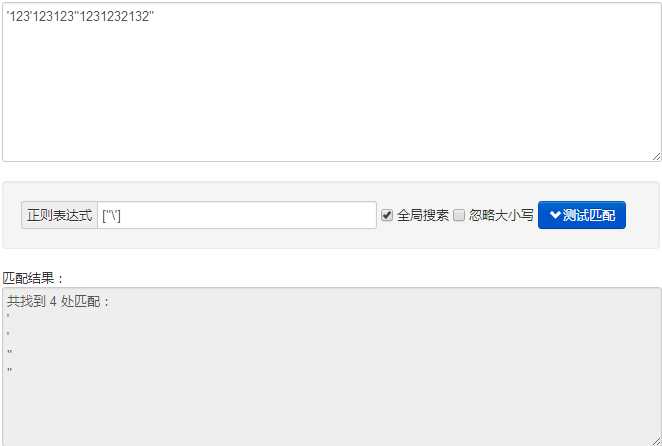
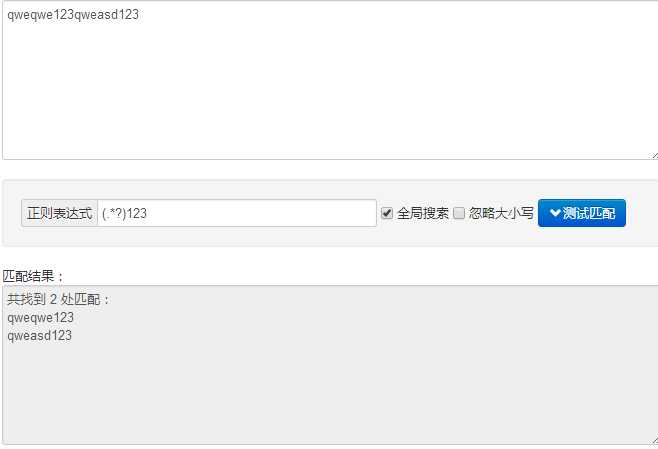
["\‘] ----------- 匹配单双引号 (.*?)xxx ----------- 匹配任意长度字符+xxx 正则表达式在线测试工具:http://tool.oschina.net/regex/?optionGlobl=global 未完待续~~~将一直补充~~ 原文:https://www.cnblogs.com/4wheel/p/8550426.html
一、BeautifulSoup库的使用1.对beautifulSoup库的理解HTML文档可以看作是有很多个标签相互嵌套形成的“标签树”,而BeautifulSoup库是解析、遍历、维护“标签树”的功能库。2.BeautifulSoup库的基本使用#HTML文档《==》标签树《==》BeautifulSoup类from bs4 import BeautifulSoup
soup=BeautifulSoup("<html>data</html>","html.parser") #“html.parser”是beautiflSoup库解析器
soup2=BeautifulSoup(open("D://demo.html"),"html...
新建文件 requirements.txt修改requirements.txt文件内容如下:# need to install module bs4pymongorequestsjson然后执行命令:sudo pip install -r requirements.txt 原文:https://www.cnblogs.com/rohens-hbg/p/14445957.html
库的安装pip3 install selenium声明浏览器对象from selenium import webdriverbrowser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()访问页面from selenium import webdriverbrowser = webdriver.Chrome()
browser.get(‘https://www.taobao.com‘)
print(browser.page_source)
browser.close()查找元素查找单个元素的 element* ...
一、爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片。二、Scrapy安装指南我们的安装...
爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据import requests
from fake_useragent import UserAgent
ua = UserAgent(use_cache_server=False,verify_ssl=False).random
headers = {‘User-Agent‘:ua
}
url = ‘http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList‘
pageNum = 3
for page in range(3,5):data = {‘on‘: ‘true‘,‘page‘: str(page),‘pageSize‘: ‘15‘,‘prod...
