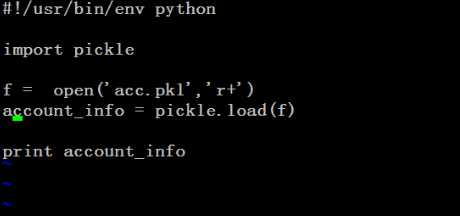
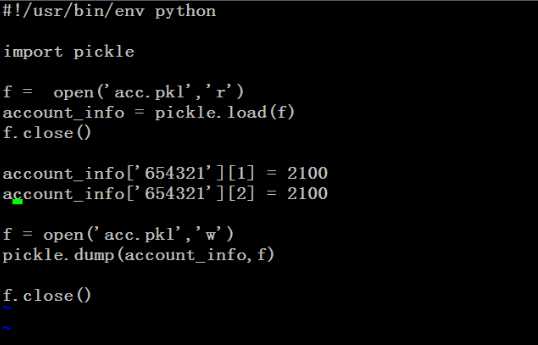
dump扔到硬盘上 load方法:加载到内存 修改某个值:load加载到内存close在open w 打开再写就是覆盖,不关的情况下dump会出现两段再dump一下 覆盖到硬盘close原文:http://www.cnblogs.com/lonely-buffoon/p/5986497.html
5、sys模块sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称5.1 使用sys.argv进行登录判断,跳过 i/o阻塞#使用sys.argv进行登录判断,跳过 i/o阻塞
import s...
我们把变量从内存中变成可存储或传输的过程称之为序列化。 序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。 反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。encode 编码和 decode 解码 是在文件中读取或者写入数据,但是都是写入的字符串的二进制格式,没有数据类型的分别 两者都是将数据转换为 bytes 但是 pickle 变成二进制还能保持数据类型 enco...
一、time与datetime模块time模块: 时间戳:表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,返回类型为float类型 格式化时间字符串(Format String) 结构化的时间(struct_time):struct_time元组共有9个元素(年月日时分秒,一年中的第几周,一年中的第几天,夏令时)# print(time.time())#1533962144.060534
# print(time.localtime())#time.struct_time(tm_year=2018, tm_mon=8, tm_mday=11, tm_hour=12, tm_min=36, tm_se...
复习‘‘‘项目开发规范ATM -- bin: 可执行文件 # run.py import os import sys BASE_DIR = os.path.dirname(os.path.dirname(__file__)) # ATM文件夹 sys.path.append(BASE_DIR) from core import main -- core:核心代码 # main.py from setting import settings from lib import mp # login.py # from bin.run import BASE_DIR # u_info = os.path.join(BASE_DIR, ‘db‘, ‘user.info‘) from setting.set...
对于保存文本,如果要保存的数据像列表,字典甚至是类的实例时,普通的文件操作就会很复杂,如果把这些转化为字符串写入到文本文件中保存,把这个过程反过来读取的话就会异常麻烦,因此python提供了一个标准模块pickle。 pickle模块翻译为泡菜,python使用这个模块,可以非常容易地将列表、字典这类复杂数据类型存储为文件,把所有python的对象转化为二进制的形式存放,这个过程称为pickling,二进制形式转换回对象的过程为unpi...
json模块json.dumps 将 Python 对象编码成 JSON 字符串json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型。 pickle pickle.dump(obj, file, [,protocol])含义:pickle.dump(对象,文件,[使用协议])将要持久化的数据“对象”,保存到“文件”中,使用有3种协议,索引0为ASCII,1为旧式二进制,2为新式二进制协议,不同之处在于2要更高效一些。默认dump方法使用0做协议pickle.load(file)含义:pickle....
序列化Python中用于序列化的两个模块json 用于【字符串】和 【python基本数据类型】 间进行转换pickle 用于【python特有的类型】 和 【python基本数据类型】间进行转换Json模块提供了四个功能:dumps、dump、loads、loadpickle模块提供了四个功能:dumps、dump、loads、loadjson模块# json()将字符串形式的列表或字典转换为list或dict类型,json是所有语言相互通信的方式# 注意外层字符形式一定是‘‘单引号,‘{"a":"xiao","...
json & picklePython中用于序列化的两个模块json 用于【字符串】和 【python基本数据类型】 间进行转换pickle 用于【python特有的类型】 和 【python基本数据类型】间进行转换Json模块提供了四个功能:dumps、dump、loads、load1、dumps序列化和loads反序列化dumps()序列化import json #导入json模块
info = {‘name‘:"zhangqigao","age":22
}with open("test.txt","w") as f: #以普通模式写入data = json.dumps(info)...
Pickle模块可以序列化对象并保存到磁盘中,并在需要的时候读取出来,任何对象都可以执行序列化操作。在机器学习中,我们常常需要把训练好的模型存储起来,这样在进行决策时直接将模型独处,而不需要重新训练模型,这样就大大节约了时间。pickle模块常用函数dump(obj,file,[,protocol])将obj对象序列化存入已经打开的file中load(file)将file中的对象序列化读出dumps(obj,[,protocol])将obj对象序列化为string形式,而不是存入文件中...
1、pickle模块python持久化的存储数据:python程序运行中得到了一些字符串,列表,字典等数据,想要长久的保存下来,方便以后使用,而不是简单的放入内存中关机断电就丢失数据。python模块大全中pickle模块就排上用场了, 他可以将对象转换为一种可以传输或存储的格式。pickle模块将任意一个python对象转换成一系统字节的这个操作过程叫做串行化对象。python的pickle模块实现了python的所有数据序列和反序列化。基本上功能使用和JS...
python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。(原文来自
http://www.cnblogs.com/pzxbc/archive/2012/03/18/2404715.html)基本接口: pickle.dump(obj, file,
[,protocol]) 注解:将对象obj保存到文件file中去。 protocol为序列化使用的协...
参考 http://www.cnblogs.com/pzxbc/archive/2012/03/18/2404715.htmlpython的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。 基本接口: pickle.dump(obj, file, [,protocol]) 注解:将对象obj保存到文件file中去。 protocol为序列化使用的协议版本...
---恢复内容开始---dic = {"name":"kevin","age":"20"}f = open("json.txt",‘w‘)f.write(dic) 这里是无法写入的,写入要求是一个str,所以要用到json作为数据格式的转换,就是进行序列化的转换。import json,pickledata = json.dumps(dic)f.write(data) 这样就可以写入。需要通过以字典的方式读取,则读取的时候才去如下步骤:f = open("json.txt",‘r‘)data = json.loads(f.read())data["name"]要注意json无法对函数进行序列化...
序列化:#!usr/bin/env python# -*- coding:utf-8 -*-__author__ = "Samson"import json,pickle#json能用于其他语言中,只能序列化一些简单的数据类型,比如字典之类;而pickle只能用于python中,能序列化所有的数据类型def sayhi(name):#程序运行结束时会释放掉该内存 print("name, ",name)info = { "name":"alex", "age":22, "func":sayhi#使用json序列化不行,而用pickle序列化是可以的}f = open("test.text","wb")...