Hadoop 系列(一)文件读写过程及MR过程
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hadoop 系列(一)文件读写过程及MR过程,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5784字,纯文字阅读大概需要9分钟。
内容图文
想把知识体系好好补充一下,就开始hadoop系列的文章,好好的把hadoop从头到尾学习一下。
一:文件IO流程
文件读流程
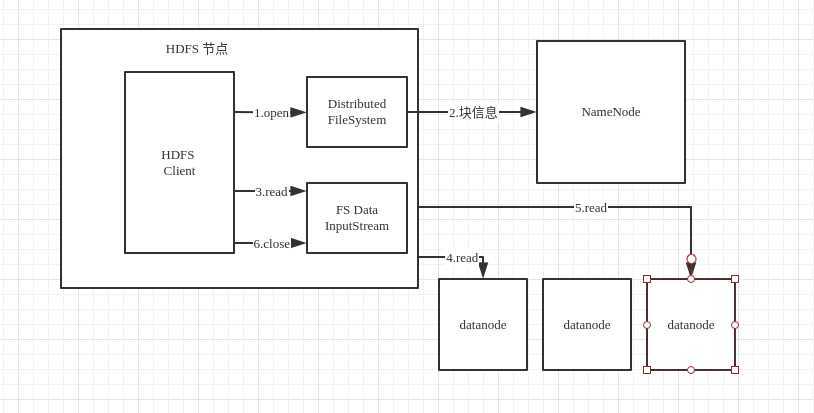
1.client打开DistributesFileSystem API(集群文件系统的API) open方法
2.调用API的get块信息的方法(拿到所有的块信息)
3.打开FSDataInputStream API(读取数据的API),一个块三个副本(三台机器),(就近)找一个的机器去根据块信息读取对应的数据
4.一个块读取完成之后,在元数据里面找到下一个块最近的datanode
5.将所有的块拿过来之后,在客户端进行拼接成一个完成的文件
6.关闭链接(资源)
文件写流程
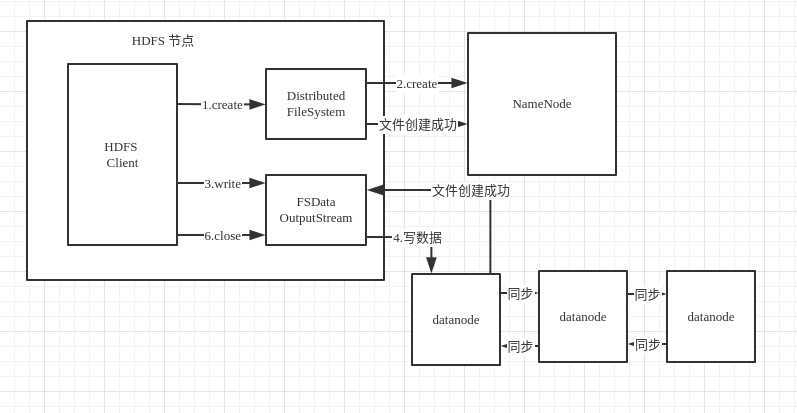
1.client打开DistributesFileSystem API(集群文件系统的API) create方法
2.传入文件的相关信息(文件名称,文件大小,文件拥有者)返回文件切成几个块,哪一个块放在哪一个文件上。
3.打开FSDataOutputStream API(写取数据的API),将一个块写到一个机器上,这个机器在同步到其他机器上
4.文件总体完成之后在告诉Namenode 写文件成功
5.关闭链接(资源)
MR 过程
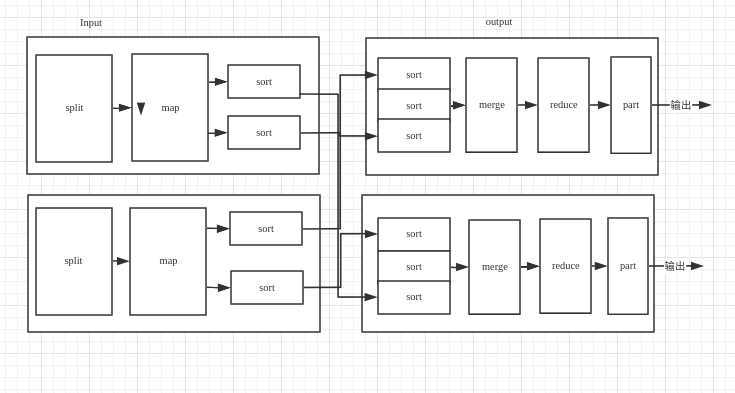
1.将每个文件存为不同的block,将block进行切分操作操作(影响map数)
2.有可能有多个maptask线程并发执行,具体执行看代码怎么去写。(输出和输入必须是键值对的形式)
3.将相同的数据shuffle到同一个节点里面去执行reduce。(reduce个数决定于map的输出)
4.将结果输出到output
Shuffle 过程
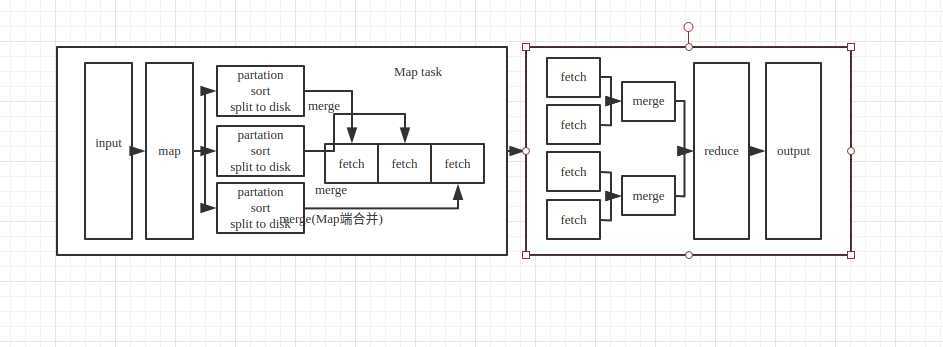
1.Input--map(read in memory )--partation(决定reduce个数)--sort--split to disk---fetch(将一个机器上的map合并成一个文件)
2.fetch(key相同的数据合并成一个文件)--merge --reduce(+1操作)--输出数据
备注:内存缓存区约为100M,缓存区快满的时候(split.percent 0.8约80M)需要有一个线程将数据刷到磁盘,这个过程叫溢写。该线程会对这些数据作排序操作。
c
MR详细流程(Shuffle过程在其中蕴涵)
1.(map--split阶段)将输入文件进行切割操作,最大块(64M)成为一个文件,大于的文件要切成两个。决定map个数
2.(map--map阶段)将文件读取进来,进行自定义的map操作
3.(map--溢写阶段)读文件进内存快满了的时候,进行partation(决定reduce个数)、sort(可以执行Combiner map端聚合数值value成为2或者文件)、split to disk 。
4.(map--merge阶段)将map输出的多个文件进行merge操作。(将value写成一个数组)
5.(reduce--读取数据阶段)将文件读取进来,进行merge操作(value写成一个数组)写到临时文件里面
6.(reduce--reduce阶段)临时文件里面的数据进行自定义reduce操作
MR Helloworld
