == "__main__": 392 ssvcObj = SSVC(X, c=100, mu=7, beta=300) 393 alpha, R, tab = ssvcObj.optimize() 394 spObj = SSVCPlot() 395 spObj.profile_plot(X, ssvcObj, alpha, R) 396 -
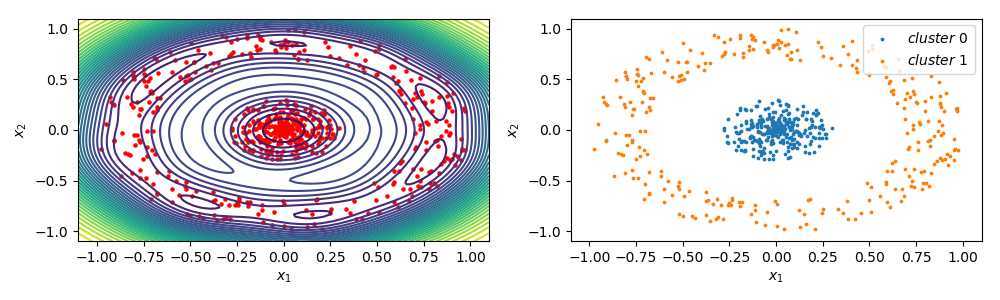
结果展示:
 左侧为聚类轮廓, 右侧为簇划分. 很显然, 此处在合适的超参数选取下, 将原始数据集划分为2个簇.
左侧为聚类轮廓, 右侧为簇划分. 很显然, 此处在合适的超参数选取下, 将原始数据集划分为2个簇. -
使用建议:
①. 本文的优化问题与参考文档的优化问题略有差异, 参考文档中关于SVC的原问题并非严格意义上的凸问题.
②. SSVC本质上求解的仍然是原问题, 此时$\alpha$仅作为变数变换引入, 无需满足KKT条件中对偶可行性.
③. 数据集是否需要归一化, 应按实际情况予以考虑; 簇的划分敏感于超参数的选取. -
参考文档:
Ben-Hur A, Horn D, Siegelmann HT, Vapnik V. Support vector clustering. Journal of Machine Learning Research, 2001, 2(12): 125-137.
原文:https://www.cnblogs.com/xxhbdk/p/12586604.html
内容总结
以上是互联网集市为您收集整理的Smooth Support Vector Clustering - Python实现全部内容,希望文章能够帮你解决Smooth Support Vector Clustering - Python实现所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】