ELK---- Elasticsearch 使用ik中文分词器
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了ELK---- Elasticsearch 使用ik中文分词器,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含776字,纯文字阅读大概需要2分钟。
内容图文

0、默认分词器。
默认分词器,查询的时候会把中文一个汉字当作一个关键字拆分,这样是不符合我们的需求的,所以需要安装分词器。
1、下载分词器。
当前有多种分词器可下载,据说比较好用的是IK分词器。
注意,下载分词器的时候,版本必须要与Elasticsearch安装的版本一致,否则会出现不可描述的错误。
下载地址: https://github.com/medcl/elasticsearch-analysis-ik/releases
注意: es-ik分词插件版本一定要和es安装的版本对应
之前自带的分词器
查询地址:http://192.168.5.131:9200/_analyze
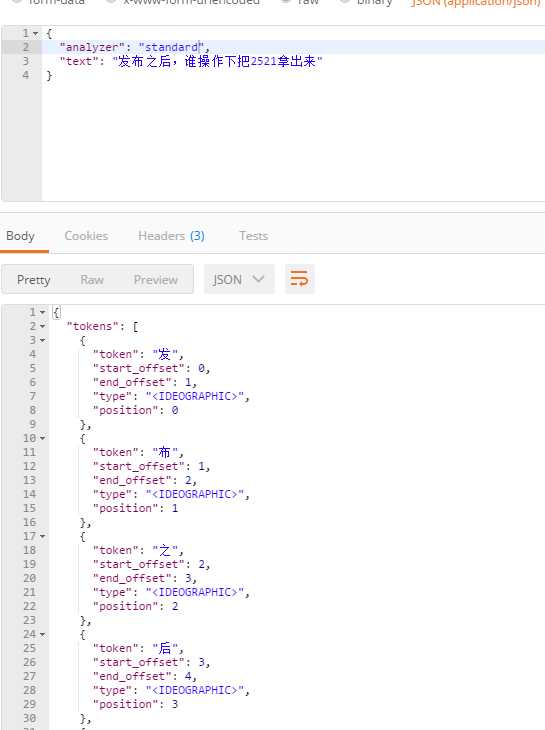
{
"
analyzer
": "standard",
"text": "中华人民共和国中华人民共和国中华人民shiwom是"
}
2、安装分词器。
下载好之后的分词器zip压缩包,上传到服务器中 Elasticsearch的安装目录的plugins目录下。
用unzip 进行解压。
linux解压zip文件,命令:unzip 如果没有该命令,可先安装,命令为:
yum -y install unzip
安装好后,就解压
unzip ik.zip
就OK了,然后kill -9 原来的进程 ,再启动,就可以了。在启动的日志中,我们可以看到,
3、测试。
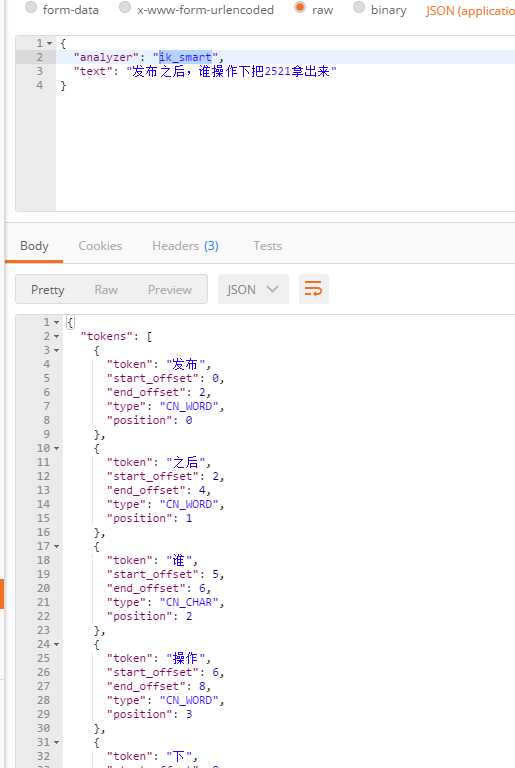
查询地址:http://192.168.5.131:9200/_analyze
将分词器类型更换为:ik_smart
{
"
analyzer
": "ik_smart",
"text": "发布之后,谁操作下把2521拿出来"
}
原文:https://www.cnblogs.com/a393060727/p/12099567.html
内容总结
以上是互联网集市为您收集整理的ELK---- Elasticsearch 使用ik中文分词器全部内容,希望文章能够帮你解决ELK---- Elasticsearch 使用ik中文分词器所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。