一、CrawlSpider根据官方文档可以了解到, 虽然对于特定的网页来说不一定是最好的选择, 但是 CrwalSpider 是爬取规整的网页时最常用的 spider, 而且有很好的可塑性.除了继承自 Spider 的属性, 它还拓展了一些其他的属性. 对我来说, 最常用的就是 rules 了.爬虫一般来说分为垂直爬取和水平爬取, 这里拿 猫眼电影TOP100 举例. 垂直爬取就是从目录进入到内容详情后爬取, 即从当前页进入某一影片的详情页面; 水平爬取就是从这一页目录翻...
PM2.5 对人体的健康影响很大,所以空气中的 PM2.5
实时信息受到越来越多的关注。Python 的 Pandas 套件不但可以自动读取网页中的表格
数据 , 还可对数据进行修改、排序等处理,也可绘制统计
图表,对于信息抓取、整理以及显示是不可多得的好工具。将开发一个 PM2.5 实时监测显示器程序 。 本程序
可以直接读取行指定网站上的 PM2.5 数据,并在整理后显
示,这样就可以方便地让用户随时看到最新的 PM2.5 监测
数据。应用程序总览
执...
队列-deque有了上面一节的基础,当然你需要完全掌握上一节的所有方法,因为上一节的方法,在下面的教程中会反复的用到。如果你没有记住,请你返回上一节。这一节我们要了解一种队列--deque。在下面的爬虫基础中,我们也要反复的使用deque,来完成网址的出队入队。有了对deque基本的认识,我们开始进一步的学习了解他。colloections.deque([iterable[,maxlen]])从左到右初始化一个新的deque对象,如果iterable没有给出,那么产生一个...
python 爬虫爬取美女图片#coding=utf-8import urllib
import re
import os
import time
import threadingdef getHtml(url):page = urllib.urlopen(url)html = page.read()return htmldef getImgUrl(html,src):srcre = re.compile(src)srclist = re.findall(srcre,html)return srclistdef getImgPage(html):url = r'http://.*\.html'urlre = re.compile(url)urllist = re.findall(urlre,html)return urllistdef downloadImg(url):ht...
目录Windows下安装Anaconda,问题及解决1.wsgidav版本问题2.wsgidav版本问题3.webui显示不全,或者说相关的css和js加载不出来运行后的webUI和网页上看到的不一样,查看http://127.0.0.1:5000的源码, 发现是cdnjs.cloudflare.com无法响应4.运行pyspider all命令后一直停留在 result_worker starting...参考:Windows下安装Anaconda,开一个Python3.6的虚拟环境(直接创环境无法设置Python版本,新建环境后使用命令conda install python...
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理以下文章来源于腾讯云,作者:Python进击者首先,什么是分布式爬虫?其实简单粗暴一点解释就是我们平时写的爬虫都是孤军奋战,分布式爬虫就是一支军队作战。专业点来说就是应用多台机器同时实现爬虫任务,这多台机器上的爬虫,就是称作分布式爬虫。分布式爬虫的难点不在于他本身有多难写,而是在于多台机器之间...
代码如下: 1#coding:utf-8 2# import datetime 3import requests4import os5import sys6from lxml import etree7import codecs8 9class Spider:
10def__init__(self):
11 self.headers = {}
12 self.headers[‘User_Agent‘] = ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:60.0) Gecko/20100101 Firefox/60.0‘13 self.headers[‘Referer‘] = ‘http://www.mzitu.com/all/‘1415def crawl(self, ro...
解析库的安装pip3 install beautifulsoup4初始化 BeautifulSoup(str,"解析库")from bs4 import BeautifulSouphtml=‘‘‘<div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel-body"> <ul class="list" id="list-1"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> ...
import refrom urllib import requestclass Sprder: def __init__(self): self.page=1 self.switch=True def loadPage(self): """" 下载页面 """ url="http://www.neihan8.com/article/list_5_"+str(self.page)+".html" user_agent = ‘Mozilla/5.0 (compatible; MSIE 9.0; Windows NT6.1; Trident / 5.0‘ headers = {‘User-Agent‘: user_agent} request...