代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split("");
//将单词输出为<单词,1>for(String word:words){
//相同的单词分发给相同的reduce
context.write(new Text(word),new IntWritable(1));
}
}
}
class WordcountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protectedvoid reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
/*
* key--一组相同单词kv对的key
* */int count =0;
for(IntWritable value:values){
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
publicclass WordcountDriver {
publicstaticvoid main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "file:///");
FileSystem fs= FileSystem.get(conf);
String outputPath = "/software/java/data/output/";
fs.delete(new Path(outputPath),true);
Job job = Job.getInstance(conf);
job.setJarByClass(WordcountDriver.class);
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("/software/java/data/input/"));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
//将job配置的参数,以及job所用的java类所在的jar包提交给yarn去运行
//job.submit();
boolean res = job.waitForCompletion(true);
}
}
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>BigData</artifactId> <version>1.0-SNAPSHOT</version> <inceptionYear>2008</inceptionYear> <properties> <scala.version>2.7.0</scala.version> <hadoop.version>2.7.7</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-app</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-hs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-examples</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> </build> </project>
原文:https://www.cnblogs.com/wuxiaolong4/p/12649836.html
内容总结
以上是互联网集市为您收集整理的Hadoop 系列(一)文件读写过程及MR过程全部内容,希望文章能够帮你解决Hadoop 系列(一)文件读写过程及MR过程所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。